
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
This is a detailed document describing HTTP/2 (RFC 7540), the background, concepts, protocol and something about existing implementations and what the future might hold.
See https://daniel.haxx.se/http2/ for the canonical home for this project.
See https://github.com/bagder/http2-explained for the source code of all book contents.
I encourage and welcome help and contributions from anyone who may have improvements to offer. We accept pull requests, but you can also just file issues or send email to [email protected] with your suggestions!
/ Daniel Stenberg
The http2 protocol mandates that a receiver must read and ignore all unknown frames (those with an unknown frame type). Two parties can negotiate the use of new frame types on a hop-by-hop basis, but those frames aren't allowed to change state and they will not be flow controlled.
The subject of whether http2 should allow extensions at all was debated at length during the protocol's development with opinions swinging for and against. After draft-12 the pendulum swung back one last time and extensions were ultimately allowed.
Extensions are not part of the actual protocol but will be documented outside of the core protocol spec. There are already two frame types that have been discussed for inclusion in the protocol that will probably be the first frames sent as extensions. I'll describe them here because of their popularity and previous state as “native” frames:
With the adoption of http2, there are reasons to suspect that TCP connections will be much lengthier and be kept alive much longer than HTTP 1.x connections have been. A client should be able to do a lot of what it wants with a single connection to each host/site, and that connection could potentially be open for quite some time.
This will affect how HTTP load balancers work and there may arise situations when a site wants to suggest that the client connect to another host. It could be for performance reasons, or if a site is being taken down for maintenance, etc.
The server will send the (or ALTSVC frame with http2) telling the client about an alternative service: another route to the same content, using another service, host, and port number.
A client should then attempt to connect to that service asynchronously and only use the alternative if the new connection succeeds.
The Alt-Svc header allows a server that provides content over http:// to inform the client that the same content is also available over a TLS connection.
This is a somewhat debatable feature. Such a connection would do unauthenticated TLS and wouldn't be advertized as “secure” anywhere, wouldn't use any padlock in the UI, and in fact there is no way to tell the user that it isn't plain old HTTP, but this is still opportunistic TLS and some people are very firmly against this concept.
A frame of this type is meant to be sent exactly once by an http2 party when it has data to send off but flow control forbids it to send any data. The idea is that if your implementation receives this frame you know you have messed up something and/or you're getting less than perfect transfer speeds.
A quote from draft-12, before this frame was moved out to become an extension:
“The BLOCKED frame is included in this draft version to facilitate experimentation. If the results of the experiment do not provide positive feedback, it could be removed”
This document describes http2 from a technical and protocol level. It started out as a presentation Daniel did in Stockholm in April 2014 that was subsequently converted and extended into a full-blown document with all details and proper explanations.
RFC 7540 is the official name of the final http2 specification and it was published on May 15th 2015: https://www.rfc-editor.org/rfc/rfc7540.txt
All and any errors in this document are my own and the results of my shortcomings. Please point them out and they will be fixed in updated versions.
In this document I've tried to consistently use the word "http2" to describe the new protocol while in pure technical terms, the proper name is HTTP/2. I made this choice for the sake of readability and to get a better flow in the language.
My name is Daniel Stenberg. I've been working with open source and networking for over twenty years in numerous projects. Possibly I'm best known for being the lead developer of curl and libcurl. I've been involved in the IETF HTTPbis working group for several years and there I've kept up-to-date with the refreshed HTTP 1.1 work as well as being involved in the http2 standardization work.
Email: [email protected]
Twitter:
Web:
Blog:
If you find mistakes, omissions, errors or blatant lies in this document, please send me a refreshed version of the affected paragraph and I'll make amended versions. I will give proper credits to everyone who helps out! I hope to make this document better over time.
This document is available at
This document is licensed under the Creative Commons Attribution 4.0 license:
The first version of this document was published on April 25th 2014. Here follows the largest changes in the most recent document versions.
Converted the master version of this document to Markdown syntax
13: Mention more resources, updated links and descriptions
12: Updated the QUIC description with reference to draft
8.5: Refreshed with current numbers
1.1: HTTP/2 is now in an official RFC
6.5.1: Link to the HPACK RFC
9.1: Mention the Firefox 36+ config switch for http2
12.1: Added section about QUIC
Lots of language improvements mostly pointed out by friendly contributors
8.3.1: Mention nginx and Apache httpd specific acitivities
1: The protocol has been “okayed”
4.1: Refreshed the wording since 2014 is last year
Front: Added image and call it “http2 explained” there, fixed link
1.4: Added document history section
Updated to HTTP/2 draft-17 and HPACK draft-11
Added section "10. http2 in Chromium" (== one page longer now)
Lots of spell fixes
At 30 implementations now
Firefox has been tracking the drafts very closely and has provided http2 test implementations for many months. During the development of the http2 protocol, clients and servers have to agree on what draft version of the protocol they implement which makes it slightly annoying to run tests. Just be aware so that your client and server agree on what protocol draft they implement.
In all Firefox versions starting with version 36, released Februrary 24th 2015, http2 is enabled by default.
Remember that Firefox only implements http2 over TLS. You will only ever see http2 in action with Firefox when going to https:// sites that offer http2 support.
There is no UI element anywhere that tells that you're talking http2. You just can't tell that easily. One way to figure it out, is to enable “Web developer->Network” and check the response headers and see what you got back from the server. The response is then “HTTP/2.0” something and Firefox inserts its own header called “X-Firefox-Spdy:” as shown in the screenshot above.
The headers you see in the Network tool when talking http2 have been converted from http2's binary format into the old-style HTTP 1.x look-alike headers.
There are Firefox plugins available that help visualize if a site is using http2. One of them is .
If you think this document was a bit light on content or technical details, here are additional resources to help you satisfy your curiosity:
The HTTPbis mailing list and its archives: https://lists.w3.org/Archives/Public/ietf-http-wg/
The actual http2 specification in a HTMLified version: https://httpwg.github.io/specs/rfc7540.html
Firefox http2 networking details: https://wiki.mozilla.org/Networking/http2
curl http2 implementation details:
The http2 web site: and perhaps in particular the FAQ:
Ilya Grigorik's HTTP/2 chapter in his book “High Performance Browser Networking”:
A lot of tough decisions and compromises have been made for http2. With http2 getting deployed there is an established way to upgrade into other protocol versions that work which lays the foundation for doing more protocol revisions ahead. It also brings a notion and an infrastructure that can handle multiple different versions in parallel. Maybe we don't need to phase out the old entirely when we introduce new?
http2 still has a lot of HTTP 1 “legacy” brought with it into the future because of the desire to keep it possible to proxy traffic back and forth between HTTP 1 and http2. Some of that legacy hampers further development and inventions. Perhaps http3 can drop some of them?
What do you think is still lacking in http?
(This chapter was written in 2015, when QUIC was still in its early days. I have decided to leave it like this to give the reader a glimpse of how we viewed the future back then. See the next chapter for the 2022 take.)
Google's (Quick UDP Internet Connections) protocol is an interesting experiment, performed much in the same style and spirit as they did with SPDY. QUIC is a TCP + TLS + HTTP/2 replacement implemented using UDP.
QUIC allows the creation of connections with much less latency, it solves packet loss to only block individual streams instead of all of them like it does for HTTP/2 and it makes creating connections over different network interfaces easy - thus also covering areas MPTCP is meant to solve.
QUIC is so far only implemented by Google in Chrome and their server ends and that code is not easily re-used elsewhere, even if there's a effort trying exactly that. The protocol has been brought as a to the IETF transport working group.
QUIC is no longer an acronym. It is the name of a transport protocol that operates over UDP and is documented in four specifications: RFC 8999 to RFC 9002. Note that what is described in 12.1 above is the original Google QUIC protocol, and what is now made a standard is a different QUIC protocol even though the name has been kept.
HTTP/3 is the new HTTP version in progress. It is designed to work over the QUIC protocol.
For HTTP/3 and QUIC details, see .
HTTP 1.1 has turned into a protocol used for virtually everything on the Internet. Huge investments have been made in protocols and infrastructure that take advantage of this, to the extent that it is often easier today to make things run on top of HTTP rather than building something new on its own.
When HTTP was created and thrown out into the world, it was probably perceived as a rather simple and straightforward protocol, but time has proved that to be false. HTTP 1.0 in RFC 1945 is a 60-page specification released in 1996. RFC 2616 that describes HTTP 1.1 was released only three years later in 1999 and had grown significantly to 176 pages. Yet when we within IETF worked on the update to that spec, it was split up and converted into six documents with a much larger page count in total (resulting in RFC 7230 and family). By any count, HTTP 1.1 is big and includes a myriad of details, subtleties and, not the least, a lot of optional parts.
The Chromium team has implemented http2 and provided support for it in the dev and beta channel for a long time. Starting with Chrome 40, released on January 27th 2015, http2 is enabled by default for a certain amount of users. The amount started off really small and then increased gradually over time.
SPDY support was removed in Chrome 51 in favor of http2. In a blog post, the project announced in :
“Over 25% of resources in Chrome are currently served over HTTP/2, compared to less than 5% over SPDY. Based on such strong adoption, starting on May 15th — the anniversary of the HTTP/2 RFC — Chrome will no longer support SPDY.”
When faced with problems, people tend to gather to find workarounds. Some of the workarounds are clever and useful, but others are just awful kludges.
Spriting is the term often used to describe combining multiple small images to form a single larger image. Then, using JavaScript or CSS, you “cut out” pieces of that big image to show smaller individual ones.
A site would use this trick for speed. Getting a single big image in HTTP 1.1 is much faster than getting 100 smaller individual ones.
If you use a very old Chrome version you may want to check if the support is there.
Enter “chrome://flags/#enable-spdy4" in your browser's address bar and click “enable” if it isn't already showing it as enabled. This flag has been removed in recent version and the support is now always implied.
Remember that Chrome only implements http2 over TLS. You will only ever see http2 in action with Chrome when going to https:// sites that offer http2 support.
There are Chrome plugins available that helps visualize if a site is using HTTP/2. One of them is “HTTP/2 and SPDY Indicator”.
Chrome's current experiments with QUIC (see section 12.1) dilute the HTTP/2 numbers somewhat.
So what does http2 accomplish? Where are the boundaries for what the HTTPbis group set out to do?
The boundaries were actually quite strict and put many restraints on the team's ability to innovate:
http2 has to maintain HTTP paradigms. It is still a protocol where the client sends requests to the server over TCP.
http:// and https:// URLs cannot be changed. There can be no new scheme for this. The amount of content using such URLs is too big to expect them to change.
HTTP1 servers and clients will be around for decades, we need to be able to proxy them to http2 servers.
Subsequently, proxies must be able to map http2 features to HTTP 1.1 clients one-to-one.
Remove or reduce optional parts from the protocol. This wasn't really a requirement but more a mantra coming from SPDY and the Google team. By making sure everything is mandatory there's no way you can not implement anything now and fall into a trap later on.
No more minor version. It was decided that clients and servers are either compatible with http2 or they are not. If a need arises to extend the protocol or modify things, then http3 will be born. There are no more minor versions in http2.
As mentioned already, the existing URI schemes cannot be modified, so http2 must use the existing ones. Since they are used for HTTP 1.x today, we obviously need a way to upgrade the protocol to http2, or otherwise ask the server to use http2 instead of older protocols.
HTTP 1.1 has a defined way to do this, namely the Upgrade: header, which allows the server to send back a response using the new protocol when getting such a request over the old protocol, at the cost of an additional round-trip.
That round-trip penalty was not something the SPDY team would accept, and since they only implemented SPDY over TLS, they developed a new TLS extension which shortcuts the negotiation significantly. Using this extension, called NPN for Next Protocol Negotiation, the server tells the client which protocols it knows and the client can then use the protocol it prefers.
A lot of focus of http2 has been to make it behave properly over TLS. SPDY requires TLS and there's been a strong push for making TLS mandatory for http2, but it didn't get consensus so http2 shipped with TLS as optional. However, two prominent implementers have stated clearly that they will only implement http2 over TLS: the Mozilla Firefox lead and the Google Chrome lead, two of today's leading web browsers.
Reasons for choosing TLS-only include respect for user's privacy and early measurements showing that the new protocols have a higher success rate when done with TLS. This is because of the widespread assumption that anything that goes over port 80 is HTTP 1.1, which makes some middle-boxes interfere with or destroy traffic when any other protocols are used on that port.
The subject of mandatory TLS has caused much hand-wringing and agitated voices in mailing lists and meetings – is it good or is it evil? It is a highly controversial topic – be aware of this when you throw this question in the face of an HTTPbis participant!
Similarly, there's been a fierce and long-running debate about whether http2 should dictate a list of ciphers that should be mandatory when using TLS, or if it should perhaps blacklist a set, or if it shouldn't require anything at all from the TLS “layer” but leave that to the TLS working group. The spec ended up specifying that TLS should be at least version 1.2 and there are cipher suite restrictions.
Next Protocol Negotiation (NPN) is the protocol used to negotiate SPDY with TLS servers. As it wasn't a proper standard, it was taken through the IETF and the result was ALPN: Application Layer Protocol Negotiation. ALPN is being promoted for use by http2, while SPDY clients and servers still use NPN.
The fact that NPN existed first and ALPN has taken a while to go through standardization has led to many early http2 clients and http2 servers implementing and using both these extensions when negotiating http2. Also, NPN is what's used for SPDY and many servers offer both SPDY and http2, so supporting both NPN and ALPN on those servers makes perfect sense.
ALPN differs from NPN primarily in who decides what protocol to speak. With ALPN, the client gives the server a list of protocols in its order of preference and the server picks the one it wants, while with NPN the client makes the final choice.
As previously mentioned, for plain-text HTTP 1.1 the way to negotiate http2 is by presenting the server with an Upgrade: header. If the server speaks http2 it responds with a “101 Switching” status and from then on it speaks http2 on that connection. Of course this upgrade procedure costs a full network round-trip, but the upside is that it's generally possible to keep an http2 connection alive much longer and re-use it more than a typical HTTP1 connection.
While some browsers' spokespersons stated they will not implement this means of speaking http2, the Internet Explorer team once expressed that they would - although they have never delivered on that. curl and a few other non-browser clients support clear-text http2.
Today, no major browser supports http2 without TLS.
3.4: The average is now 40 TCP connections
6.4: Updated to reflect what the spec says
Many spelling and grammar mistakes corrected
14: Added thanks to bug reporters
2.4: Better labels for the HTTP growth graph
6.3: Corrected the wagon order in the multiplexed train
6.5.1: HPACK draft-12
8.5: Added some current usage numbers
8.3: Mention internet explorer too
8.3.1 Added "missing implementations"
8.4.3: Mention that TLS also increases success rate
HTTP 1.1's nature of having lots of tiny details and options available for later extensions has grown a software ecosystem where almost no implementation ever implements everything – and it isn't even really possible to exactly tell what “everything” is. This has led to a situation where features that were initially little-used saw very few implementations, and those that did implement the features then saw very little use of them.
Later on, this caused an interoperability problem when clients and servers started to increase the use of such features. HTTP pipelining is a primary example of such a feature.
HTTP 1.1 has a hard time really taking full advantage of all the power and performance that TCP offers. HTTP clients and browsers have to be very creative to find solutions that decrease page load times.
Other attempts that have been going on in parallel over the years have also confirmed that TCP is not that easy to replace, and thus we keep working on improving both TCP and the protocols on top of it.
Simply put, TCP can be utilized better to avoid pauses or wasted intervals that could have been used to send or receive more data. The following sections will highlight some of these shortcomings.
When looking at the trend for some of the most popular sites on the web today and what it takes to download their front pages, a clear pattern emerges. Over the years, the amount of data that needs to be retrieved has gradually risen up to and above 1.9MB. What is more important in this context is that, on average, over 100 individual resources are required to display each page.
As the graph below shows, the trend has been going on for a while, and there is little to no indication that it will change anytime soon. It shows the growth of the total transfer size (in green) and the total number of requests used on average (in red) to serve the most popular web sites in the world, and how they have changed over the last four years.
HTTP 1.1 is very latency sensitive, partly because HTTP pipelining is still riddled with enough problems to remain switched off to a large percentage of users.
While we've seen a great increase in available bandwidth to people over the last few years, we have not seen the same level of improvements in reducing latency. High-latency links, like many of the current mobile technologies, make it hard to get a good and fast web experience even if you have a really high bandwidth connection.
Another use case requiring low latency is certain kinds of video, like video conferencing, gaming and similar where there's not just a pre-generated stream to send out.
HTTP pipelining is a way to send another request while waiting for the response to a previous request. It is very similar to queuing at a counter at the bank or in a supermarket: you just don't know if the person in front of you is a quick customer or that annoying one that will take forever before he/she is done. This is known as head-of-line blocking.
Sure, you can attempt to pick the line you believe is the correct one, and at times you can even start a new line of your own. But in the end, you can't avoid making a decision. And once it is made, you cannot switch lines.
Creating a new line is also associated with a performance and resource penalty, so that's not scalable beyond a smaller number of lines. There's just no perfect solution to this.
Even today, most desktop web browsers ship with HTTP pipelining disabled by default.
Additional reading on this subject can be found in the Firefox bugzilla entry 264354.
Inlining is another trick used to avoid sending individual images, and this is done by using data URLs embedded in the CSS file. This has similar benefits and drawbacks as the spriting case.
A big site can end up with a lot of different JavaScript files. Developers can use front-end tools to concatenate, or combine, multiple scripts so that the browser will get a single big file instead of dozens of smaller ones. Too much data is sent when only little is needed and, likewise, too much data needs to be reloaded when a change is made.
This practice is, of course, mostly an inconvenience to the developers involved.
The final performance trick I'll mention is often referred to as “sharding.” It basically means serving aspects of your service on as many different hosts as possible. At first glance this seems strange, but there is sound reasoning behind it.
Initially, the HTTP 1.1 specification stated that a client was allowed to use a maximum of two TCP connections for each host. So, in order to not violate the spec, clever sites simply invented new host names and – voilà – you could get more connections to your site and decreased page load times.
Over time that limitation was removed, and today clients easily use six to eight connections per host name. But they still have a limit, so sites continue to use this technique to bump up the number of connections. As the number of objects requested over HTTP is ever-increasing – as I showed before – the large number of connections is then used to make sure HTTP performs well and allow your site to load quickly. It is not unusual for sites to use well over 50 or even up to 100 or more connections now for a single site using this technique. Recent stats from httparchive.org show that the top 300K URLs in the world need, on average, 40(!) TCP connections to display the site, and the trend says this is still increasing slowly over time.
Another reason for sharding is to put images or similar resources on a separate host name that doesn't use any cookies, as the size of cookies these days can be quite significant. By using cookie-free image hosts, you can sometimes increase performance simply by allowing much smaller HTTP requests!
The image below shows what a packet trace looks like when browsing one of Sweden's top web sites and how requests are distributed over several host names.
The curl project has been providing experimental http2 support since September 2013.
In the spirit of curl, we intend to support just about every aspect of http2 that we possibly can. curl is often used as a test tool and tinkerer's way to poke on web sites and we intend to keep that up for http2 as well.
curl uses the separate library nghttp2 for the http2 frame layer functionality. curl requires nghttp2 1.0 or later.
Note that currently on linux curl and libcurl are not always delivered with HTTP/2 protocol support enabled.
Internally, curl will convert incoming http2 headers to HTTP 1.x style headers and provide them to the user, so that they will appear very similar to existing HTTP. This allows for an easier transition for whatever is using curl and HTTP today. Similarly curl will convert outgoing headers in the same style. Give them to curl in HTTP 1.x style and it will convert them on the fly when talking to http2 servers. This also allows users to not have to bother or care very much with which particular HTTP version that is actually used on the wire.
curl supports http2 over standard TCP via the Upgrade: header. If you do an HTTP request and ask for HTTP 2, curl will ask the server to update the connection to http2 if possible.
curl supports a wide range of different TLS libraries for its TLS back-end, and that is still valid for http2 support. The challenge with TLS for http2's sake is the ALPN support and to some extent NPN support.
Build curl against modern versions of OpenSSL or NSS to get both ALPN and NPN support. Using GnuTLS or PolarSSL you will get ALPN support but not NPN.
To tell curl to use http2, either plain text or over TLS, you use the --http2 option (that is “dash dash http2”). curl defaults to HTTP/1.1 for HTTP: URLs so the extra option is necessary when you want http2 for that. For HTTPS URLs, curl will attempt to use http2.
Your application would use https:// or http:// URLs like normal, but you set curl_easy_setopt's CURLOPT_HTTP_VERSION option to CURL_HTTP_VERSION_2 to make libcurl attempt to use http2. It will then do a best effort and do http2 if it can, but otherwise continue to operate with HTTP 1.1.
As libcurl tries to maintain existing behaviors to a far extent, you need to enable HTTP/2 multiplexing for your application with the option. Otherwise it will continue using one request at a time per connection.
Another little detail to keep in mind is that if you ask for several transfers at once with libcurl, using its multi interface, an application can very well start any number of transfers at once and if you then rather have libcurl wait a little to add them all over the same connection rather than opening new connections for all of them at once, you use the option for each individual transfer you rather wait.
libcurl 7.44.0 and later supports HTTP/2 server push. You can take advantage of this feature by setting up a push callback with the option. If the push is accepted by the application, it'll create a new transfer as an CURL easy handle and deliver content on it, just like any other transfer.
Wouldn't it be nice to make an improved protocol? It would...
Be less latency sensitive
Fix pipelining and the head of line blocking problem
Eliminate the need to keep increasing the number of connections to each host
Keep all existing interfaces, all content, the URI formats and schemes
Be made within the IETF's HTTPbis working group
The Internet Engineering Task Force (IETF) is an organization that develops and promotes internet standards, mostly on the protocol level. They're widely known for the RFC series of memos documenting everything from TCP, DNS, and FTP, to best practices, HTTP, and numerous protocol variants that never went anywhere.
Within IETF, dedicated “working groups” are formed with a limited scope to work toward a goal. They establish a “charter” with some set guidelines and limitations for what they should produce. Everyone and anyone is allowed to join in the discussions and development. Everyone who attends and says something has the same weight and chance to affect the outcome and everyone is counted as an individual, with little regard to which company they work for.
The HTTPbis working group (see later for an explanation of the name) was formed during the summer of 2007 and tasked with creating an update of the HTTP 1.1 specification. Within this group the discussions about a next-version HTTP really started during late 2012. The HTTP 1.1 updating work was completed early 2014 and resulted in the series.
The final inter-op meeting for the HTTPbis WG was held in New York City in the beginning of June 2014. The remaining discussions and the IETF procedures performed to actually get the official RFC out continued into the following year.
Some of the bigger players in the HTTP field have been missing from the working group discussions and meetings. I don't want to mention any particular company or product names here, but clearly some actors on the Internet today seem to be confident that IETF will do good without these companies being involved...
The group is named HTTPbis where the "bis" part comes from the . Bis is commonly used as a suffix or part of the name within the IETF for an update or the second take on a spec; in this case, the update to HTTP 1.1.
is a protocol that was developed and spearheaded by Google. They certainly developed it in the open and invited everyone to participate but it was obvious that they benefited by being in control over both a popular browser implementation and a significant server population with well-used services.
When the HTTPbis group decided it was time to start working on http2, SPDY had already proven that it was a working concept. It had shown it was possible to deploy on the Internet and there were published numbers that proved how well it performed. The http2 work began with the SPDY/3 draft that was basically made into the http2 draft-00 with a little search and replace.
Inspiración y la imagen del paquete con formato Lego de Mark Nottingham.
Los datos de tendencias HTTP vienen de .
El gráfico RTT viene de las presentaciones hechas por Mike Belshe.
A mis hijos Agnes y Rex por prestarme sus figuritas Lego para la imagen de “head of line”.
Gracias a los siguientes amigos por las revisiones y el feedback: Kjell Ericson, Bjorn Reese, Linus Swälas and Anthony Bryan. Se aprecia mucho vuestra ayuda que ¡ha mejorado de verdad este documento!
Durante varias iteraciones, las siguientes personas han reportado bugs y sugerido mejoras al documento: Mikael Olsson, Remi Gacogne, Benjamin Kircher, saivlis, florin-andrei-tp, Brett Anthoine, Nick Parlante, Matthew King, Nicolas Peels, Jon Forrest, sbrickey, Marcin Olak, Gary Rowe, Ben Frain, Mats Linander, Raul Siles, Alex Lee, Richard Moore
El traductor a español, Javier Infante, quisiera agradecer a Gorka Gorrotxategi por la revisión y sus correcciones sobre este texto.
.icon1 {
background: url(data:image/png;base64,<data>) no-repeat;
}
.icon2 {
background: url(data:image/png;base64,<data>) no-repeat;
}Inspiration and the package format Lego image from Mark Nottingham.
HTTP trend data comes from https://httparchive.org/.
The RTT graph comes from presentations done by Mike Belshe.
My kids Agnes and Rex for letting me borrow their Lego figures for the head of line picture.
Thanks to the following friends for reviews and feedback: Kjell Ericson, Bjorn Reese, Linus Swälas and Anthony Bryan. Your help is greatly appreciated and has really improved the document!
During the various iterations, the following friendly people have provided bug reports and improvements to the document: Mikael Olsson, Remi Gacogne, Benjamin Kircher, saivlis, florin-andrei-tp, Brett Anthoine, Nick Parlante, Matthew King, Nicolas Peels, Jon Forrest, sbrickey, Marcin Olak, Gary Rowe, Ben Frain, Mats Linander, Raul Siles, Alex Lee, Richard Moore
L'inspiration et l'assemblage Lego : Mark Nottingham
Les tendances HTTP : https://httparchive.org/
Le graphique RTT (Aller-Retour) vient des présentations de Mike Belshe.
Mes enfants Agnès et Rex pour m'avoir prêté leurs Lego.
Merci à mes amis pour les relectures et commentaires : Kjell Ericson, Bjorn Reese, Linus Swalas et Anthony Bryan. Votre aide est appréciée et a réellement amélioré ce document!
Pendant les diverses itérations du document, les personnes suivantes ont fourni ou suggéré des améliorations: Mikael Olsson, Remi Gacogne, Benjamin Kircher, saivlis, florinandrei-tp, Brett Anthoine, Nick Parlante, Matthew King, Nicolas Peels, Jon Forrest, sbrickey, Marcin Olak, Gary Rowe, Ben Frain, Mats Linander, Raul Sile, Alex Lee et Richard Moore.
Le traducteur de cette version française, Olivier Cahagne, souhaite remercier Luc Trudeau, Mehdi Achour, Pascal Borreli et Remi Gacogne pour leurs relectures, nombreuses corrections et suggestions.
(번역되지 않은)
(번역되지 않은)
(번역되지 않은)
Enough about the background, the history and politics behind what got us here. Let's dive into the specifics of the protocol: the bits and the concepts that make up http2.
http2 is a binary protocol.
Just let that sink in for a minute. If you've been involved in internet protocols before, chances are that you will now be instinctively reacting against this choice, marshaling your arguments that spell out how protocols based on text/ascii are superior because humans can handcraft requests over telnet and so on...
http2 is binary to make the framing much easier. Figuring out the start and the end of frames is one of the really complicated things in HTTP 1.1 and, actually, in text-based protocols in general. By moving away from optional white space and different ways to write the same thing, implementation becomes simpler.
Also, it makes it much easier to separate the actual protocol parts from the framing - which in HTTP1 is confusingly intermixed.
The fact that the protocol features compression and will often run over TLS also diminishes the value of text, since you won't see text over the wire anyway. We simply have to get used to the idea of using something like a Wireshark inspector to figure out exactly what's going on at the protocol level in http2.
Debugging this protocol will probably have to be done with tools like curl, or by analyzing the network stream with Wireshark's http2 dissector and similar.
http2 sends binary frames. There are different frame types that can be sent and they all have the same setup: Length, Type, Flags, Stream Identifier, and frame payload.
There are ten different frame types defined in the http2 spec and perhaps the two most fundamental ones that map to HTTP 1.1 features are DATA and HEADERS. I'll describe some of the frames in more detail further on.
The Stream Identifier mentioned in the previous section associates each frame sent over http2 with a “stream”. A stream is an independent, bi-directional sequence of frames exchanged between the client and server within an http2 connection.
A single http2 connection can contain multiple concurrently-open streams, with either endpoint interleaving frames from multiple streams. Streams can be established and used unilaterally or shared by either the client or server and they can be closed by either endpoint. The order in which frames are sent within a stream is significant. Recipients process frames in the order they are received.
Multiplexing the streams means that packages from many streams are mixed over the same connection. Two (or more) individual trains of data are made into a single one and then split up again on the other side. Here are two trains:
The two trains multiplexed over the same connection:
Each stream also has a priority (also known as “weight”), which is used to tell the peer which streams to consider most important, in case there are resource restraints that force the server to select which streams to send first.
Using the PRIORITY frame, a client can also tell the server which other stream this stream depends on. It allows a client to build a priority “tree” where several “child streams” may depend on the completion of “parent streams”.
The priority weights and dependencies can be changed dynamically at run-time, which should enable browsers to make sure that when users scroll down a page full of images, the browser can specify which images are most important, or if you switch tabs it can prioritize a new set of streams that suddenly come into focus.
HTTP is a stateless protocol. In short, this means that every request needs to bring with it as much detail as the server needs to serve that request, without the server having to store a lot of info and meta-data from previous requests. Since http2 doesn't change this paradigm, it has to work the same way.
This makes HTTP repetitive. When a client asks for many resources from the same server, like images from a web page, there will be a large series of requests that all look almost identical. A series of almost identical somethings begs for compression.
While the number of objects per web page has increased (as mentioned earlier), the use of cookies and the size of the requests have also kept growing over time. Cookies also need to be included in all requests, often the same ones in multiple requests.
The HTTP 1.1 request sizes have actually gotten so large that they sometimes end up larger than the initial TCP window, which makes them very slow to send as they need a full round-trip to get an ACK back from the server before the full request has been sent. This is another argument for compression.
HTTPS and SPDY compression were found to be vulnerable to the and attacks. By inserting known text into the stream and figuring out how that changes the output, an attacker can figure out what's being sent in an encrypted payload.
Doing compression on dynamic content for a protocol - without becoming vulnerable to one of these attacks - requires some thought and careful consideration. This is what the HTTPbis team tried to do.
Enter , Header Compression for HTTP/2, which – as the name suggests - is a compression format especially crafted for http2 headers, and it is being specified in a separate internet draft. The new format, together with other counter-measures (such as a bit that asks intermediaries to not compress a specific header and optional padding of frames), should make it harder to exploit compression.
In the words of Roberto Peon (one of the creators of HPACK):
“HPACK was designed to make it difficult for a conforming implementation to leak information, to make encoding and decoding very fast/cheap, to provide for receiver control over compression context size, to allow for proxy re-indexing (i.e., shared state between frontend and backend within a proxy), and for quick comparisons of Huffman-encoded strings”.
One of the drawbacks with HTTP 1.1 is that when an HTTP message has been sent off with a Content-Length of a certain size, you can't easily just stop it. Sure, you can often (but not always) disconnect the TCP connection, but that comes at the cost of having to negotiate a new TCP handshake again.
A better solution would be to just stop the message and start anew. This can be done with http2's RST_STREAM frame which will help prevent wasted bandwidth and the need to tear down connections.
This is the feature also known as “cache push”. The idea is that if the client asks for resource X, the server may know that the client will probably want resource Z as well, and sends it to the client without being asked. It helps the client by putting Z into its cache so that it will be there when it wants it.
Server push is something a client must explicitly allow the server to do. Even then, the client can swiftly terminate a pushed stream at any time with RST_STREAM should it not want a particular resource.
Each individual http2 stream has its own advertised flow window that the other end is allowed to send data for. If you happen to know how SSH works, this is very similar in style and spirit.
For every stream, both ends have to tell the peer that it has enough room to handle incoming data, and the other end is only allowed to send that much data until the window is extended. Only DATA frames are flow controlled.
Firefox a suivi les drafts de près et fourni des protocoles de test de http2 depuis des mois. Pendant le développement du protocole http2, les clients et serveurs devaient s'accorder sur le draft du protocole à utiliser, ce qui compliquait les tests. Soyez juste conscient de vous mettre d'accord sur le draft à utiliser entre client et serveur.
Toute version de Firefox 35 et ultérieure, depuis le 13 janvier 2015, a le support http2 activé par défaut.
Allez dans "about:config" depuis la barre d'URL et cherchez l'option appelée "network.http.spdy.enabled.http2draft". Assurez-vous qu'elle est à "true". Firefox 36 ajouta une option activée par défaut "network.http.spdy.enabled.http2". Cette dernière contrôle la version finale de http2 tandis que la première active ou non la négociation des versions drafts de http2. Les deux sont activées depuis Firefox 36.
Souvenez-vous que Firefox n'implémente http2 que sur TLS. Vous ne verrez du http2 que si vous allez sur les sites https:// qui offrent http2.
Il n'y a pas d'indication graphique que vous utilisez http2. Vous ne pouvez pas le voir facilement. Une manière de le trouver est d'activer "Web developer->Network" et de vérifier l'en-tête de réponse. Elle doit comporter "HTTP/2.0", Firefox insère son propre entête "X-Firefox-Spdy:" comme montré sur la copie d'écran précédente.
Les en-têtes que vous voyez dans l'outil ont été convertis du format binaire http2 vers un format qui ressemble aux en-têtes HTTP 1.x.
Il existe des plug-ins Firefox permettant de visualiser si un site utilise http2. En voici un .
Si vous pensez que ce document était léger en contenu ou détails techniques, voici quelques ressources pour satisfaire votre curiosité:
La mailing-list HTTPbis et ses archives : https://lists.w3.org/Archives/Public/ietf-http-wg/
La spécification http2 au format HTML : https://httpwg.github.io/specs/rfc7540.html
Les aspects réseaux http2 de Firefox : https://wiki.mozilla.org/Networking/http2
Détail d'implémentation http2 dans curl :
Les sites web http2: et en particulier la FAQ :
Le chapitre de Ilya Grigorik sur HTTP/2 dans son livre “High Performance Browser Networking”:
A lot of tough decisions and compromises have been made for http2. With http2 getting deployed there is an established way to upgrade into other protocol versions that work which lays the foundation for doing more protocol revisions ahead. It also brings a notion and an infrastructure that can handle multiple different versions in parallel. Maybe we don't need to phase out the old entirely when we introduce new?
http2 ha a che fare con un sacco di eredità di HTTP 1, per via del fatto che si è voluto poter lasciare aperta la possibilità di proxificare avanti e indietro il traffico HTTP 1 e http2. Parte di questa eredità pone un limite a futuri sviluppi e invenzioni. Magari http3 potrà disfarsi di questa eredità ?
Cosa pensate che possa ancora mancare a http?
Il protocollo di Google (Quick UDP Internet Connections) è un esperimento interessante che si è svolto in linea con lo stesso spirito e stile di SPDY. QUIC è un rimpiazzo per TCP + TLS + HTTP/2 implementato su UDP.
QUIC permette la creazione di connessioni con minor latenza, risolve la perdita di pacchetti bloccando individualmente uno stream piuttosto che tutti insieme come avviene in HTTP/2, olre a rendere possibile un muliplex semplificato su NIC diversi - coprendo quindi aree relative a ciò che MPTCP dovrebbe risolvere.
QUIC è per il momento implementato solo dai server di Google e dal loro browser Chrome; tale codice non è facilmente riutilizzabile altrove, anche se esiste una libreria che cerca di provvedere alla lacuna . Il protocollo è stato presentato al gruppo di lavoro "transport" dela IETF nella draft .
Plusieurs décisions et compromis sont intervenus pour concevoir http2. Avec http2 en cours de déploiement, on a un moyen éprouvé de mise à niveau de version de protocole, qui permettra le développement d'autres révisions de protocoles. Cela montre aussi qu'une même infrastructure peut supporter plusieurs versions de protocole en parallèle. Peut-être pouvons-nous garder l'ancien protocole une fois le nouveau mis en place ?
http2 a pas mal de principes hérités de HTTP 1 pour qu'il soit possible de proxifier du trafic entre HTTP 1 et http2. Certains principes freinent le développement et l'innovation. Peut-être http3 pourra-t-il passer outre ces principes ?
Que pensez-vous qu'il manque à http ?
Le protocole QUIC (Quick UDP Internet Connections) de Google est une expérimentation très intéressante, menée dans le même esprit que SPDY. QUIC est un substitut à TCP + TLS + HTTP/2 implémenté avec UDP.
QUIC permet la création de connexions avec moins de latence, il résout la perte de paquet en ne bloquant qu'un flux particulier au lieu de tous les flux en HTTP/2 et il permet d'établir des connexions à travers différentes interfaces réseau, et du coup, couvre des problématiques que MPTCP résout.
QUIC est pour l'instant uniquement disponible à travers Chrome et les serveurs Google et le code n'est pas facilement réutilisable, même s'il existe une pour ce faire justement. Le protocole a été soumis en tant que à l'IETF transport working group.
Se pensate che questo documento sia ancora troppo poco tecnico, qui troverete altre risorse per soddisfare la vostra curiosità:
La mailing list e gli archivi di HTTPbis: https://lists.w3.org/Archives/Public/ietf-http-wg/
La specifica http2 odierna in una versione HTMLified: https://httpwg.github.io/specs/rfc7540.html
Dettagli sul networking http2 di Firefox http2: https://wiki.mozilla.org/Networking/http2
Dettagli sulla implementazione di http2 in curl:
Il sito di http2: e più in particolare la FAQ:
Il capitolo di Ilya Grigorik's su HTTP/2 nel suo libro “High Performance Browser Networking”:
تیم کرومیوم http2 را پیادهسازی کردهاند و پشتیبانی نیز برای آن ارائه میدهند. از کروم ۴۰ که در ۲۷ ژانویهی ۲۰۱۵ منتشر شد، http2 برای تعداد مشخصی از کاربران فعال شد. این تعداد در ابتدا بسیار کم و بهمرور زمان افزایش یافت.
پشتیبانی SPDY در کروم ۵۱ به خاطر http2 حذف شد. در یک پست بلاگ، این پروژه در فبریهی ۲۰۱۶ اعلام شد:
«بیش از ۲۵٪ منابع در کروم اکنون در بستر HTTP/2 کار میکنند، در مقایسه با کمتر از ۵٪ بر بستر SPDY. بر اساس چنین تأثیری، از ۱۵ می - سالروز انتشار HTTP/2 RFC - کروم دیگر از SPDY پشتیبانی نخواهد کرد.»
عبارت chrome://flags//#enable-spdy4 را در آدرسبار مرورگر خود وارد کنید و بر روی «enable» کلیک کنید، اگر قبلا فعال نشده است.
به یاد داشته باشید که Chrome از http2 تنها در بستر TLS پشتیبانی میکند، یعنی فقط سایتهایی که با https:// شروع میشوند.
افزونههایی برای Chrome وجود دارد که نشان میدهد که سایت از HTTP/2 استفاده میکند یا نه. یکی از آنها است.
آزمایشهای کنونی Chrome با QUIC مقداری آمارهای HTTP/2 را تغییر میدهند. قسمت ۱۲.۱ را برای اطلاعات بیشتر درمورد QUIC ببینید.
این نوشته به زبان سادهتری استاندارد HTTP/2 (RFC 7540), پیشزمینهی آن, مفاهیم, پرتکل، پیادهسازیهای انجامشده و آیندهی آن را توصیف میکند.
صفحهی https://daniel.haxx.se/http2/ را برای توضیحات جامعتر درمورد این پروژه ببینید.
همچنین، برای سورس این کتاب، صفحهی https://github.com/bagder/http2-explained را ببینید.
من از همهی کمکها و مشارکتکنندگان برای بهبود این پروژه استقبال میکنم! ما Pull Request هم قبول میکنیم، اما شما میتوانید برایمان در قسمت issues هم بنویسید یا اصلا به ایمیلم به آدرس [email protected] پیشنهادتان را بفرستید!
/ دنیل استِنبرگ
در این ترجمه سعی کردهام بدون استفاده از واژههای ناملموس و ناآشنا، ترجمهای روان و همهگیر ارائه دهم؛ همچنین در نیز واژهها و اصطلاحات جدیدتر را آوردهام.
این ترجمه، ترجمهای تحتاللفظی نیست که تکتک جملات در نوشتهی اصلی با جملات ترجمهشده یکسان باشند، اما تلاش کردم که مقصود اصلی نویسنده منتقل شود و محتوای نوشتهی اصلی حفظ شود.
قطعا این ترجمه بینقص نیست و جای بهترشدن دارد. خوشحال میشوم که پیشنهادات خودتان را در توئیتر به اکانت یا ایمیل the.black.suited در جیمیل بفرستید.
امیدوارم با خواندن این کتاب، چیزهای جدیدی یاد بگیرید (:
اگر فکر میکنید این نوشته، اطلاعات کافی درمورد موضوع ارائه نمیدهد، میتوانید از لینکهای زیر برای ارضای حس کنجکاو خود استفاده کنید:
لیست ایمیلی HTTPbis و آرشیو ایمیلهای آن: https://lists.w3.org/Archives/Public/ietf-http-wg/
مشخصات http2 در قالب HTML: https://httpwg.github.io/specs/rfc7540.html
جزئیات نحوهکار فایرفاکس با http2: https://wiki.mozilla.org/Networking/http2
جزئيات پیادهسازی http2 توسط curl:
وبسایت http2: و سؤالات متداول مربوط به پرتکل:
فصل HTTP/2 در کتاب “High Performance Browser Networking” ایلیا کریگورک:
HTTP 1.1 se ha convertido en un protocolo usado por prácticamente todo el mundo en Internet. Existen inversiones enormes realizadas en protocolos e infraestructura para aprovecharlo. Esto se ha interpretado cómo que a menudo es más fácil hacer funcionar algo sobre HTTP, que construir algo propiamente nuevo.
Cuando se creó HTTP y fue liberado al mundo, fue concebido como un protocolo más bien simple y sencillo, pero el tiempo ha demostrado lo contrario. HTTP 1.0 en el RFC 1945 es una especificación de 60 páginas publicada en 1996. El RFC 2616 que describe HTTP 1.1, fue publicado sólo tres años más tarde, en 1999 y creció considerablemente hasta las 176 páginas. Todavía, cuando desde el EIETF trabajamos en la actualización de la especificación que fue separada en seis documentos, con un número mucho mayor de páginas en total (resultando en el RFC 7230 y familia). De cualquier modo, HTTP 1.1 es grande e incluye una gran variedad de detalles y sutilezas, sin olvidar una gran cantidad de importantes piezas opcionales.
بهتر نیست که یک پرتکل بهتر بسازیم؟ پرتکلی که...
به تأخیرها کمتر حساس باشه
مشکل HTTP Pipelining رو و Head-of-line blocking رو حل کنه
نیازی به افزایش تعداد Host name نداشته باشه
Le a fourni un support http2 expérimental depuis septembre 2013.
Dans l'esprit curl, nous voulons supporter toutes les fonctionnalités http2 possibles. curl est souvent utilisé comme outil de test et nous voulons que ce soit le cas pour http2 également.
curl utilise une librairie distincte pour la couche http2. curl requiert nghttp2 1.0 ou plus.
Notez qu'actuellement, sous linux, curl et libcurl ne sont pas toujours délivrés avec le support du protocole HTTP/2 activé.
وقتی ما با مشکلات مواجه میشویم، گرد هم میآییم تا برای آنها راهحلهایی پیدا کنیم. بعضی از این راهحلها کاربردی و هوشمندانه هستند، و بعضی دیگر فقط باعث درستشدن موانع بیشتر میشوند.
Spriting روشی است که چندین عکس کوچکتر را در قالب یک عکس بزرگ جا میدهند. سپس، با جاوا اسکریپت یا CSS، میتوانید عکسهای کوچکتر را از این عکس بزرگ ببرید و آنها را نمایش دهید.
وبسایتها از این روش برای افزایش سرعت استفاده میکنند. دانلود یک عکس بزرگ از طریق HTTP 1.1، بسیار سریعتر از دریافت ۱۰۰ عکس کوچکتر است.
پرتکل http2 فرض میکند که گیرنده باید همهی فریمهای ناشناخته را بخواند و نادیده بگیرد (فریمهایی که نوع ناشناختهای دارند). دو طرف میتوانند نوع فریمهای جدیدی را تعیین کنند، اما این فریمها نمیتوانند وضعیت خود را تغییر دهند و جریان آنها کنترل نمیشوند.
موضوع این که آیا http2 اجازهی افزونهها را بدهد یا نه، در طول توسعهی پرتکل سر آن بحثهای زیادی انجام گرفت که توسعهدهندگان نظر خود را مرتبا عوض میکردند. بعد از پیشنویس ۱۲، در نهایت افزونهها در http2 مجاز شدند.
افزونهها جزئی از خود پرتکل نیستند و مستندات آنها در خارج از هستهی استانداردهای پرتکل قرار دارند. قبلا دو نوع فریم در پرتکل به عنوان افزونهها تعریف شده. آنها را اینجا به دلیل محبوبیت و اینکه قبلا جزئی از پرتکل بودند، توضیح میدهم.
با ورود http2، کانکشنهای TCP میتوانند به هر دلیلی، حجیمتر شوند و مدت برقراری آنها نسبت به کانکشنهای HTTP 1.x افزایش یابند. یک کلاینت باید بتواند این مشخصهها را در یک کانکشن افزایش دهد، و این کانکشن میتواند برای مدت نسبتا زیادی برقرار باشد.
Ceci est un document détaillé décrivant HTTP/2 (), les prémices, concepts, protocole, les implémentations existantes et ce que le futur pourrait nous réserver.
Référez-vous à pour tout ce qui concerne ce projet.
Référez-vous à pour le code source de ce livre.
J'encourage et apprécie l'aide et les contributions de chaque personne qui désire apporter des améliorations. Nous acceptons les , mais vous pouvez également simplement créer un ou encore envoyer un courriel à [email protected] avec vos suggestions!
این نوشته http2 را از یک نگرش تکنیکی و پرتکلی توصیف میکند. نوشتن آن، زمانی که آغاز شد که دنیل آن را به صورت یک ارائه در استکهلم در آپریل ۲۰۱۴ عرضه کرد که پس از آن، گسترش یافت و با توضیحات بیشتری به یک نوشته با جزئیات بیشتر تبدیل شد.
RFC 7540 نام رسمی مشخصات نهایی http2 است که در پانزدهم می ۲۰۱۵ منتشر شد:
تمامی خطاها در این نوشته، حاصل قصور من [یا مترجم] است. لطفا اگر خطایی دیدید، به من اطلاع دهید تا در نسخههای بعدی آنها را رفع کنم.
در این نوشته، به طور ثابت از واژهی http2 برای خطاب این پرتکل جدید استفاده کردهام، در حالی که از نظر فنی، نام صحیح آن HTTP/2 میباشد. من این تصمیم را برای بهبود خوانایی نوشته و تطابق آن با زبان گرفتهام.
この文書の内容または技術的詳細が薄いと考えるなら、あなたの好奇心を満足させる参考文献をここに紹介します:
HTTPbisメーリングリストとアーカイブ:
HTML化されたhttp2仕様書:
Firefoxのhttp2ネットワーキングに関する詳細:
L'équipe Chromium a implémenté http2 depuis un certain temps via les canaux beta et dev. Depuis Chrome 40, sorti le 27 janvier 2015, http2 est activé par défaut pour un certain nombre d'utilisateurs. Ce nombre a commencé petit pour devenir important au fil du temps.
Le support SPDY sera retiré. Dans un blog, il est annoncé en :
“Chrome supporte SPDY depuis Chrome 6, mais comme les bénéfices sont présents dans HTTP/2, il est temps de lui dire au revoir. Le support SPDY sera retiré début 2016.”
Este es un documento detallado que describe HTTP/2 (), sus antecedentes, conceptos, el protocolo y algo sobre las implementaciones existentes y lo que nos puede deparar el futuro.
El sitio es el home canónico de este proyecto.
En se encuentra el código fuente de todo el contenido del libro.
Se alienta y da la bienvenida a cualquier ayuda o contribución de cualquiera que quiera ofrecer mejoras. Aceptamos , aunque también puedes rellenar o enviar un correo a [email protected] con tus sugerencias.
発想とパッケージのフォーマットのレゴ画像は、Mark Nottingham氏から。
HTTPトレンドデータは から。
RTTのグラフはMike Belshe氏のプレゼンテーションから。
ヘッドオブラインの絵を作成するためにレゴのおもちゃを私に貸してくれた私の子供たちAgnesとRexに。
レビューとフィードバックをくれた友人たちに: Kjell Ericson、Bjorn Reese、Linus Swälas and Anthony Bryanに。あなたの助けには非常に感謝しています。お陰で文書がすばらしくよくなりました。
執筆中にいろいろな段階で、バグレポートや文書の改善に協力してくれた友人たちに: Mikael Olsson、Remi Gacogne、Benjamin Kircher、saivlis、florin-andrei-tp、Brett Anthoine、Nick Parlante、Matthew King、Nicolas Peels、Jon Forrest、sbrickey、Marcin Olak、Gary Rowe、Ben Frain、Mats Linander、Raul Siles、Alex Lee、Richard Moore
Firefox ha estado siguiendo la pista a los borradores muy de cerca, y ofreciendo implementaciones http2 de prueba durante muchos meses. Durante el desarrollo del protocolo http2, los clientes y servidores tienen que ponerse de acuerdo sobre que versión del borrados están utilizando, lo cual dificulta levemente ejecutar pruebas. Hay que asegurarse de que el cliente y el servidor implementan la misma versión del borrador del protocolo.
Desde la versión 35, publicada el 13 de enero de 2015, Firefox soporta http2 por defecto.
Entrar en 'about:config' en la barra de direcciones, y buscar la opción denominada “network.http.spdy.enabled.http2draft”. Habrá que asegurarse qu está puesta a true. Firefox 36 añadió otra opción de configuración llamada “network.http.spdy.enabled.http2” que está a true por defecto. Ésta última controla la versión simple de http2, mientras que la primera activa y desactiva la negociación de la revisiones de los borradores de http2. Ambas opciones están actividad desde Firefox 36.
فایرفاکس، پیشنویسهای مربوط به http2 را از نزدیک دنبال میکرده و تستهای مربوط به پیادهسازیها را ماهها قبل ارائه داده است. در هنگام توسعهی http2، کلاینتها و سرورها باید بر یک نسخهی پیشنویس توافق میکردند که اجرای آزمایشها را مقداری آزاردهنده میکرد. آگاه باشید که کلاینت و سرور بر روی کدام پیشنویس پرتکل پیادهسازیشده توافق میکنند.
در فایرفاکس ۳۵ و بالاتر که در ۱۳ ژانویهی ۲۰۱۵ منتشر شد، پشتیبانی از http2 به طور پیشفرض فعال است.
در آدرسبار مرورگر عبارت about:config را وارد کنید و به دنبال گزینهای به نام network.http.spdy.enabled.http2draft
Chromiumチームはhttp2を実装していて、長い間dev、betaチャンネルでそのサポートを行っています。2015年1月27日にリリースされたChrome 40から、一部のユーザーにおいてhttp2がデフォルトで有効になりました。その数は最初は少なく設定されていましたが、時とともに徐々に増加しました。
SPDYサポートは削除される予定です。のブログでの発表によると:
”ChromeはSPDYをChrome 6からサポートしてきました。しかしそのほとんどの恩恵はHTTP/2からも得られることから、さようならをすることに決めました。SPDYを2016年の早い時期に削除する予定です。”
ブラウザーのアドレスバーに”chrome://flags/#enable-spdy4”と入力し、まだ有効になっていない場合は、”enable”をクリックします。
多くの困難な決断と妥協がhttp2ではなされました。http2がデプロイされれば、次のプロトコルリビジョンへのアップグレードのための基礎になります。また異なる複数のバージョンを同時に処理できる概念やインフラストラクチャーをもたらします。おそらく新しいものを導入するときに古いものをすべて捨て去る必要がなくなることでしょう。
http2は、HTTP 1とhttp2間の通信をプロキシーできるようにしたいという願望のためHTTP 1の”遺産”の多くを引き継いでいます。遺産の中のいくつかはさらなる発展や発明を妨げます。もしかするとHTTP 3ではそれらを捨て去ることになるかもしれませんね。
あなたがHTTPで足りないと思っていることはありますか?
Googleの(Quick UDP Internet Connections)は興味深い実験です。それはSPDYのときと同じようなスタイルと精神で行われています。QUICはTCP + TLS + HTTP/2の代替品でありUDPを使って実装されます。
Se han tomado muchas decisiones duras y compromisos en http2. Con el despliegue de http2 por delante, se ha determinado una forma para actualizar a otras versiones, que sienta las bases para tener nuevas revisiones del protocolo más adelante. Se ha introducido el concepto y la infraestructura necesarias para manejar múltiples versiones en paralelo. ¿Quizás no es necesario descontinuar completamente lo viejo para introducir algo nuevo?
http2 lleva al futuro un montón de “legado” HTTP 1 con la intención de mantener posible tráfico de proxy de ida y vuelta entre HTTP 1 y http2. Parte de ese legado dificulta aún más el desarrollo y la inventiva. ¿Quizás http3 se deshará de parte de este legado?
¿Qué crees que falta todavía en http?
Mark Nottingham per l'ispirazione e l'immagine formato Lego dei pacchetti.
I dati sui trend HTTP provenienti da .
I grafici RTT provengono dalle presentazioni di Mike Belshe.
I miei figli Agnes e Rex per avermi prestato i loro personaggi Lego per l'immagine "inizio della fila".
Grazie agli amici per riletture e ritorni: Kjell Ericson, Bjorn Reese, Linus Swälas e Anthony Bryan. Il vostro aiuto è immensamente apprezzato e ha davvero migliorato questo documento!
Nel corso delle varie iterazioni, le persone seguenti hanno amicalmente inviato bug-report e migliorie a questo documento: Mikael Olsson, Remi Gacogne, Benjamin Kircher, saivlis, florin-andrei-tp, Brett Anthoine, Nick Parlante, Matthew King, Nicolas Peels, Jon Forrest, sbrickey, Marcin Olak, Gary Rowe, Ben Frain, Mats Linander, Raul Siles, Alex Lee, Richard Moore
この文書はHTTP/2()、その背景、コンセプト、プロトコル、既存の実装および未来がどうなるかを記述したものです。
このプロジェクトのサイトは を見てください。
文書の全ソースコードは を見てください。
改善案をお持ちの方はだれでも大歓迎です。私達はを受け付けていますが、[email protected] まで改善案をメールで送って頂いても結構です。
/ Daniel Stenberg
Il team di Chromium ha implementato http2 e ha anche fornito supporto sui canali dev e beta per lungo tempo. A partire da Chrome 40, rilasciato il 27 Gennaio 2015, http2 è abilitato per default per un determinato numero di utenti. Hanno iniziato supportando una utenza ristretta per poi aumentare gradualmente nel tempo.
Il supporto nativo per SPDY verrà eventualmente eliminato. Il progetto ha comunicato tale notizia in un post :
“Chrome ha supportato SPDY a partire dalla versione 6, ma dato che la maggior parte dei benefici sono presenti anche in HTTP/2, è tempo di dirsi addio. Pianifichiamo di rimuovere il supporto per SPDY ad inizio 2016”
Le protocole oblige le destinataire à lire et ignorer toutes les trames inconnues utilisant un type de trame inconnu. Les deux parties peuvent ainsi négocier l'utilisation d'un nouveau type de trame de manière unitaire; ces trames ne seront pas autorisées à changer d'état et ne bénéficieront pas de contrôle de flux.
Le fait d'autoriser ou non les extensions dans http2 a été débattu pendant le développement du protocole avec des opinions pour et contre. Depuis le draft-12, la balance a penché en faveur du pour: les extensions sont autorisées.
Les extensions ne font pas partie du protocole actuel mais seront documentées en dehors de la spécification principale. En l'état, il existe deux types de trames qui pouvaient faire partie du protocole et qui seront probablement les premières trames définies comme extensions. Je les décris ici car elles sont populaires et étaient considérées auparavant comme des trames "natives":
از همین تعاملها، محتوا و ساختارهای URI پشتیبانی کنه
و توسط کارگروه HTTPbis در IETF ساخته شده باشه!
IETF یک سازمان برای توسعه و ترویج استانداردهای اینترنت در سطح پرتکل است. این سازمان بیشتر به خاطر سری استانداردهای RFC شامل TCP، DNS، FTP و از همه بهتر HTTP و یکسری پرتکلهای دیگر که هیچجا شناخته نشدهاند، مشهور است.
در IETF، کارگروههای اختصاصی با اختیارات محدود برای رسیدن به یک هدف مشخص کار میکنند. آنها یک منشور مشخص میکنند تا خطمشیها و محدودیتها برای چیزی که تولید میکنند را مشخص کنند. همهی افراد اجازهی مشارکت در بحث و توسعه را دارند. هر کسی که شرکت میکند و چیزی میگوید، گفتهی او، اهمیت یکسانی نسبت به گفتههای دیگران دارد و هر کسی به عنوان یک فرد مستقل شناخته میشود، بدون درنظرگرفتن شرکتی که او در آنجا کار میکند.
کارگروه HTTPbis در تابستان ۲۰۰۷ شکل گرفت و وظیفه دارد تا استانداردهای HTTP را آپدیت کند. در این گروه، بحث درمورد نسخهی بعدی HTTP در اواخر سال ۲۰۱۲ شکل گرفت. کار آپدیت HTTP 1.1 در اوایل ۲۰۱۴ تمام شد که نتیجهی آن را در سری RFC 7230 میبینید.
آخرین نشست فنی کارگروه HTTPbis در ژوئن ۲۰۱۴ در شهر نیویورک برگزار شد. بحثهای باقیمانده و روند رسمی IETF انجام شدند تا این استاندارد RFC به طور رسمی سال بعد عرضه شود.
بازیگران بزرگتر در عرصهی HTTP در جلسات و گفتگوهای این کارگروه غایب بودند. نمیخواهم نام هیچ شرکت یا محصول خاصی را ببرم، اما واضح است که بعضی از بازیگران اصلی اینترنت امروز، مطمئن هستند که IETF بدون آنها هم عملکرد خوبی خواهد داشت...
نام گروه HTTPbis است که پسوند bis از در لاتین به معنای دو است. پسوند Bis معمولا در IETF برای هر آپدیت یا نسخهی دوم هر چیزی استفاده میشود؛ مثلا همین بهروزرسانی HTTP 1.1.
SPDY یک پرتکل است که توسط گوگل توسعه داده و توزیع شد. آنها، این پرتکل را در یک محیط باز توسعه دادند و از همگان دعوت کردند که شرکت کنند ولی روشن است که آنها با کنترلکردن پیادهسازی یک مرورگر پرطرفدار و همچنین سرورهای پرجمعیتی که از سرویسها استفاده میکردند، سود میبردند.
هنگامی که گروه HTTPbis تمصمیم گرفت که روی http2 کار کند، SPDY قبلا ثابت کرده بود که یک طرح عملی است. SPDY نشان داده بود که استفاده از آن در اینترنت ممکن است و آماری هم وجود دارد که تا چه حد خوب کار میکند. کار http2 با پیشنویس SPDY/3 شروع شد که به سادگی، تبدیل به پیشنویس صفر (draft-00) HTTP2 با کمی تغییر شد.
این موضوع روی چگونگی کار Load Balancerهای HTTP تأثیر میگذارد و ممکن است موجب شرایطی شود که یک سایت به کلاینت پیشنهاد دهد که به یک سرور دیگر متصل شود. ممکن است دلیل این کار، افزایش سرعت و کارایی باشد، یا سرور تحت تعمیر باشد و سرور دیگری دردسترس باشد و غیره.
سرور میتواند هدر Alt-Svc (یا فریم ALTSVC) را به کلاینت بفرستد که سرویس دیگری موجود است: یک مسیر دیگر به همان محتوا، در یک سرور دیگر، میزبان دیگر و پورت دیگر.
کلاینت باید به آن سرویس دیگر به طور ناهمگام وصل شود و فقط در صورتی از جایگزین استفاده کند که کانکشن جدید موفق باشد.
هدر Alt-Svc به سرور اجازه میدهد که محتوا را بر پرتکل http:// ارائه دهد تا به کلاینت اطلاع دهد که همان محتوا روی یک کانکشن امن TLS هم دردسترس هستند.
این قابلیت کمی شکبرانگیز است. این نوع کانکشن میتواند TLS احرازنشده انجام دهد و دیگر نتواند امن معرفی شود، هیچ علامت قفلی در UI نشان داده میشود و در واقع هیچ راهی وجود ندارد که به کاربر بگوییم که این همان HTTP ساده و قدیمی است، ولی همچنان این TLS فرصتگراست و بعضی از افراد شدیدا مخالف این مفهوم هستند.
این نوع فریم وقتی ارسال میشود که یکی از طرفین کانکشن http2 دادهای را ارسال میکند، اما کنترل جریان اجازهی ارسال را نمیدهد. ایده این است که اگر کلاینت یا سرور این فریم را دریافت کند، شما میدانید که یک جای کار مشکل دارد و یا سرعت انتقال کمتر است.
متن زیر قسمتی از پیشنویس ۱۲ است، قبل از این که این نوع فریم، افزونه شود.
«فریم BLOCKED در این پیشنویس گنجانده شده تا آزمایشها را تسهیل کند. اگر نتایج آزمایشها، بازخورد مثبتی نداشته باشد، ممکن است حذف شود.»
ترجمهی مفهومی آن: «مسدودسازی توسط نفر اول یک صف». متأسفانه هیچ ترجمهی دیگری برای این اصطلاح پیدا نکردم.
به نامهایی که به هر میزبان اختصاص میدهند گفته میشود. مثلا localhost، google.com، wikipedia.org و m.wikipedia.org هر کدام یک Host name مستقل هستند.
Cookies به دادههای کوچکی گفته میشود که در مرورگرها به درخواست سرور ذخیره میشوند و در هر درخواست، همراه با اطلاعات دیگر به سرور فرستاده میشوند.
Internet Enginnering Task Force نیروی کار مهندسی اینترنت
Transport Layer Security یکی از پروتکلهای رمزنگاری است و برای تأمین امنیت ارتباطات از طریق اینترنت بنا شدهاست.
Next Protocol Negotiation ارتباط اولیهی پرتکول بعدی
Application Layer Protocol Negotiation ارتباطاولیهی لایهی کاربری پرتکول
Avec http2 adopté, on peut suspecter que les connexions TCP seront plus longues (en temps) et maintenues actives plus longtemps que les connexions HTTP 1.x. Un client doit donc pouvoir se débrouiller avec une seule connexion par hôte/site et cette connexion pourrait rester ouverte pendant un certain temps.
Cela affectera comment les load balancers HTTP réagissent quand un site voudra que les utilisateurs se connectent sur un autre host, pour des raisons de performance ou pour réaliser une maintenance.
Le serveur enverra alors l'en-tête Alt-Svc: (ou la trame http2 ALTSVC) pour indiquer au client un service alternatif. Une autre route pour le même contenu, utilisant un autre service, host et numéro de port.
Un client est alors susceptible d'essayer de se connecter à ce service de manière asynchrone et n'utiliser que celui-ci s'il fonctionne.
L'en-tête Alt-Svc permet à un serveur servant du contenu en http:// d'informer le client que le même contenu est aussi disponible en TLS.
Cette fonctionnalité est débattue. Cette connexion serait du TLS non authentifié et ne serait pas affichée comme "sécurisée", n'utiliserait pas de cadenas dans l'interface graphique du navigateur même si ce n'est pas du simple HTTP. Plusieurs personnes sont contre.
Ce type de trame doit être envoyée une seule fois par un client http2 quand des données doivent être envoyées alors que le contrôle de flux l'interdit. L'idée est que si votre implémentation reçoit une telle trame, cela vous indique que quelque chose cloche dans votre implémentation et que vous avez une performance suboptimale.
Une citation du draft-12, avant que cette trame ne soit retirée pour devenir une extension:
“La trame BLOCKED est incluse dans ce draft pour en faciliter son expérimentation. Si les resultats de cette expérimentation ne donnent pas de feedback positif, elle pourra être retirée”
curl supporte http2 sur TCP via l'en-tête Upgrade:. Si vous initiez une requête HTTP en demandant HTTP 2, curl demandera au serveur de mettre à niveau (Upgrader) sa connexion en http2.
curl supporte différentes librairies TLS et c'est toujours valide pour http2. La difficulté avec TLS et http2 est le support de ALPN et potentiellement NPN.
Compilez curl avec des versions récentes d'OpenSSL ou NSS pour avoir ALPN et NPN. Avec GnuTLS et PolarSSL vous n'aurez que ALPN et pas NPN.
Pour indiquer à curl d'utiliser http2, en clair ou TLS, utilisez l'option --http2 ("tiret tiret http2"). curl utilise HTTP/1.1 par défaut, d'où cette option nécessaire pour http2.
Votre application utilisera http:// ou https:// comme d'habitude, mais vous pouvez régler la variable curl_easy_setopt de CURLOPT_HTTP_VERSION vers CURL_HTTP_VERSION_2 pour que libcurl tente d'utiliser http2. Il le fera en best effort sinon utilisera HTTP 1.1.
Etant donné que libcurl essaye de maintenir ses anciens comportements dans la mesure du possible, vous devez activer le multiplexage HTTP/2 pour votre application via l'option CURLMOPT_PIPELINING. Sinon elle continuera à utiliser une requête à la fois par connexion.
Un autre détail à garder à l'esprit et que si vous demandez plusieurs transferts en simultanés à libcurl, en utilisant son interface multi, une application peut très bien commencer autant de transfert que voulu, et que si vous préférez que libcurl attende un peu pour les placer tous sur la même connexion, plutôt que d'ouvrir une connexion pour chacun, utilisez l'option CURLOPT_PIPEWAIT pour chaque transfert que vous préférez attendre.
libcurl 7.44.0 et plus supporte le server push de HTTP/2. Vous pouvez tirez des avantages de cette fonctionnalité en configurant un callback de push avec l'option CURLMOPT_PUSHFUNCTION. Si le push est accepté par l'application, il créera un nouveau transfert en tant que CURL easy handle et l'utilisera pour délivrer le contenu, comme tout autre transfert.
/ Daniel Stenberg
curlのhttp2実装に関する詳細: https://curl.haxx.se/docs/http2.html
http2 webサイト: https://http2.github.io/ and perhaps in particular the FAQ: https://http2.github.io/faq/
Ilya Grigorikの著書”High Performance Browser Networking”のHTTP/2の章: https://hpbn.co/http2/
Souvenez-vous que Chrome n'implémente http2 que sur TLS. Vous ne verrez du http2 que si vous allez sur les sites https:// qui offrent http2.
Il existe des plug-ins Chrome permettant de visualiser si un site utilise http2. En voici un: “SPDY Indicator”.
Les tests QUIC en cours masquent un peu les résultats HTTP/2. (voir chapitre 12.1)
/ Daniel Stenberg
개선 사항을 가지고 계신분은 누구나 환영합니다. 우리는 pull requests 를 받고 있지만, [email protected] 로 여러분의 제안을 메일로 보내주셔도 괜찮습니다
/ Daniel Stenberg
Chromeはhttp2をTLS上でのみ実装することを忘れないでください。Chromeではhttps://のhttp2をサポートするサイトでのみhttp2は動作します。
サイトがhttp2を使用しているかどうかの可視化を手伝いするChromeプラグインがあります。それらの一つは”HTTP/2 and SPDY Indicator”です。
現在行われているChromeによるQUIC(12.1を参照)の試験が、HTTP/2の使用率を幾分下げています。
QUICは現時点ではGoogleによってChromeとGoogleサーバーにだけ実装されています。コードは簡単に再利用できる形にはなっていません。libquicというプロジェクトがそれを実現しようとしています。プロトコルはドラフトとしてIETFトランスポートワーキンググループへ提出されました。
Digitare “chrome://flags/#enable-spdy4" nella barra indirizzi e cliccare su “enable” se non fosse gia abilitato.
Ricordate che Chrome implementa http2 solo attraverso TLS. Vedrete http2 in azione solamente quando Chrome verrà utilizzato su un sito https:// che offra supporto nativo http2.
Sono disponibili plugin per Chrome che aiutano a visualizzare se un sito stia utilizzando HTTP/2. Uno di questi è “HTTP/2 and SPDY Indicator”.
Gli attuali esperimenti di Chrome e l'impiego di QUIC (vedi sezione 12.1) fanno sì che il numero di connessioni HTTP/2 sia in diminuzione.
http2 چه فایدهای دارد؟ مرزهای تعیینشده برای کارگروه HTTPbis چه هستند؟
این مرزها در واقع بسیار محدود بودند و اختیارات کمی به گروه برای نوآوری میدادند:
http2 باید از پارادایمهای HTTP پشتیبانی کند. یعنی همچنان پرتکلی است که کلاینت از طریق TCP به سرور درخواستی میفرستند.
پیشوندهای http:// و https:// نباید تغییر کنند. هیچ پیشوند تازهای نمیتوان ایجاد کرد. محتوایی که تحت این پیشوندها دردسترس هستند، بیشتر از آن هستند که بتوان تغییرشان داد.
سرورها و کلاینتهای HTTP1 تا دههها وجود خواهند داشت، پس باید بتوان آنها را با سرورهای http2 پراکسی کرد.
تبعا، پراکسیها باید بتوانند قابلیتهای http2 را به کلاینتهای HTTP 1.1، یکبهیک مربوط کنند.
حذف یا کاهش قسمتهای اختیاری پرتکل. این کار واقعا لازم نبود، در واقع یک حرکت بود که از گوگل و SPDY شروع شد. وقتی مطمئن باشیم که همهچیز ضروری هستند، میتوانید بدون اینکه چیزی جا بیندازید، آن را پیادهسازی کنید که بعدا گرفتار نشوید.
نسخههای جزئی نداشته باشیم. ما تصمیم گرفتیم که کلاینتها یا سرورها یا با http2 سازگارند یا نیستند. اگر نیاز به توسعهی پرتکل وجود داشت، نسخهی بعدی، http3 خواهد بود. هیچ نسخهی جزئی (Minor) در http2 نخواهیم داشت.
همانطور که قبلا هم اشاره شد، پیشوندها و ساختارهای کنونی URI را نمیتوان تغییر داد، پس http2 باید از آنهایی که الان هستند استفاده کند. از آنجایی آنها در HTTP 1.x استفاده میشوند، به یک راه نیاز داریم که پرتکل را به http2 ارتقا دهیم یا از سرور بخواهیم که از http2 به جای پرتکلهای قدیمی استفاده کند.
HTTP 1.1 قبلا یک راه برای این منظور تعریف کرده: استفاده از هدر Upgrade: که به سرور اجازه میدهد که پاسخ درخواست را با پرتکل جدید بدهد، که هزینهی این کار، پذیرش دو درخواست به جای یکی است.
این دوبرابر شدن درخواستها، چیزی نبود که تیم SPDY بتواند قبول کند، و از آنجایی که آنها SPDY را تنها بر روی TLS پیاده کرده بودند، یک افزونه برای TLS توسعه دادند که ارتباط اولیه (Negotiation) را به طور چشمگیری سریعتر و کوتاهتر میکرد. با این افزونه، که NPN نام دارد، سرور به کلاینت اطلاع می دهد که چه پرتکلهایی را میشناسد و کلاینت میتواند از پرتکلی که ترجیح میدهد استفاده کند.
تلاشهای زیادی انجام شده که http2 بر TLS به درستی رفتار کند. SPDY به TLS نیاز دارد و این تصمیم مهمی بود که TLS را برای الزامی کنیم، ولی به یک نتیجهی جمعی نرسیدیم، بنابراین http2 با TLS به صورت اختیاری منتشر شد. با این حال، دو پیادهسازی برجسته اعلام کردند که http2 تنها از طریق TLS دردسترس خواهد بود: فایرفاکس از موزیلا و کروم از گوگل، دو مرورگر پیشروی امروز.
دلایل اجباریکردن TLS، احترام به حریمخصوصی کاربر است، همچنین آزمایشهای اولیه نشان داد که پرتکلهای جدید، میزان موفقیت بیشتری دارند، اگر بر مبنای TLS باشند. این به اینخاطر است که معمولا فرض بر این گذاشته میشود که ترافیکی که از پورت ۸۰ عبور میکند، با پرتکل HTTP 1.1 کار میکند. وقتی پرتکلهای دیگری از این پورت استفاده میکنند، بعضی از واسطهها (مثلا آنتیویروسها) ممکن است اختلال ایجاد کنند یا حتی دادههای رسیده را از بین ببرند.
موضوع اجباریشدن TLS مناقاشات زیادی را در لیستهای ایمیل و دیدارها بهوجود آورد - آیا این کار درست است یا غلط؟ موضوعی که بسیار جدالآمیز است - مواظب باشید که آن را ناگهانی از یکی از اعضای کارگروه HTTPbis نپرسید!
به طور مشابه، بحثی هم درمورد این وجود داشته که آیا http2 باید لیستی از روشهای رمزنگاری را برای TLS اجباری کند، یا لیستسیاهی از این الگوریتمها درست کند، یا شاید هیچکاری به لایهی TLS نداشته باشد و اجازه دهد که کارگروه TLS کار خودشان را انجام دهند. نتیجه آن شد که استاندارد تعیین کرد که نسخهی TLS باید حداقل ۱.۲ باشد و همچنین در انتخاب روشهای رمزنگاری (Cipher Suite) نیز محدودیتهایی وجود دارد.
NPN پرتکلی بود که SPDY برای مذاکره یا همان ارتباط اولیه با سرورهای TLS استفاده میکرد. از آنجایی که این پرتکل استاندارد نبود، NPN از IETF گذشت و نتیجه شد: ALPN. ALPN در حالحاضر برای http2 استفاده میشود، در حالی که کلاینتها و سرورهای SPDY هنوز از NPN استفاده میکنند.
در حقیقت، NPN اول وجود داشته و در زمانی که ALPN در فرآیند استانداردسازی قرار داشته، کلاینتها و سرورهای http2 بسیاری بهوجودآمدند که از هردوی آنها پشتیبانی میکردند. همچنین، از NPN در SPDY استفاده میشود و سرورهای بسیاری SPDY و http2 ارائه میدهند. پس پشتیبانی همزمان از NPN و ALPN در این سرورها، کاملا منطقی است.
ALPN با NPN تفاوتشان در در این است که چه کسی تصمیم میگیرد که با چه پرتکلی صحبت کند. در ALPN، کلاینت لیستی از پرتکلهایی که پشتیبانی میکند را به سرور میدهد و سرور برحسب کارایی و اولویت، یکی را انتخاب میکند، در حالی که در NPN، کلاینت تصمیم نهایی را میگیرد.
همانطور که قبلا اشاره کردم، برای HTTP 1.1 که از متن ساده (plain text) استفاده میکند، ارتباط اولیهی http2 با هدر Upgrade: انجام میشود. اگر سرور به http2 صحبت میکند، با کد "101 Switching" پاسخ میدهد و پس از آن، با کلاینت http2 صحبت میکند. البته، این فرآیند، باعث دوبرابرشدن درخواستها و پاسخها میشود، ولی مزیت آن این است که معمولا ممکن است یک کانکشن http2 را مدت بیشتری زنده نگه داشت و از آن استفاده بیشتری نسبت به یک کانکشن HTTP1 کرد.
در حالی که بعضی از سخنگوهای مرورگرها اعلام کردند این مورد را پیادهسازی میکنند، تیم Internet Explorer یکبار اعلام کردند که این کار را میکنند، هر چند تا به الان به قول خود عمل نکردند. همچنین curl و چند کلاینت دیگر که مرورگر نیستند اعلام کردند که از http2 به صورت متنساده (clear-text/رمزنگارینشده) پشتیبانی میکنند.
امروزه، هیچ مرورگری بدون TLS از http2 پشتیبانی نمیکند.
QUIC permite la creación de conexiones con mucha menos latencia, soluciona la pérdida de paquetes al sólo bloquear flujos individuales en lugar de todos a la vez como hacer HTTP/2, y posibilita la creación de conexiones por distintas interfaces de red fácilmente – así también cubre otras áreas que MPTCP pretende resolver.
QUIC de momento está únicamente implementado por Google en Chrome y en sus servidores, y es código no fácilmente reutilizable en otras partes, aunque libquic es un esfuerzo intentado conseguir eso exactamente. La especificación es todavía algo vaga y cambia rápidamente. Ya existe un borrador en el grupo de trabajo de transporte del IETF.
La naturaleza de HTTP 1.1 con multitud de pequeños detalles y opciones disponibles para extensiones posteriores, ha generado un ecosistema de software que ha hecho que casi ninguna implementación esté enteramente completada – y realmente es imposible decir que significa implemente por completo la especificación. Esto ha provocado que funcionalidades poco usadas en un principio, no hayan sido comúnmente implementadas ni por supuesto usadas.
Más tarde, esto ha causado un problema de interoperatibilidad, cuando clientes y servidores han comenzado a utilizar esas funcionalidades. HTTP Pipelining es el ejemplo principal de este tipo de funcionalidad.
HTTP 1.1 nunca ha conseguido aprovechar la ventajas de todo el potencial y rendimiento que ofrece TCP. Los clientes HTTP y los navegadores tienen que ser muy creativos para encontrar soluciones que reduzcan los tiempos de carga de las páginas.
Han existido otros intentos en paralelo en los últimos años, que han confirmado que no es sencillo reemplazar TCP, y que por lo tanto hay que seguir mejorando tanto TCP, como los protocolos sobre éste. Simplemente, TCP puede usarse mejor evitando pausas o momentos de tiempo que pueden usarse para enviar o recibir más información. Las siguiente secciones vienen a describir algunos de estos defectos.
Al observar la tendencia en los sitios web más populares en la carga de su página principal, emerge un patrón muy claro. En los últimos años la cantidad de información que debe ser consumida ha ido elevándose gradualmente hasta más allá de 1.9MB. Lo que es más importante en este contexto, es que de media, se necesitan más de cien recursos individuales para mostrar cada página.
Como se muestra en el siguiente gráfico, la tendencia ha estado en marcha durante un tiempo, y no hay indicación clara de que vaya a cambiar próximamente. Muestra el tamaño total de transferencia (en verde) y el número total de peticiones de media (en rojo) para servir los sitios web más populares del mundo, así como su evolución en los últimos cuatro años.
HTTP 1.1 es muy sensible a la latencia, en parte debido a que “HTTP Pipelining” todavía cuenta con demasiados problemas como para seguir apagado para un gran porcentaje de usuarios.
En los últimos años hemos ido viendo como aumentaba el ancho de banda disponible para las personas. No se ha alcanzado el mismo nivel de mejora reduciendo la latencia. Enlaces de alta latencia, como es el caso de las tecnologías móviles actuales, hacen muy complicado conseguir una buena y sobre todo rápida experiencia de usuario en web, incluso contando con un gran ancho de banda.
Otro caso de uso típico que necesita de enlaces con latencia baja, son algunos tipos de vídeo, como vídeo conferencias, juegos u otros casos similares donde no es enviado únicamente un flujo pre-generado de vídeo.
“HTTP Pipelining” es la manera de enviar otra solicitud mientras se está esperando a la respuesta de la solicitud anterior. En muy similar a esperar en el mostrador de un banco o supermercado. Tú nuca sabes si la persona delante de ti es un cliente rápido, o uno molesto que estará mil horas antes de irse: bloqueo del primero de la fila (“Head of line blocking”).
Por supuesto que puedes tener cuidado a la hora de escoger una cola y escoger la que creas vaya a ir más rápido, incluso a veces podrás iniciar tu propia cola. Pero al final siempre habrá que tomar una decisión, y una vez esté tomada, no podrás cambiar de fila.
Crear una nueva fila supone una penalización en el rendimiento y el uso de recursos, de manera que no es escalable más allá de un número pequeño de filas. No existe una solución perfecta a este problema. Incluso hoy, en 2015, los navegadores son publicados con la opción “HTTP pipelining” deshabilitada por defecto. Se puede encontrar más información sobre está materia leyendo por ejemplo la entrada 264354 de Firefox bugzilla.
Inlining هم یک ترفند دیگر برای جلوگیری از فرستادن عکسهای تکی است که با جاسازی دادههای عکس در قالب URL کار میکند. مزایا و معایب این روش، مشابه Spriting است.
یک وبسایت بزرگ، چندین فایل جاوااسکریپت متفاوت دارد. توسعهدهندگان از ابزارهای Front-End تا این فایلها را ادغام یا ترکیب کنند تا مرورگر به جای دریافت چندین فایل کوچک، یک فایل بزرگ را دریافت کند. ولی، در این روش تنها وقتی دادههای بسیار کمتری نیاز است، دادههای بسیاری فرستاده میشود و همچنین دادههای بسیاری باید بارگذاری شوند تا تغییرات اعمال شوند.
البته این روش، صرفا برای توسعهدهندگان درگیر در پروژه، مشکل ایجاد میکند.
آخرین ترفندی که برای افزایش کارایی ذکر میکنم، معمولا با نام توزیعکردن (Sharding) شناخته میشود. اساسا، به این معنی است که جنبهها و بخشهای مختلف سرویس را روی چندین میزبان (Host) مختلف بارگذاری کنند. در نگاه اول، ممکن است که این کار عجیب به نظر برسد، ولی دلیل پشت آن، قانعکننده است.
در ابتدا، استاندارد HTTP 1.1 مشخص کرده بود که کلاینتها فقط میتوانند از ۲ کانکشن TCP برای هر Host استفاده کنند. پس برای زیرپاگذاشتن این قانون، سایتهای باهوشتر از host nameهای جدید استفاده کردند و بنابراین، تعداد کانکشنها و در نتیجه سرعت بارگذاری صفحات بیشتر میشد.
به مرور زمان، این محدودیت نیز حذف شد. و امروز کلاینتها میتوانند به راحتی ۶ تا ۸ کانکشن به هر host name ایجاد کنند. ولی آنها همچنان محدودیت دارند، پس سایتها از این تکنیک برای افزایش تعداد کانکشنها استفاده میکنند. از آنجایی که تعداد فایلها به ازای هر درخواست افزایش میباشد، و همانطور که قبلا نشان دادهام، کانکشنهای بیشتر باعث میشود که مطمئن شویم که HTTP به خوبی کار میکند و صفحات سریع لود میشوند. این عجیب نیست که سایتها از بیش از ۵۰ یا حتی ۱۰۰ کانکشن با این تکنیک استفاده کنند. آمارهای اخیر از httparchive.org نشان میدهد که ۳۰۰ هزار URL پربازدید جهان به طور متوسط به ۴۰ کانکشن TCP نیاز دارند! و آمار میگوید که این تعداد کانکشنها به مرور زمان در حال افزایش است.
علت دیگر برای استفاده از تکنیک توزیع، قراردادن عکسها و منابع مشابه در یک host name جداگانهای که از Cookies استفاده نمیکنند است، چرا که امروزه حجم Cookies افزایش چشمگیری داشته است. با استفاده از میزبانهایی که کوکی ندارند، میتوانید کارایی را با کاهش حجم درخواستهای HTTP بالا ببرید!
عکس زیر، یکی از سایتهای پرطرفدار سوئد را نشان میدهد که چگونه منابع مختلف خود را در چندین host name توزیع کرده است.
نام من، دنیل استنبرگ است و برای موزیلا کار میکنم. من در حدود ۲۰ سال است که با پروژههای اپنسورس و شبکه در پروژههای مختلف کار کردهام. احتمالا به این علت بیشتر شناخته میشوم که توسعهدهندهی راهبر در پروژههای curl و libcurl بودهام. همچنین من در کارگروه IETF HTTPbis نیز برای چند سال حضور داشتم و سعی در بهروزنگهداشتن پرتکل HTTP 1.1 میکردم، همچنین در کار استانداردسازی http2 نیز مشارکت داشتهام.
ایمیل من: [email protected]
توئیتر: @bagder
وبسایت: daniel.haxx.se
وبلاگ: daniel.haxx.se/blog
اگر هر اشتباهی، نارسایی، خطا و حقایق فنی نادرست مشاهده کردید، لطفا برای من یک نسخهی تصحیحشده از پاراگراف مربوطه را ارسال کنید و نسخهی اصلی را تصحیح خواهم کرد. همچنین از کسانی که کمک میکنند، به درستی نام خواهم برد! امیدوارم که بتوانیم این نوشته را به مرور زمان بهتر کنیم.
این نوشته در https://daniel.haxx.se/http2 دردسترس است.
این نوشته تحت لایسنس Creative Commons Attribution 4.0 منتشر میشود: https://creativecommons.org/licenses/by/4.0/
تغییرات نوشتهی اصلی را میتوانید در این لینک مشاهده کنید. https://http2-explained.haxx.se/content/en/part1.html#14-document-history
تغییرات ترجمه فارسی در همین صفحه نوشته خواهد شد.
Recordad que Firefox únicamente soporta http sobre TLS. Solo verás http2 en acción con Firefox al entrar en sitios con https:// que ofrezcan soporte http2.
No existe ningún elementos en la interfaz de usuario que nos diga que se está hablando http2. No es fácilmente detectable. Un modo de averiguarlo es activar “Web developer->Network” y comprobar las cabeceras de respuesta para ver que está enviando el servidor. La respuesta será entonces “HTTP/2.0” y algo más. Firefox inserta su propia cabecera denominada “X-Firefox-Spdy:” como se aprecia en la captura de pantalla de arriba. Las cabeceras que se ven en la herramienta de red al utilizar http2 han sido convertidas desde el formato binario de http2, para parecerse al estilo clásico de las cabeceras de HTTP 1.x.No existe ningún elementos en la interfaz de usuario que nos diga que se está hablando http2. No es fácilmente detectable. Un modo de averiguarlo es activar “Web developer->Network” y comprobar las cabeceras de respuesta para ver que está enviando el servidor. La respuesta será entonces “HTTP/2.0” y algo más. Firefox inserta su propia cabecera denominada “X-Firefox-Spdy:” como se aprecia en la captura de pantalla de arriba.
Las cabeceras que se ven en la herramienta de red al utilizar http2 han sido convertidas desde el formato binario de http2, para parecerse al estilo clásico de las cabeceras de HTTP 1.x.
Existen plugins de Firefox disponibles que ayudan a visualizar si un sitio está usando HTTP/2. Uno de ellos es “SPDY Indicator”.
network.http.spdy.enabled.http2trueبه یاد داشته باشید که فایرفاکس از http2 تنها در بستر TLS پشتیبانی میکند، یعنی فقط سایتهایی که با https:// شروع میشوند.
هیچ عنصر بصری وجود ندارد که مشخص کند که دارید از پرتکل http2 استفاده میکنید. مشخصکردن آن هم توسط شما کار چندان آسانی نیست. یک راه برای تشخیص آن این است که در قسمت «Web developer->Network»، قسمت هدر پاسخها را چک کنید و ببینید که چه چیزی از سرور میگیرید. اگر پاسخ سرور HTTP/2.0 است که فایرفاکس هدر خودش را با نام X-Firefox-Spdy: اضافه میکند که در اسکرینشات بالا نشان دادهام.
هدرهایی که در ابزار Network میبینید، از فرمت باینری http2 به سبک قدیمی HTTP 1.x تبدیل شدهاند.
پلاگینهایی برای فایرفاکس وجود دارند که نشان میدهند که یک سایت از http2 استفاده میکند یا نه. یکی از آنها “HTTP/2 and SPDY Indicator” است.
So what will things look like when http2 gets adopted? Will it get adopted?
http2 is not yet widely deployed nor used. We can't tell for sure exactly how things will turn out. We have seen how SPDY has been used and we can make some guesses and calculations based on that and other past and current experiments.
http2 reduces the number of necessary network round-trips and it avoids the head of line blocking dilemma completely with multiplexing and fast discarding of unwanted streams.
It allows a large amount of parallel streams that go way over even the most sharded sites of today.
With priorities used properly on the streams, chances are much better that clients will actually get the important data before the less important data. All this taken together, I'd say that the chances are very good that this will lead to faster page loads and to more responsive web sites. Shortly put: a better web experience.
How much faster and how much improvement we will see, I don't think we can say yet. First, the technology is still very early and then we haven't even started to see clients and servers trim implementations to really take advantage of all the powers this new protocol offers.
Over the years web developers and web development environments have gathered a full toolbox of tricks and tools to work around problems with HTTP 1.1, recall that I outlined some of them in the beginning of this document as a justification for http2.
Lots of those workarounds that tools and developers now use by default and without thinking, will probably hurt http2 performance or at least not really take advantage of http2's new super powers. Spriting and inlining should most likely not be done with http2. Sharding will probably be detrimental to http2 as it will probably benefit from using fewer connections.
A problem here is of course that web sites and web developers need to develop and deploy for a world that in the short term at least, will have both HTTP1.1 and http2 clients as users and to get maximum performance for all users can be challenging without having to offer two different front-ends.
For these reasons alone, I suspect there will be some time before we will see the full potential of http2 being reached.
Trying to document specific implementations in a document such as this is of course completely futile and doomed to fail and only feel outdated within a really short period of time. Instead I'll explain the situation in broader terms and refer readers to the on the http2 web site.
There were a large number of implementations early on, and the amount has increased over time during the http2 work. At the time of writing this there are over 40 implementations listed, and most of them implement the final version.
Firefox has been the browser that's been on top of the bleeding edge drafts, Twitter has kept up and offered its services over http2. Google started during April 2014 to offer http2 support on a few test servers running their services and since May 2014 they offer http2 support in their development versions of Chrome. Microsoft has shown a tech preview with http2 support for their next Internet Explorer version. Safari (with iOS 9 and Mac OS X El Capitan) and Opera have both said they will support http2.
There are already many server implementations of http2.
The popular Nginx server offers http2 support since released on September 22, 2015 (where it replaces the SPDY module, so they cannot both run in the same server instance).
Apache's httpd server has a http2 module since 2.4.17 which was released on October 9, 2015.
, , , and have all released http2 capable servers.
curl and libcurl support insecure http2 as well as the TLS based one using one out of several different TLS libraries.
Wireshark supports http2. The perfect tool for analyzing http2 network traffic.
During the development of this protocol the debate has been going back and forth and of course there is a certain amount of people who believe this protocol ended up completely wrong. I wanted to mention a few of the more common complaints and mention the arguments against them:
It also has variations implying that the world gets even further dependent or controlled by Google by this. This isn't true. The protocol was developed within the IETF in the same manner that protocols have been developed for over 30 years. However, we all recognize and acknowledge Google's impressive work with SPDY that not only proved that it is possible to deploy a new protocol this way but also provided numbers illustrating what gains could be made.
Google publicly that they would remove support for SPDY and NPN from Chrome in 2016 and urged servers to migrate to HTTP/2 instead. In February of 2016 they that SPDY and NPN would finally be removed in Chrome 51. Since Chrome 51, it has shipped without SPDY and NPN support.
This is sort of true. One of the primary drivers behind the http2 development is the fixing of HTTP pipelining. If your use case originally didn't have any need for pipelining then chances are http2 won't do a lot of good for you. It certainly isn't the only improvement in the protocol but a big one.
As soon as services start realizing the full power and abilities the multiplexed streams over a single connection brings, I suspect we will see more application use of http2.
Small REST APIs and simpler programmatic uses of HTTP 1.x may not find the step to http2 to offer very big benefits. But also, there should be very few downsides with http2 for most users.
Not at all. The multiplexing capabilities will greatly help to improve the experience for high latency connections that smaller sites without wide geographical distributions often offer. Large sites are already very often faster and more distributed with shorter round-trip times to users.
This can be true to some extent. The TLS handshake does add a little extra, but there are existing and ongoing efforts on reducing the necessary round-trips even more for TLS. The overhead for doing TLS over the wire instead of plain-text is not insignificant and clearly notable so more CPU and power will be spent on the same traffic pattern as a non-secure protocol. How much and what impact it will have is a subject of opinions and measurements. See for example for one source of info.
Telecom and other network operators, for example in the ATIS Open Web Alliance, say that they to offer caching, compression and other techniques necessary to provide a fast web experience over satellite, in airplanes and similar. http2 does not make TLS use mandatory so we shouldn't conflate the terms.
Many Internet users have expressed a preference for TLS to be used more widely and we should help to protect users' privacy.
Experiments have also shown that by using TLS, there is a higher degree of success than when implementing new plain-text protocols over port 80 as there are just too many middle boxes out in the world that interfere with what they would think is HTTP 1.1 if it goes over port 80 and might look like HTTP at times.
Finally, thanks to http2's multiplexed streams over a single connection, normal browser use cases still could end up doing substantially fewer TLS handshakes and thus perform faster than HTTPS would when still using HTTP 1.1.
Yes, we like being able to see protocols in the clear since it makes debugging and tracing easier. But text based protocols are also more error prone and open up for much more parsing and parsing problems.
If you really can't take a binary protocol, then you couldn't handle TLS and compression in HTTP 1.x either and its been there and used for a very long time.
This is of course subject to debate and discussions on how to measure what faster means, but already in the SPDY days many tests were performed that proved browser page loads were faster (like by people at University of Washington and by Hervé Servy) and such experiments have been repeated with http2 as well. I'm looking forward to seeing more such tests and experiments getting published. A might imply that HTTP/2 holds its promises.
Seriously, that's your argument? Layers are not holy untouchable pillars of a global religion and if we've crossed into a few gray areas when making http2 it has been in the interest of making a good and effective protocol within the given constraints.
That's true. With the specific goal of maintaining HTTP/1.1 paradigms there were several old HTTP features that had to remain, such as the common headers that also include the often dreaded cookies, authorization headers and more. But the upside of maintaining these paradigms is that we got a protocol that is possible to deploy without an inconceivable amount of upgrade work that requires fundamental parts to be completely replaced or rewritten. Http2 is basically just a new framing layer.
(This section was written in 2015 and shows the state of affairs back then. Things have moved and developed significantly since.)
It is too early to tell for sure, but I can still guess and estimate and that's what I'll do here.
The naysayers will say “look at how good IPv6 has done” as an example of a new protocol that's taken decades to just start to get widely deployed. http2 is not an IPv6 though. This is a protocol on top of TCP using the ordinary HTTP update mechanisms and port numbers and TLS etc. It will not require most routers or firewalls to change at all.
Google proved to the world with their SPDY work that a new protocol like this can be deployed and used by browsers and services with multiple implementations in a fairly short amount of time. While the amount of servers on the Internet that offer SPDY today is in the 1% range, the amount of data those servers deal with is much larger. Some of the absolutely most popular web sites today offer SPDY.
http2, based on the same basic paradigms as SPDY, I would say is likely to be deployed even more since it is an IETF protocol. SPDY deployment was always held back a bit by the “it is a Google protocol” stigma.
There are several big browsers behind the roll-out. Representatives from Firefox, Chrome, Safari, Internet Explorer and Opera have expressed they will ship http2 capable browsers and they have shown working implementations.
There are several big server operators that are likely to offer http2 soon, including Google, Twitter and Facebook and we hope to see http2 support soon get added to popular server implementations such as the Apache HTTP Server and nginx. H2o is a new blazingly fast HTTP server with http2 support that shows potential.
Some of the biggest proxy vendors, including HAProxy, Squid and Varnish have expressed their intentions to support http2.
All throughout 2015, the amount of http2 traffic has been increasing. In early September, Firefox 40 usage was at 13% out of all HTTP traffic and 27% out of all HTTPS traffic, while Google sees roughly 18% of incoming request as HTTP/2. It should be noted that Google runs other new protocol experiments as well (see QUIC in 12.1) which makes the http2 usage levels lower than it could otherwise be.
Ce serait sympa d'améliorer ce protocole, n'est-ce pas ? Notamment:
Un protocole moins sensible au RTT (Round Trip Time, Aller-Retours)
En corrigeant le pipelining et le head of line blocking
En évitant le besoin de multiplier le nombre de connexions vers un même hôte
En conservant toutes les interfaces existantes, tout le contenu et le format d'URI
Tout cela à travers le groupe de travail de l'IETF HTTPbis
L'IETF (Internet Engineering Task Force) est une organisation qui développe et promeut les standards de l'Internet, et ce essentiellement au niveau protocolaire. Très connue pour la série de RFC documentant tout depuis TCP, DNS, FTP, HTTP aux bonnes pratiques en passant par des variantes de protocoles qui n'ont jamais vu le jour.
Au sein de l'IETF existent des groupes de travail se penchant sur un sujet bien établi avec des objectifs précis. Ils établissent une charte qui définit les règles et limitations liées à l'objectif. Toute personne intéressée peut se joindre aux discussions et au développement, et chaque participant bénéficie du même droit de parole et du même poids que les autres. Peu d'importance est apportée aux sociétés pour lesquelles les participants travaillent (le cas échéant).
Le groupe de travail HTTPbis (voir plus tard pour l'origine du nom) a été créé à l'été 2007 et chargé de mettre à jour la spécification HTTP 1.1. Des discussions sur une nouvelle version de HTTP ont réellement commencé fin 2012. La mise à jour HTTP 1.1 s'est terminée début 2014 avec la série des .
La réunion finale d'interopérabilité pour le groupe de travail HTTPbis s'est tenue à New York en juin 2014. Toutefois les discussions en suspens et les procédures IETF nécessaires pour obtenir la RFC officielle continueront jusque l'année suivante.
Des acteurs importants de HTTP ont manqué à l'appel du groupe de travail pendant les discussions et réunions. Je ne souhaite pas mentionner de nom de société ou produit, mais il est clair que ces acteurs de l'Internet font confiance à l'IETF pour finir le travail sans leur participation...
Le groupe est appelé HTTPbis, le "bis" faisant référence au . Bis est souvent utilisé comme suffixe ou partie d'un nom à l'IETF lors d'une mise à jour ou addendum d'une spécification. Comme ici avec HTTP 1.1, donc.
est un protocole développé par Google. Ils l'ont clairement créé dans un esprit d'ouverture et ont invité tout le monde à participer, mais il était évident qu'ils bénéficiaient d'une position de contrôle avec à la fois un navigateur populaire et un nombre significatif de serveurs très utilisés pour leurs services.
Quand le groupe HTTPbis décida de travailler sur http2, SPDY avait déjà prouvé que le concept fonctionnait. Il avait montré qu'il était possible de le déployer sur Internet et des mesures publiées montraient sa meilleure performance. Le travail sur http2 a donc démarré depuis le draft SPDY/3, rapidement transcrit dans un draft-00 de http2 grâce à quelques remplacements.
HTTP 1.1 تبدیل به پرتکلی شده که این روزها، تقریبا برای همهچیز در اینترنت استفاده میشود. سرمایهگذاریهای عظیمی در پرتکلها و زیرساختهایی که از HTTP 1.1 بهره میبرند شده است، به دلیل اینکه اغلب اوقات، اجراکردن چیزی روی HTTP راحتتر از ساختن چیزی از نو است.
هنگامی که HTTP ساخته شده و به دنیا عرضه شد، بسیاری آن را یک پرتکل ساده و سرراست یافتند، ولی زمان ثابت کرد که این دیدگاه نادرست است. HTTP 1.0 در استاندارد RFC 1945 تنها در ۶۰ صفحه توصیف شده است که در سال ۱۹۹۶ منتشر شد. RFC 2616 که HTTP 1.1 را توضیح میدهد، در یک رشد قابلتوجه، به ۱۷۶ صفحه هم میرسد. هنوز هم هنگامی که در IETF روی استانداردهای مربوط به آن کار میکنیم، [ناچارا] آن را به ۶ سند، که تعداد صفحات آنها روی هم بسیار بیشتری میشود، تقسیم کردیم که حاصل آن، استاندارد RFC 7230 و خانواده شد. به هر حال، HTTP 1.1 بزرگ است و دارای جزئیات و ظریفکاریهای بسیار، و البته امکانات اختیاری است.
طبیعت HTTP 1.1، داشتن جزئیات بسیار و گزینههای موجود برای افزونههای بعدی، تبدیل به یک اکوسیستم نرمافزاری شد که تقریبا هیچ پیادهسازی، همهچیز را پیادهسازی نمیکند، و حتی ممکن نیست که دقیقا بگوییم که این «همهچیز» چه چیزهایی هستند. این ویژگی باعث بهوجودآمدن شرایطی شد که قابلیتهایی که در ابتدا، بسیار کماستفاده بودند، به ندرت پیادهسازی شدند و کسانی که این قابلیتها را پیادهسازی کردند، متوجه شدند که کاربردهای بسیار کمی برای آنها وجود دارد.
بعدها، این ویژگیها باعث ایجاد ناهماهنگی بین کلاینتها و سرورهایی که از این قابلیتها استفاده میکردند شد. HTTP pipelining از نمونههای بارز این قابلیتها است.
HTTP 1.1 به سختی از همهی مزایا، قدرت و کارایی TCP استفاده میکند. کلاینتهای HTTP و مرورگرها باید در پی یافتن راههای خلاقانه برای کاهش زمان بارگذاری صفحات باشند.
تلاشهای دیگری که در طول این سالها به طور موازی پیگیری میشدند هم نشان دادهاند که جایگزینکردن TCP کار راحتی نیست، به همین دلیل ما روی بهبود TCP و پرتکلهای وابسته به آن کار میکنیم.
به عبارت دیگر، TCP میتواند به گونهای استفاده شود که وقفهها را کمتر کند یا از بازههای زمانی تلفشده برای ارسال و دریافت دادههای بیشتری استفاده شود. قسمتهای بعدی بعضی از این کاستیها را نمایان میکنند.
وقتی به آمارهای امروزی درمورد پرطرفدارترین وبسایتها و صفحههای اول آنها نگاه میکنیم، یک الگوی مشخص را میتوان برداشت کرد. در طول این سالها، حجم دادههایی که باید برای بازکردن این صفحات مبادله کرد، به ۱.۹ مگابایت رسیده است. چیزی که دراینباره مهمتر است، این است که بیش از ۱۰۰ فایل مختلف برای نمایش هر صفحه لازم است.
همانطور که نمودار زیر نشان میدهد، این روند به همین منوال در حال پیشرفت است و کمتر نشانهای از تغییر در آیندهای نزدیک به چشم میخورد. این نمودار، رشد اندازهی دادههای مبادلهشده (با رنگ سبز) و میانگین تعداد درخواستها (قرمز) را در وبسایتهای پرطرفدار اینترنت نشان میدهد و اینکه این ارقام چگونه در یک بازهی ۴ ساله تغییر کردهاند.
HTTP 1.1 بسیار به تأخیر حساس است، میتوان گفت بخشی از این حساسیت به دلیل این است که HTTP pipelining هنوز آنقدر مشکل دارد که اکثر کاربران نتوانند از آن استفاده کنند.
با این که شاهد رشد عظیمی در پهنایباند دردسترس مردم در چند سال اخیر بودهایم، ولی به همان نسبت،، اقدامی برای کاهش این تأخیرها نشده است. ارتباطات با تأخیر بالا، مانند فناوریهای کنونی موبایل، داشتن یک تجربهی وبگردی خوب و سریع را سخت میکند، حتی اگر پهنای باند بسیار بالایی هم در اختیار داشته باشید.
مورد استفادهی دیگری از تأخیرهای پایین، نوعهای خاصی از ویدیو هستند، مانند ویدیوکنفرانس، گیمینگ و مشابههای آن که هیچ جریان ازپیشساختهای برای ارسال وجود ندارند.
HTTP pipelining یک راه برای فرستادن یک درخواست دیگر، در حالی که منتظر پاسخ درخواست دیگری هستیم، است. این مفهوم بسیار شبیه به صفهای بانک یا سوپرمارکت است. شما نمیدانید که نفر اول صف یک آدم تر و فرز است یا یک آدم مزاحم که وقت زیادی را تلف میکند تا کارش را انجام دهد.
البته، شما میتوانید صفی را انتخاب کنید که فکر میکنید سریعتر است یا حتی صف خودتان را تشکیل بدهید. ولی در نهایت، شما نمیتوانید تصمیم نگیرید. و وقتی تصمیم گرفتید، نمیتوانید تصمیم خود را عوض کنید.
تشکیل یک صف جدید با هدررفت منابع و کارایی همراه است، پس هنگامی که تعداد صفها بیشتر میشود دیگر کارایی ندارد. در واقع، هیچ راهحل بینقصی برای این مشکل وجود ندارد.
حتی امروزه هم بیشتر مرورگرهای دسکتاپ با HTTP pipelining به صورت غیرفعال عرضه میشوند.
جزئیات بیشتر دربارهی این موضوع را میتوانید در بخوانید.
El protocolo obliga que a un receptor a leer e ignorar todas las tramas desconocidas utilizando tipo de trama desconocida (unknown frame types). Dos partes pueden así negociar el uso de nuevos tipos de trama en una base hop-by-hop, y las tramas no podrán cambiar el estado y no tendrán control de flujo.
Si http2 debía permitir o no extensiones, fue un tema ampliamente debatido durante el tiempo de desarrollo del protocolo con opiniones igualmente balanceadas a favor y en contra. Después del draft-12, el péndulo basculó por última vez, y las extensiones se permitieron de nuevo.
Por lo tanto, las extensiones no son partes del protocolo real por lo que son documentadas al margen de la especificación del núcleo. Llegados a este punto, existen dos tipos de trama que se debatieron para su inclusión en el protocolo, y que probablemente serán las primeras tramas en ser extensiones. Las describiré a continuación por su popularidad y por su estado anterior como tramas “nativas”:
Durante la adopción de http2, existen razones para sospechar que las conexiones TCP serán mucho más largas y se mantendrán vivas mucho más tiempo de lo que han estado las conexiones con HTTP 1.x. Un cliente debe ser capaz de hacer un montón de las cosas que hace con una única conexión hacia cada dominio/sitio, así que una conexión estará abierta por un tiempo bastante elevado.
Esto afectará a como funcionan lo balanceadores HTTP y se generarán situaciones en las cuales un sitio querrá anunciar y sugerir que el cliente se conecte a otro host, tanto por razones de rendimiento, como porque el sitio puede necesitar mantenimiento u otra razón similar.
El servidor enviará entonces la cabecera (o la trama ALTSVC en http2) que indicará al cliente el servidor alternativo. Otra ruta al mismo contenido, utilizando otro servicio, dominio y número de puerto.
El cliente intentará conectarse a ese servicio asíncronamente, y utilizará ese servicio alternativo si éste funciona correctamente.
La cabecera Alt-Svc permite al servidor que proporciona el contenido por http://, informar al cliente que ese mismo contenido esta también disponible a través de una conexión TLS.
Esta es una funcionalidad debatida en cierta manera. Una conexión de ese tipo, realizaría una conexión TLS sin autenticar que no sería advertida como “segura” en ningún sitio, ya que no usaría un candado en la Interfaz de Usuario o avisaría al usuario de cualquier manera que no se trata del viejo HTTP plano, sino de que se trata de TLS oportunista, concepto que en sí mismo, que encuentra firmes detractores.
Una trama de este tipo está pensada para ser enviada únicamente una vez por un agente http2 cuando aún queda información que enviar, pero el control de flujo lo prohíbe. La idea de esto es que si tu implementación recibe esta trama, entonces sabes que tu implementación ha cometido algún error y/o están recibiendo menos que la velocidad que puedes recibir por esta razón.
Se cita en el draft-12, antes de que esta trama fuera expulsada como extensión:
“La trama BLOCKED está incluida en esta revisión para facilitar la experimentación. Si los resultados no son positivos, se eliminará”
پروژهی curl به طور آزمایشی پشتیبانی از http2 را از سپتامبر ۲۰۱۳ ارائه میدهد.
در روح curl، ما تلاش میکنیم که همهی جنبههای http2 را پوشش دهیم. curl معمولا به عنوان ابزاری برای تست وبسایتها به کار میرود و ما تلاش میکنیم که این روند را برای http2 نیز حفظ کنیم.
curl از لایبرری جداگانهای به نام nghttp2 برای لایهی فریم استفاده میکند. curl به nghttp2 1.0 یا بالاتر نیاز دارد.
البته، فراموش نشود که در حال حاضر، curl ارائهشده در لینوکس و libcurl با پشتیبانی از پرتکل HTTP/2 به طور پیشفرض ارائه نمیشوند.
در درون، curl هدرهای http2 را به سبک HTTP 1.x تبدیل میکند و آنها را به کاربر ارائه میدهد تا مانند HTTP کنونی ظاهر شوند. این کار اجازه میدهد تا انتقال دادهها برای کاربر curl و HTTP امروزی راحتتر شود. در درخواستهای رو به بیرون نیز هدرها در میانهی راه از حالت HTTP 1.x به فرمت http2 تبدیل میشوند. این قابلیت باعث میشود که کاربران خیلی به این مورد اهمیت ندهند که با کدام نسخهی HTTP روبهرو هستند.
curl از http2 برمبنای TCP استاندارد و هدر Upgrade: پشتیبانی میکند. اگر شما یک درخواست HTTP انجام دهید و بخواهید از HTTP 2 استفاده کنید، curl از سرور میخواهد که در صورت امکان از http2 استفاده کند.
curl از لایبرریهای مختلف TLS میتواند استفاده کند. چالشی که در TLS با آن مواجه هستیم، پشتیبانی از ALPN برای Http2 است و همچنین پشتیبانی از NPN است.
curl را با ورژنهای جدیدتر OpenSSL یا NSS بیلد (Build) کنید تا پشتیبانی ALPN و NPN را داشته باشید. از GNUTLS یا PolarSSL، پشتیبانی ALPN را میگیرید، ولی NPN را نه.
برای اطلاعدادن به curl برای استفاده از http2، چه به صورت متنساده یا TLS، از آپشن --http2 استفاده کنید. curl همچنان از HTTP/1.1 به طور پیشفرض استفاده میکند.
اپلیکیشن شما میتواند از URLهای https:// یا http:// پشتیبانی کند، ولی شما میتوانید از آپشن CURLOPT_HTTP_VERSION استفاده کنید تا نسخهی HTTP مورداستفاده را تغییر دهید.
libcurl تلاش میکند که رفتارهای کنونی را ادامه دهد، بنابراین باید قابلیت multiplexing HTTP/2 را با آپشن فعال کنید.
نکتهی ریز دیگر اینکه در خاطر داشته باشید که اگر چندین درخواست با libcurl یکجا بفرستید، با اینترفیس چندگانهی خودش، هر تعداد انتقالی را یکجا شروع کند و اگر شما میخواهید صبر کنید تا libcurl همهی آنها را در یک کانکشن قرار دهد،به جای اینکه چندین کانکشن با هم باز کند، شما میتوانید از آپشن استفاده کنید.
libcurl 7.44.0 و بالاتر از قابلیت Server push در HTTP/2 پشتیبانی میکند. شما میتوانید از این قابلیت با اضافهکردن یک تابع برای فراخوانی هنگام دریافت Push با آپشن ست کنید. اگر Push توسط اپلیکیشن پذیرفته شود، یک انتقال جدید روی curl ساخته میشود و محتوا به همان صورت کانکشنهای معمولی تحویل داده میشود.
curlプロジェクトは試験的にhttp2のサポートを2013年9月から行っています。
curlの精神に則り、我々はできるかぎり全てのhttp2の機能を提供する予定です。curlはしばしばテストツール、そしてwebサイトをいろいろと弄くる開発者の手段として使われるので、http2でもこの伝統を引き継ぐ予定です。
curlは第三者のライブラリnghttp2をhttp2のフレームレイヤーの実装に使用しています。curlにはnghttp2 1.0以降が必要です。
curlとlibcurlは、Linuxのディストリビューションからインストールした場合、まだ必ずしもHTTP/2プロトコルがサポートされているわけではないことに注意してください。
curlは内部的に受信したhttp2ヘッダーをHTTP 1.xスタイルのヘッダーに変換してユーザーに提示するので、既存のHTTPと同じように見えます。これにより既存のcurlとHTTPの使用からの移行が容易になります。送信するヘッダーについても同様です。HTTP 1.xスタイルでヘッダーをcurlに伝えると、http2サーバーと通信するときには自動で変換されます。これによりユーザーは特定のHTTPバージョンが使われているのかどうかといったことに気を使わなくて済むのです。
curlはUpgradeヘッダーでhttp2を標準のTCP上でサポートしています。あなたがHTTPリクエストでHTTP/2を要求した場合、curlはサーバーに可能なら接続をhttp2にアップグレードするように依頼します。
curlは多くのTLSライブラリをサポートしていて、これはhttp2サポートでも同様です。TLSにおけるhttp2サポートの問題点はALPNのサポート、そしてそれほど重要ではないですがNPNのサポートです。
最近のOpenSSLまたはNSSとともにcurlをビルドしてALPNとNPN両方のサポートを手に入れることができます。GnuTLSやPolarSSLの場合、ALPNが利用できますが、NPNは利用できません。
curlにhttp2を使うように指示するには、平文、TLSに関係なく、--http2オプションを使います(” ダッシュ ダッシュ http2”)。curlはまだデフォルトがHTTP 1.1であり、http2を使う場合は追加のオプションが必要なのです。
アプリケーションでは URLを今までどおり使いますが、http2を使うにはcurl_easy_setoptのCURLOPT_HTTP_VERSIONオプションをCURL_HTTP_VERSION_2にします。こうすることで出来る限りhttp2を使うようになりますが、それができない場合はHTTP 1.1が使われます。
libcurlは既存の振る舞いを維持しようとするので、HTTP/2の多重化をアプリケーションで有効にするにはオプションを使います。このオプションを使わない場合、今まで同様に接続あたりの同時リクエスト数は1になります。
もうひとつ注意してほしいことは、multiインターフェースをつかって複数の転送を同時にlibcurlで行う場合、複数の接続が使われることになります。libcurlを少し待たせて同じ接続にすべての転送を多重化するには、待たせる転送に対してオプションを使います。
libcurl 7.44.0以降はHTTP/2サーバープッシュをサポートしています。この機能を使うにはオプションを使ってプッシュコールバックをセットします。プッシュがアプリケーションによって受け入れられた場合、新しいCURL easy handleが作成されて、他の転送と同様にコンテンツを受信します。
Firefox ha seguito l'evolversi delle draft da vicino, ha reso disponibili test sulle implementazioni http2 per lunghi mesi. Durante lo sviluppo del protocollo http2, client e server hanno dovuto mettersi d'accordo su quale versione della draft usare, cosa perarltro abbastanza fastidiosa in fase di test. Giusto per essere sicuri che client e server siano allineati su quale versione della draft stiano implementando.
In tutte le versioni di Firefox a partire dalla 35, rilasciata il 13 Gennaio 2015, il supporto nativo http2 è abilitato.
Digita 'about:config' nella barra dell'indirizzo e cerca l'opzione “network.http.spdy.enabled.http2draft”. Assicurati che sia impostata a true. In Firefox 36 esiste un'altra voce di configurazione chiamata “network.http.spdy.enabled.http2” che è impostata su true per default. Quest'ultima controlla la versione “plain” di http2 mentre la prima abilita o disabilita la negoziazione della versione http2-draft. Entrambe sono abilitate a partire da Fierfox 36.
Ricordatevi che Firefox implementa https solo su TLS. Vedrete http2 in azione se e solo se starete utilizzando un sito https:// che offre supporto per http2.
Non esiste alcun elemento della UI (User Interface) che indichi quando si stia parlando http2. Non è facile poterlo affermare. Un modo relativamente facile di verificarlo è abilitare la parte “Web developer->Network” e controllare negli header di risposta quanto ottenuto dal server. In caso risposta sia dunque “HTTP/2.0” qualcosa, Firefox inserirà il proprio header “X-Firefox-Spdy:” come possbile osservare nello screenshotqui sopra.
Gli headers che vedete nel tool Network durante un dialogo http2 sono stati convertiti a partire dal formato http2 binario verso il vecchio stile di headers HTTP 1.x
Esistono plugins Firefox che aiutano a capire se un sito utilizzi http2. Uno di questi è .
진보된 프로토콜을 만드는게 좋지 않을까요? 그것은...
대기시간이 적게 걸리는 것
파이프라인과 라인블로킹의 문제를 고칠 수 있는 것
각 호스트의 연결 숫자를 늘릴 필요가 없게 하는 것
모든 인터페이스, 콘텐츠, URI포맷과 스키마를 유지하는 것
IETF의 HTTPbis 워킹 그룹에서 만들어지는 것
The Internet Engineering Task Force(IETF)는 대개 프로토콜 레벨에서 인터넷 표준과 발전을 장려하는 기관입니다. 그들은 다수의 프로토콜과 HTTP, FTP, DNS, TCP 로부터 모든 것을 문서화하는 절대로 사라지지 않는 메모의 RFC시리즈로 알려져 있습니다.
IETF에선, 특정 목표를 이루기 위해 전용 "워킹 그룹"을 생성합니다. 그들은 "charter"를 설립합니다. 그들은 그들이 제공해야하는 것들에 있어서 몇가지 제한사항과 가이드라인을 설정한 "charter"를 설립합니다. 누구든지 개발과 토론을 위해서 참여하게 될 수 있습니다. 참여자 모두가 영향력을 행사할 수 있는 동등한 기회가 주어지며 그들이 어떤 회사에서 일을 하고 있던지간에 거의 상관이없습니다.
HTTPbis 워킹 그룹(이름설명은 나중에 합니다)은 HTTP 1.1 업데이트를 목표로 2007년 여름에 설립되었습니다. 그룹에서 실제로 HTTP의 다음 버전에 대한 논의가 있었던 것은 2012년 이후라는 말이있습니다. HTTP 1.1 업데이트는 2014년 이전에 완료되었고 시리즈로 되었습니다.
HTTPbis의 최종 인터롭 미팅은 2014년 6월 뉴욕에서 시작되었습니다. 남아있는 논의들과 IETF 배포작업은 사실상 공식 RFC에서 제외되었고 내년으로 연기되었습니다.
HTTP창시자 중 몇몇은 워킹 그룹 미팅과 논의로부터 잊혀졌습니다. 저는 여기서 어떠한 배포자의 이름이나 특정기업이 언급되는걸 바라지 않습니다. 하지만 명백히 인터넷에서의 몇몇 배우들은 이러한 회사들의 참여가 없더라도 IETF의 미래가 올바른 길로 나아갈 것이라고 보고있습니다.
그룹의 이름은 HTTPbis에서 "bis"라는 이름은에서 유래되었습니다. IETF에서 Bis는 보통 업데이트나 두번째 스펙을 표시할 경우에 접미사나 이름의 부분으로 사용됩니다. HTTp 1.1업데이트도 마찬가지입니다.
는 Google에서 주도개발한 프로토콜입니다. 그들은 확실히 그것을 오픈하고 누구나 참여할 수 있도록 하였지만, 인기있는 브라우져와 사용자가 많은 서비스를 가동시키고 있는 거대한 서버군을 모두 자신의 통제하에 두고있다는 것에 대한 사실에서 확실한 이익이 있었습니다.
HTTPbis에서 http2에 대한 작업을 하려 했을때, SPDY는 이미 자신의 워킹컨셉을 입증했습니다. 그것은 배포가 가능하다는 것을 보여주었고 그것의 성능도 수치로 입증하였습니다. SPDY/3 초안에서 시작된 http2 작업은 draft-00에서 약간의 변형을 기반으로 합니다.
Si encuentras este documento un poco ligero de contenido o de detalles técnicos, aquí tienes otros recursos para ayudar a satisfacer tu curiosidad:
La lista de correo HTTPbis y su archivo: https://lists.w3.org/Archives/Public/ietf-http-wg/
La especificación http2 actual en su versión en HTML: https://httpwg.github.io/specs/rfc7540.html
Detalles de networking http2 de Firefox: https://wiki.mozilla.org/Networking/http2
Detalles de la implementación http2 de curl:
El sitio web de http2: y quizás su FAQ en particular:
El capítulo sobre HTTP/2 de Ilya Grigorik's en su libro “High Performance Browser Networking”:
تصمیمهای سخت بسیاری برای http2 گرفته شده است. با عرضهی http2، یک راه صحیح برای بهروزرسانی آن به نسخههای بالاتر پرتکل وجود دارد که راه برای آپدیتهای بیشتر پرتکل هموار میکند. همچنین، یک مفهوم و زیرساخت را برای مدیریت چندین نسخه به طور همزمان ارائه میدهد. شاید لازم نباشد که همهی چیزهای قدیمی را برای ارائهی چیزهای جدیدتر دور بیندازیم؟
http2 بسیاری از امکانات قدیمی HTTP 1 را با خود به همراه دارد تا مبادلهی دادهها بین HTTP1 و http2 میسر باشد. بعضی از این امکانات قدیمی، مانع گسترش و توسعههای جدیدتر میشود. شاید http3 بتواند بعضی از این امکانات را پشتیبانی نکند؟
فکر میکنید هنوز چه چیزی در HTTP کم داریم؟
پروژهی QUIC (Quick UDP Internet Connections یا کانکشن سریع اینترنتی UDP) یک پرتکل آزمایشی جالب است که توسط گوگل طراحی شده است که با همان سبک SPDY اجرا شده است. QUIC ترکیبی از TCP + TLS + جایگزین HTTP/2 تحت UDP است.
QUIC اجازه میدهد که کانکشنها با تأخیر بسیار کمتری برقرار شوند، مشکل Packet Loss را به گونهای حل میکند که بهجای متوقفشدن همهی جریانها فقط یک جریان قطع شود (همانطور که http2 هم میکند) و همچنین امکان برقراری ارتباط را از طریق اینترفیسهای مختلف شبکه فراهم میسازد و بنابراین مشکل MPTCP را نیز حل میکند.
QUIC تا به الان، تنها در گوگل کروم و نیز سرورهای آنها پیادهسازی شده و استفاده از کد آنها چندان راحت نیست، حتی اگر یک برای اینکار داشته باشیم. این پرتکل به عنوان یک به کارگروه انتقال دادههای IETF آورده شده است.
問題に直面した時はいつも人々は集まって回避策を考えます。中には使いやすい案もあるし、ゴミのように役に立たない案もあります。
小さな画像をより集めて一つの大きな画像に結合することをスプライティングと言います。JavaScriptやCSSを使って大きな画像から個々の小さな画像を"切り取り"表示させるのです。
サイトはこのトリックを速度向上のために使います。HTTP 1.1では1つの大きな画像をダウンロードするほうが100個の小さな画像をそれぞれダウンロードするよりもはるかに高速です。
もちろんこれには不利なところがあって、それは小さな画像の1個か2個程度しか表示しないサイトの場合です。キャッシュからはすべての画像が一度に削除されてしまうことになり、よく使う画像だけをキャッシュに残すといったことができないのです。
インライニングは個々の画像を送信することを回避する別のトリックで、CSSファイルに埋め込んだdata: URLを使います。これはスプライティングと同じ長所と短所を持っています。
大きなサイトではたくさんのJavaScriptファイルを使っています。開発者はフロントエンドのツールを使って全てのファイルを一つの大きなファイルに結合します。ブラウザーは個々のファイルをダウンロードするのではなく結合した一つのファイルだけをダウンロードするのです。ほんの一部だけをほしい場合でも巨大なファイル全体が送信されるのです。ほんの一部でも変更されると、巨大なファイル全体をリロードする必要があります。
このプラクティスはもちろん開発者にとって厄介なことなのです。
ここで紹介する最後の性能を向上させるトリックは"シャーディング"と呼ばれているものです。これは基本的にサービスの機能をできるだけ多くのホスト上に分散して配置することです。初見では少し奇妙に見えるかもしれません。しかしその背景には健全な理由があるのです。
初期のHTTP 1.1の仕様書はクライアントが各ホストへ確立できるTCP接続数を最大2個としていました。この仕様を破らないようにするため賢いサイトは単純に新しいホスト名を発明したのです。するとどうでしょう、サイトへの接続数は増え、ページロード時間を削減することができたのです。
時を経てこの制限は削除され、今日においてクライアントはホスト名毎に6-8接続を使っています。しかしこの接続数に制限があるのは変わりないので接続数を増やすためにサイトはこのトリックを使い続けています。先に示したようにオブジェクトの数が増えるにつれて、HTTPを効率よく機能させサイトを高速化するためだけに多くの接続が使われているのです。50以上、時には100を超える接続がひとつのサイトで使われる、ということも珍しいことではありません。httparchive.orgの最近の統計は世界トップ300K個のURLにおいて、平均40(!)個のTCP接続がサイトを表示するために使われていることを示しています。そして徐々に増加している傾向にあるのです。
別の理由は、最近のcookieのサイズはとても大きいので、画像やそれに類するリソースをcookieを使っていない別のホストに置くことです。cookieフリーな画像ホストを使うと、小さいHTTPリクエストをつかって性能を向上させることができる場合があります。
下図はスウェーデンのトップwebサイトの一つをブラウジングしたとき、パケットのトレースがどうなっているか、そしてどのようにリクエストが複数のホスト名に分散されているかを示しています。
ایدهی استفاده از عکسهای لگو از Mark Nottingham گرفته شده است.
آمارهای مربوط به HTTP از https://httparchive.org/ دریافت شده است.
نمودار RTT از ارائههای Mike Belshe گرفته شده است.
فرزندانم، آگنس و رکس که لگوهایشان را برای نشاندادن قسمت «انتخاب صف درست» به من قرض دادند.
همچنین از این دوستان که مرا با دیدگاهها و بازخوردهایشان کمک کردند: Kjell Ericson, Bjorn Reese, Linus Swälas و Anthony Bryan. از کمک شما بسیار سپاسگزارم، چرا که این نوشته را واقعا بهتر کردند!
در طول تغییرات، این افراد صمیمانه خطاها را گزارش کردند و نوشته را بهتر کردند: Mikael Olsson, Remi Gacogne, Benjamin Kircher, saivlis, florin-andrei-tp, Brett Anthoine, Nick Parlante, Matthew King, Nicolas Peels, Jon Forrest, sbrickey, Marcin Olak, Gary Rowe, Ben Frain, Mats Linander, Raul Siles, Alex Lee, Richard Moore
از بابت حمایتهای علمی و معنوی ایشان و همچنین همهی کسانی که در فرآیند ترجمهی این کتاب کمک کردند و به علت کثرت نام، نمیتوانم همگی را نام ببریم، سپاسگزارم.
امیدوارم توانسته باشم به جامعهی علمی فارسیزبان کمکی کرده باشم (:
¿No estaría bien hacer un protocolo mejorado? Algo incluyendo...
Hacer que el protocolo sea menos sensible a RTT.
Arreglar el pipelinig y el problema del primero de la cola.
Parar la necesidad y el deseo de seguir aumentando el numero de conexiones para cada host.
Mantener todas las interfaces existentes, todo el contenido todos los formatos de URI y sus esquemas.
Esto habría de hacerse con el grupo de trabajo del IETF, HTTPbis.
El Internet Engineering Task Force (IETF) es una organización que desarrolla y promueve estándares en Internet. La mayoría a nivel de protocolo. Son ampliamente conocidos por las series de documentos RFC que vienen a documentar todo, desde TCP, DNS, buenas prácticas FTP, HTTP y numerosas variaciones de protocolos que nunca han llegado a ningún sitio.
Los grupos de trabajo dentro IETF son formados con un ámbito limitado a conseguir un objetivo concreto. Establecen un “capítulo” (chapter) con un conjunto de guías y limitaciones de lo que deberían ser. Todo el mundo y cualquiera puede unirse al debate y al desarrollo. Cualquier que se une y dice algo, tienen el mismo peso y la misma oportunidad de afectar al resultado y todo el mundo es una persona humana e individual, sin importar demasiado en que empresa trabaja el individuo en concreto.
El grupo de trabajo HTTPbis (más tarde se explica este nombre) fue formado durante el verano de 2007 y se le encomendó la tarea de crear una actualización para la especificación HTTP 1.1. Aunque el debajo dentro del grupo comenzó realmente a finales de 2012. El trabajo de de actualización de HTTP 1.1 fue terminado a comienzos de 2014 y resultó en la serie .
La reunión operativa supuestamente final del grupo de trabajo HTTPbis tuvo lugar a comienzos de 2014 en Nueva York. Las debates restantes y los procedimientos del IETF necesarios para publicar el RFC se sucedieron durante el año siguiente.
Algunos de los agentes más grandes en HTTP no estuvieron en los debates o reuniones del grupo de trabajo. No pretendo citar ninguna empresa o producto en particular en este documento, pero claramente algunos actores del Internet de hoy, parecen confiar plenamente en que el IETF hará un buen trabajo sin tener en cuenta a estas empresa.
El grupo se ha denominado HTTPbis de manera que la parte “bis” procede del . Bis es muy usado por el IETF bien como un sufijo o bien como parte de un nombre para una actualización o para la segunda parte de una especificación. En este caso para HTTP 1.1.
es un protocolo encabezado y desarrollado por Google. Ha sido indudablemente desarrollado en abierto y todo el mundo ha sido invitado a participar, pero obviamente son los principales beneficiados al controlar una implementación muy popular de navegador y una parte significativa de la población de servidores con bastantes servicios muy conocidos.
Cuanto el grupo HTTPbis decidió que era hora de comenzar a trabajar en http2, SPDY había demostrado que era un concepto que funcionaba. Había demostrado que era posible desplegar en Internet y habían publicado números demostrando su rendimiento. El trabajo para http2 comenzó posteriormente desde el draft SPDY/3 que se convirtió en el draft-00 de http2 básicamente con un poco de búsqueda y reemplazo.
Comme toujours face aux problèmes, les gens trouvent des solutions de contournement. Certaines sont astucieuses et utiles, d'autres sont juste d'horribles rustines.
Spriting est un terme anglais souvent utilisé pour décrire la consolidation de petites images en une seule grosse image. Cette image est ensuite découpée en petites images individuelles, via l'utilisation de JavaScript ou de CSS.
Cette astuce est utilisée car l'obtention d'une seule grosse image est beaucoup plus rapide en HTTP 1.1 que celle de 100 petites.
Bien sûr, cela représente une surcharge pour les pages qui n'ont besoin que d'une ou deux images de la mosaïque. Cela rend aussi le cache moins pertinent car on vide du cache toutes les images de la mosaïque en une fois au lieu de garder les images les plus utilisées dans le cache.
L'inlining (en ligne, en français) est une autre astuce évitant l'envoi d'images individuellement. Il est possible d'imbriquer des données à l'intérieur des URLs présentes dans le CSS. Ce genre d'approche offre des avantages et inconvénients similaires au spriting.
Il est courant pour des sites de taille importante d'utiliser plusieurs fichiers JavaScript séparés. Les outils de conception de sites permettent aux développeurs de fusionner ces fichiers pour qu'un navigateur ne fasse qu'une seule requête vers un gros fichier JavaScript. L'inconvénient de cette méthode est qu'elle nécessite le chargement d'une quantité importante de données là où seule une petite partie est réellement nécessaire. De la même façon, l'intégralité du fichier doit être téléchargée à nouveau si une infime partie est modifiée.
La dernière astuce que je veux mentionner est connue sous le nom de "sharding". C'est la possibilité de charger le contenu d'un site depuis autant de hosts que possible. À première vue, cela paraît étrange mais c'est finalement assez astucieux.
HTTP 1.1 limitait initialement à deux le nombre de connexions TCP simultanées d'un client à un même host. Pour ne pas contredire la spécification, des sites astucieux créaient simplement de nouveaux noms de hosts, et voilà, vous pouviez avoir davantage de connexions vers votre site et réduire le temps de chargement.
Avec le temps, cette limitation a été levée et les clients utilisent aujourd'hui typiquement 6 à 8 connexions par nom de host; cela dit, la limite perdure et certains sites continuent d'utiliser cette technique pour accroître le nombre de connexions. Comme le nombre d'objets augmente continuellement, l'utilisation d'un grand nombre de connexions permet de maximiser les performances. Il n'est pas inhabituel de voir des sites utiliser plus de 50 voire 100 connexions pour un seul site utilisant cette technique. Des statistiques récentes de httparchive.org montrent que le top 300.000 des URLs requiert en moyenne 40(!) connexions TCP pour afficher le site, et que ce nombre augmente de façon continue.
La taille des cookies devenant conséquente, il est également intéressant de placer certaines ressources comme les images sur un nom d'hôte distinct, n'utilisant pas de cookies. On augmente ainsi la performance en diminuant la taille des requêtes HTTP pour ces ressources.
L'image ci dessous montre une capture de trafic lors du chargement d'un site suédois connu et comment les requêtes sont réparties sur différents noms d'hôtes.
Como siempre que se enfrentan distintos problemas, la gente consigue reunir distintas técnicas para solventarlos. Algunas técnicas son inteligentes y muy útiles, otras son trampas horribles.
Spriting es el término que describe la técnica de unir varias imágenes pequeñas, en una única imagen más grande. Más tarde a través de CSS o Javascript, se recortan ciertos pedazos de la imagen grande para ir mostrando las imágenes más pequeñas.
Un sitio web usaría este truco por velocidad. En HTTP 1.1, descargar una única imagen grande es mucho más rápido que descargarse individualmente 100 pequeñas.
Por supuesto que tiene ciertas desventajas en sitios web donde sólo se quieren mostrar uno o dos imágenes pequeñas. De la misma manera, todas las imágenes serán descartadas de la cache al mismo tiempo, en lugar de las imágenes que sean más utilizadas.
Inlining es otro truco para evitar enviar imágenes individuales, cosa que se consigue utilizado URLS “data:” desde un fichero CSS. Tiene beneficios e inconvenientes similares al caso de “spriting”.
Un gran sitio web puede tener un montón de ficheros javascript diferentes. Ciertas herramientas de front-end ayudan a los desarrollares a juntar todos ellos en un único paquete gigante de manera que el navegador deberá descargar un único fichero en lugar de docenas de ficheros más pequeños. Se envía mucha información cuando se necesita poca. Un único cambio, fuerza el refresco de mucha información.
La mayoría de las veces, esta técnica es un inconveniente para los desarrolladores implicados.
El truco de rendimiento final que mencionaré es denominado a menudo fragmentación (“sharding”). Básicamente se basa en servir distintos elementos de tu servicios desde el mayor número de servidores posible. En un primer vistazo puede parecer extraño, pero hay algo razonable detrás de todo ello.
Inicialmente la especificación HTTP 1.1 fijaba que un cliente tenía permitido utilizar un máximo de dos conexiones TCP para cada dominio. Para conseguir no saltarse la especificación, ciertos sitios astutamente se intentaron nuevos nombre de dominio y – voilá – ya disponían de más conexiones de manera que descendían los tiempos de carga.
Con el paso del tiempo, se ha eliminado dicha limitación y los clientes actuales utilizan fácilmente 6-8 conexiones por nombre de dominio, contando con esta limitación, algunos sitios siguen utilizando esta técnica para aumentar el número de conexiones. A medida que el número de objetos ha ido aumentando – como he mostrado anteriormente – utilizar un alto número de conexiones asegura que HTTP rinde bien y hace que tu sitio sea rápido. No es inusual que un sitio web utilice más de 50 o incluso se llegue casi a 100 conexiones en un sitio web utilizando esta técnica. Estadísticas recientes de httparchive.org muestran que las primeras 300.000 URLs del mundo, necesitan una media de 40(!) conexiones TCP para mostrar una página, y la tendencia parece ir incrementando lentamente en el tiempo.
Otra razón es poner las imágenes y otros recursos similares en otro nombre de dominio que no utilice ninguna cookie, ya que el tamaño de las cookies es bastante significativo. Utilizar imágenes sin cookies puede mejorar el rendimiento simplemente consiguiendo ¡peticiones HTTP mucho más pequeñas!
La imagen abajo muestra una traza para una petición de uno de los sitios principales de Suecia, de manera que las peticiones se distribuyen en diferentes nombres de dominio.
Il curl project ha fornito supporto sperimentale ad http2 a partire da Settembre 2013.
Nello spirito di curl, abbiamo intenzione di supportare praticamente ogni singolo aspetto di http2. curl è spesso usato come tool di test per interagire in maniera flessibile con i siti web, dunque vogliamo mantenere lo stesso per http2.
curl utilizza la libreria separata nghttp2 per poter offrire funzionalità a livello di frame. curl necessita di nghttp2 1.0 o superiore.
Notate che al momento su linux, curl e libcurl non sono sempre distribuiti con il supporto HTTP/2 abilitato.
Al suo interno, curl converte gli headers entranti http2 in headers stile HTTP 1.x presentandoli all'utente e facendoli apparire molto simili ai pre-esistenti HTTP. Ciò permette una transizione facilitata per tutti gli strumenti che usano curl e HTTP oggi. In modo simile curl convertirà gli header uscenti con lo stesso stile. Passateli a curl in stile HTTP 1.x e lui si occuperà di convertirli al volo durante il dialogo con server http2. Questo permette agli utenti di non doversi occupare troppo di quale particolare versione di headers HTTP si stia usando.
curl supporta http2 su TCP standard attraverso l'header "Upgrade:". Se si esegue una richesta HTTP e si richiede HTTP 2, curl chiederà al server di aggiornare la connessione a http2 ove possibile.
curl supporta un vasto numero di librerie TLS per il proprio back-end TLS, ed è ancora il caso con http2. La difficoltà per http2 utilizzando TLS è offirre buon supporto ALPN e talvolta NPN.
Lancia una build di curl con moderne version di OpenSSL o NSS per assicurare il support di ALPN e NPN. Se utilizzi GnuTLS o PolarSSL, avrai ALPN ma non NPN.
Per istruire curl ad utilizzare http2 -via plain-text o su TLS- utilizzare la opzione --http2 (meno meno http2). curl è ancora impostato per utilizzare HTTP/1.1 per default, quindi l'opzione è necessaria se desideriamo http2.
La tua applicazione continuerà ad utilizzare URL di tipo https:// o http:// ma dovrai anche settare la voce curl_easy_setopt CURLOPT_HTTP_VERSION a CURL_HTTP_VERSION_2 per far sì che libcurl provi ad utilizzare http2. Su base best-effort proverà ad utilizzare http2 altrimenti continuerà su HTTP 1.1.
Dato che libcurl prova a mantenere gli stessi comportamenti di sempre, dovrai abilitare il multiplexing HTTP/2 nella tua applicazione tramite l'opzione . In caso contrario, continuerai ad utilizzare una richiesta per volta per ogni connessione disponibile.
Altro piccolo dettaglio da tenere a mente quando si richiedono trasferimenti multipli via libcurl tramite la sua interfacia "multi", una applicazione potrebbe decidere di iniziare un numero infinito di trasferimenti simultanei; se desideriamo veicolarli tutti tramite la stessa connessione piuttosto che utilizzarne una moltitudine, possiamo istruire libcurl affinchè aspetti un determinato lasso di tempo utilizzando l'opzione .
libcurl 7.44.0 e successivi supportano la server push HTTP/2. Potrete trarne vantaggio impostando un callback tramite l'opzione Se l'applicazione accettase il push, utilizzerebbe un handler di tipo CURL easy per trasmettere il contenuto del trasferimento, così come avverrebbe in ogni altro caso.
어떤 문제에 직면할 때마다, 사람들은 차선책을 찾곤합니다. 몇몇 차선책들은 매우 유용한 반면, 어떤 것들은 완전히 쓸모없는 경우도 있습니다.
스프라이팅은 당신이 작은 이미지들을 모아서 하나의 큰 이미지를 만들때 이용되는 텀을 말합니다. 당신이 큰 이미지에서 각각의 작은 이미지들로 "cut out"하기 위해서 javascript나 CSS를 사용합니다.
사이트는 속도를 위해 이 트릭을 사용합니다. HTTP 1.1에서 커다란 이미지를 불러내는 것이 각각의 작은 100개의 이미지로 하나하나 가져오는 것보다 훨씬 빠릅니다.
물론 이 트릭은 단순히 한두 개의 작은 이미지나 비슷한 이미지를 노출시키고 싶을 때는 다소 불리한 점이 있습니다. 또한 이것은 모든 사진들을 보편적으로 사용되는 것을 남겨놓는 대신에 같은 시각에 캐시된 것들로 부터 추출한다.
인라이닝은 각각의 이미지를 보내는 방식을 피하는 다른 트릭입니다, 그리고 이것은 데이터를 이용합니다: URLs에 CSS파일을 끼워넣습니다. 이것은 스프리이팅과 장단점이 비슷합니다.
큰 사이트는 결국 수많은 javascript파일을 갖게 될 수 있습니다. Front-end 툴은 개발자가 이런 javascript파일들을 거대한 하나의 덩어리로 병합할 수 있도록 도와줄 것이며 브라우져는 수십개의 작은 파일 대신 하나의 거대한 덩어리를 가져오게 될 것입니다. 적은 양만 필요한데도 너무 많은 데이터가 넘어갑니다. 변화가 필요할 때 너무 많은 데이터가 재실행 됩니다.
물론 이러한 것들은 개발자들에겐 불편한 것입니다.
마지막으로 "샤딩"이라는 트릭이 있습니다. 이것은 기본적으로 다른 호스트들에게 많은 서비스를 하는 것을 의미합니다. 언뜻보기에는 이상해 보일지 모르지만 이유가 있습니다.
초기의 HTTP 1.1 명세서는 클라이언트에게 허용되는 각 호스트의 TCP 연결의 숫자가 2개 까지라고 기술되어 있습니다. 그래서 규정 사항을 위반하지 않기 위해서 새로운 호스트 네임을 발명하고 -voilá- 더 많은 연결이 가능해졌으며 페이지가 로딩 되는 시간을 줄일 수 있었습니다.
시간이 지나고, 제한이 없어지고 나서 오늘날 클라이언트들은 각 호스트 이름마다 6-8개의 연결을 쉽게 이용하지만 그들은 아직도 제한 사항을 갖고 있었습니다. 오브젝트의 수는 점점 증가하고 있습니다 -전에 내가 본 것보다- 수많은 연결들이 당신의 사이트를 빠르게 만들기 위해서 HTTP 수행에 이용됩니다. 사이트를 이용하는데 50개에서 100개의 연결을 사용하는 것은 일반적이지 못한 방법입니다. 최근 httparchive.org에서 서술된 것을 보면 세계에서 상위 300K URL들은 평균적으로 40(!)개의 TCP연결을 필요로 하며, 이 동향은 시간이 지남에 따라 서서히 증가하고 있는 추세입니다.
다른 이유는 또한 분할된 호스트 네임에 있는 이미지나 비슷한 리소스는 어떤 쿠키도 사용하지 않습니다, 오늘날 쿠키의 크기는 굉장히 중요할 수 있습니다. 무료 쿠키 이미지 호스팅을 사용하여 당신은 때때로 훨씬 작은 HTTP 리퀘스트만을 허용함으로써 성능을 향상시킬 수 있습니다!
아래 그림은 스웨덴의 탑 웹 사이트를 브라우징 할 때 어떻게 패킷을 추적하는지와 어떻게 리퀘스트들이 몇 개의 호스트 네임에게 분배되는 지를 보여줍니다.
今こそ進化したプロトコルを作るべき時です。それは:
RTTの影響がより少ない
パイプライニングとヘッドオブライン・ブロッキング問題を解決する
ホストへの同時接続数を増やす必要性をなくす
既存のインターフェースや全てのコンテンツ、URIフォーマットやスキームを変更しない
IETFのHTTPbisワーキンググループで策定する
インターネットエンジニアリングタスクフォース(IETF)はインターネットで利用する技術の標準化を推進する組織です。ほとんどの場合プロトコルのレベルで作業しています。彼らはRFCの発行で広く知られています。RFCはTCP、DNS、FTPからベストプラクティス、HTTPやその他の派生プロトコルの仕様を定めていて、決して消えることはありません。
IETFの中で、特定の目標に限定して”ワーキンググループ”が組織されます。それらはガイドラインや成果物の範囲を定めた”憲章”を樹立します。誰でもディスカッションや事の成り行きに参加することができます。参加して発言した人は誰でも平等に成果に対して影響を及ぼすことができます。参加者は皆、一人の人間として扱われ、どの会社に所属しているかはほとんど意味を持ちません。
HTTPbisワーキンググループ(名前の由来は後で説明します)はHTTP 1.1仕様書を更新することを目標とし、2007年夏ごろに組織されました。このグループで次世代HTTPの議論が本格的に始まったのは2012年も終盤になってのことでした。HTTP 1.1の更新作業は2014年序盤に完了し、シリーズになりました。
最後のHTTPbisワーキンググループのインターロップミーティングは2014年6月にニューヨーク市で行われました。残りの議題やRFC発行のためのIETFにおける手順は次年度に持ち越されました。
HTTPの分野でのいくつかの大手プレイヤーはワーキンググループのディスカッションやミーティングには参加していませんでした。ここでは特にどの会社だとか、どの製品だとかに言及したりはしませんが、今日のインターネットにおけるアクターの中には、これらの会社が参加しなくてもIETFは正しい仕事をするだろうと自信があるようです。
グループはHTTPbisと命名されていますが、”bis”とはです。IETFではBisを仕様の更新や第二幕の時に接尾や名前の一部として使うことが一般的です。HTTP 1.1のときもこれに当てはまります。
はGoogleによって主導され開発されたプロトコルです。彼らは確かにSPDYをオープンにし、誰でも参加できるようにしました。しかし人気のあるブラウザーとユーザーの多いサービスを稼働させている巨大なサーバー群の両方を自らの制御下に置いている、という事実から恩恵を得ていたということは間違いありません。
HTTPbisグループがhttp2について作業を開始しようと決定した時、SPDYはそれ自身のコンセプトの正しさをすでに証明していました。それはインターネットにデプロイ可能であることを示していましたし、その性能を証明する数値も公開されていました。http2は、SPDY/3ドラフトにほんの少しの文字列置換を施したものをhttp2ドラフト-00として始まったのです。
プロトコルは受信者が不明なフレームタイプを持つフレームを受信した場合、無視することを要求しています。両エンドポイントはホップバイホップで新しいフレームタイプの使用をネゴシエートすることができます。それらのフレームはセッションの状態を変えることが許されておらず、フロー制御されません。
http2に拡張を許すかどうかはプロトコル策定中に賛成と反対の意見の間で揺れ動き長い時間議論されました。ドラフト12の後、振り子は再度振れ、拡張を許すことになりました。
拡張はプロトコルの一部ではなく、基本のプロトコル仕様とは別の文書で定義されます。この時点ですでに基本プロトコルに含める意図をもって2つのフレームタイプが議論されていましたが、おそらく最初の拡張となるでしょう。ここではこの2つのフレームを紹介します。というのはこれらはよく知られているということと、もともと”標準”フレームの扱いだったからです。
http2の普及が進むにつれ、HTTP 1.xの時よりもTCP接続がはるかに長く持続するだろうとする理由があります。クライアントは1接続で全て間に合わせなければならないので、その接続は潜在的にかなり長い間開かれている可能性があります。
これはHTTPロードバランサーに影響を与え、サイトがクライアントに別のホストに接続してほしいという状況が生まれる可能性があります。それは性能のためだけではなく、サイトがメンテナンスや似たような理由でダウンするときもそうです。
サーバーはそのような場合 (またはhttp2のALTSVCフレーム)を送信し、クライアントにオルタナティブサービスについて伝えます。別のサービス、ホスト、ポート番号を使って、同じコンテンツへ別のルートでアクセスするのです。
クライアントはオルタナティブサービスに非同期的に接続を試行し、うまくいったときだけそれを使うようにします。
Alt-Svcヘッダーによりサーバーは
これはそれなりに議論を生んだ機能です。このような接続は認証されたTLSではなく、”安全”だとはいえず、UIで鍵マークを使うことは出来ません。実際、ユーザーにこれは平文のHTTPではなく、日和見暗号だと伝えるすべはないため、一部の人々は強くこのアイデアに反対しています。
このフレームは、http2のエンドポイントが送信可能なデータがあるがフロー制御によって送信できない時に一度だけ送信します。背景にあるアイデアは、あなたの実装がこのフレームを受信した場合、あなたの実装が間違っている、または帯域を使い切れていないということを知ることができるというものです。
このフレームを拡張として扱うため削除される前のドラフト12からの引用です:
”BLOCKEDフレームは実験のためこのドラフトに導入されました。実験結果が有意義なフィードバックを示さない場合、削除される可能性があります。”
Il protocollo http2 impone che il ricevente sia obbligato a leggere e ignorare tutti i frame sconosciuti (riportanti un tipo di frame sconosciuto). Due estremi possono negoziare l'uso di nuovi tipi di frame su base hop-by-hop ma tali frame non hanno il permesso di cambiare stato, e il loro flusso non beneficerà di flow-control.
Il fatto che http2 possa supportare una estensione è stato dibattuto a lungo durante lo sviluppo del protocollo con opinioni variabili, pro e contro. Dopo la draft-12 il pendolo ha ocillato un ultima volta in favore delle estensioni.
Le estensioni non fanno parte integrante ma sono e saranno documentate all'esterno del documento che specifica i fondamenti di protocollo. Ci sono gia due nuovi tipi di frame per i quali viene discussa l'inclusione ufficiale, i primi frame ad essere spediti come estensioni. Li descriverò vista la loro popolarità e il loro precedente stato di frame "nativi":
Con l'adozione di http2 abbiamo ragione di sospettare che le connessioni TCP siano ben più lunghe, durevoli, e che saranno mantenute ben più a lungo rispetto alla durata media delle anziane connessioni HTTP 1.x. Un client dovrebbe essere in grado di fare praticamente tutto all'interno di una sola connessione per ogni host/sito; tale connessione potrebbe potenzialmente permanere aperta a lungo.
Questo fattore influenzerà il funzionamento dei load-balancers HTTP fino ad arrivare ad una situazione in cui sarà lo stesso sito a consigliare al client di riconnettersi attraverso un altro host, per motivi di performance, maintenance, etc.
Il server manderà un (o un frame ALTSVC in http2) istruendo il client a proposito del servizio alternativo: un'altra rotta verso lo stesso contenuto, rotta che però utilizza un servizio ed un numero di porta differenti.
Un client dovrebbe dunque provare a connettersi a tale servizio in maniera asincrona ed utilizzare tale alternativa solo in caso che la connessione abbia successo.
L'header Alt-Svc permette ad un server di contenuti via http:// di informare il client che lo stesso contenuto è disponibile anche attraverso una connessione TLS.
Questa è in qualche modo una feature discutibile. Tale connessione utilizzerebbe TLS non-autenticato e non sarebbe ritenuta "sicura" comunque, non essendo predisposta per avvertire in alcun modo l'interfaccia utente (UI) della disponibilità di una connessione cifrata. Oltretutto non avremmo modo di distinguere ove l'utente stia utilizzando il caro e vecchio HTTP. In effetti molti esperti sono ancora fermamente contrari a tale opportunismo in ambito TLS.
Si suppone che un frame di questo tipo sia inviato esattamente una sola volta da parte di un peer http2 quando esso dovesse avere dati da spedire, ma il flow- control glielo avesse impedito. In pratica, se la tua implementazione riceve un frame di questo tipo, evidenzierebbe un problema a livelo di configurazione e/o transfer-rate non ottimale.
Una citazione dalla draft-12, prima che questo frame diventasse una estensione a parte:
"Il frame BLOCKED è incluso in questa draft per facilitare la sperimentazione. Se i risultati non dovessero mostrare un vantaggio o miglioramento tale frame potrà essere rimosso"
El proyecto curl ha estado ofreciendo soporte experimental para http2 desde septiembre de 2013.
Siguiendo el espíritu de curl, pretendemos ofrecer todos los aspectos de http2 en la medida de nuestras posibilidades. Es un uso común de curl se usado como una herramienta de testeo, y una manera de “pingar” manualmente sitios web, y es nuestra intención mantenerlo igualmente para http2.
curl utiliza una librería externa nghttp2, para implementar la funcionalidad de la capa trama http2. curl necesita la versión nghttp2 1.0 o superior.
Actualmente en Linux, curl y libcurl no están siempre desplegados con el soporte activado para HTTP/2.
Internamente curl convertirá las cabeceras http2 al estilo de cabeceras HTTP 1.x, y serán entregadas al usuario, de manera que aparecerán de maneras similar al HTTP tradicional. Esto facilitará la transición a todos los usos actuales de curl. De manera similar, curl convertirá las cabeceras salientes con el mismo estilo. Serán pasadas en estilo HTTP 1.x y las convertirá al vuelo cuando se esté hablando con servidores http2. Esto permitirá que los usuarios no se preocupen demasiado sobre la versión HTTP en particular que esté siendo utilizada.
curl soporta http sobre TCP estándar utilizando la cabecera “Upgrade:”. Si realizas una petición HTTP solicitando http2, curl preguntará al servidor si es posible actualizar la conexión a http2.
curl tiene soporte para una amplia variedad de bibliotecas TLS distintas para su implementación TLS, y esto sigue siendo válido para el soporte http2. El desafío de TLS en el mundo http2, es el soporte APLN y en cierta medida el soporte NPN.
Compila curl con versiones modernas de OpenSSL o NSS, para obtener soporte APLN y NPN. Utiliza GnuTLS o PolarSSL y soportará ALPN pero no NPN.
Para indicar a curl que utilice http2, tanto e texto plano como sobre TLS, hay que utilizar la opción --http2 (Esto es “menos menos http2”). De momento curl por defecto ofrece HTTP/1.1 así que es necesario una opción extra cuando se quiere http2.
Tu aplicación utilizará URLs normales con https:// o http://, pero habrá que indicar el parámetro CURLOPT_HTTP_VERSION de curl_easy_setopt a CURL_HTTP_VERSION_2 para intentar que libcurl utilice http2. Intentará de la mejor forma conectar con http2, pero volverá a HTTP 1.1 si éste falla.
libcurl intenta mantener comportamientos existentes, por lo que se hace necesario que se active la multiplexación HTTP/2 en tu aplicación mediante la opción . De lo contrario se seguirá utilizando una petición en cada momento por conexión.
Otro pequeño detalle a tener en cuenta es que al solicitar varias transferencias al mismo tiempo con libcurl, usando su interfaz multiple, una aplicación puede empezar varias transferencias al mismo tiempo, y que si se pretende que libcurl espere e introduzca todas ellas por la misma conexión en lugar de abrir nuevas conexiones, existe la opción .
A partir de la versión libcurl 7.44.0 se da soporte para la funcionalidad HTTP/2 server push. Puedes utilizarla indicando un callback con la opción .
Si la aplicación acepta el push, se creará una nueva transferencia con un manejador fácil CURL, y se enviará contenido, como cualquier otra transferencia.
This is a detailed document describing HTTP/2 (RFC 7540), the background, concepts, protocol and something about existing implementations and what the future might hold.
The contents are translated into several different languages.
See https://daniel.haxx.se/http2/ for the canonical home for this project.
See https://github.com/bagder/http2-explained for the source code of all book contents.
The document is distributed under the Creative Commons Attribution 4.0 license:
I encourage and welcome help and contributions from anyone who may have improvements to offer. We accept , but you can also just file or send email to [email protected] with your suggestions!
/ Daniel Stenberg
El equipo de Chromium ha implementado y soportado http2 en sus canales dev y beta desde hace bastante tiempo. Desde Chrome 40, publicado el 27 de enero de 2015, http2 está activado por defecto para algunos usuarios. El número de estos, comenzó muy pequeño, y ha ido aumentado a lo largo del tiempo.
El soporte para SPDY será cancelado próximamente. En una entrada de blog, el proyecto anunció lo siguiente en febrero de 2015:
“Chrome ha soportado SPDY desde Chrome 6, pero al tener la mayor parte de las ventajas presentes en HTTP/2, es hora de decir adiós. Hemos planificado quitar el soporte para SPDY a comienzos de 2016”
Introducir “chrome://flags/#enable-spdy4" en la barra de direcciones del navegador y hacer click en “activar” (“enable”), si no está previamente activado.
Recordar que Chrome sólo implementa http2 sobre TLS. Únicamente se verá http2 en acción con Chrome, al visitar sitios con https:// que ofrezcan soportes http2.
Existen plugins de Chrome disponibles que ayudan a visualizar si un sitio está usando HTTP/2. Uno de ellos es .
Los experimentos actuales de Chrome con QUIC (ver sección 12.1), diluyen de alguna manera los número de HTTP/2.
http2は何を成し遂げたのでしょうか。HTTPbisはスコープの境界線をどこに引いたのでしょうか。
これらは極めて厳格であり、チームのイノベーションを厳しく制限するものでした。
HTTPのパラダイムを保持しなければなりません。TCP上でクライアントがサーバーにリクエストを送信する形のプロトコルなのです。
URLを変更することはできません。新しいスキームを導入することはできません。これらのURLを使うコンテンツは膨大であるため、変更することができないのです。
Le protocole HTTP 1.1 est omniprésent sur Internet. De nombreux investissements ont été réalisés sur des protocoles et infrastructures tirant profit de celui-ci. À tel point que lors de l'implémentation d'un nouveau projet, il est souvent plus facile d'utiliser HTTP plutôt que de développer un nouveau protocole.
Lors de la création de HTTP, il fut probablement perçu comme un protocole plutôt simple et évident, ce qui, avec le temps, s'est révélé faux. HTTP 1.0 spécifié dans la RFC 1945 est une spécification de 60 pages datant de 1996. La RFC 2616 qui décrit HTTP 1.1 a été publiée trois ans plus tard en 1999 et comprend 176 pages. Puis, quand nous, à l'IETF, avons mis à jour cette spécification, elle a été répartie en six documents, avec davantage de pages au total (RFC 7230 et associées). Tout bien considéré, HTTP 1.1 est dense et comporte une multitude de détails, subtilités et, non dans une moindre mesure, de très nombreux points optionnels.
HTTP 1.1 은 거의 모든 인터넷에서 사용되는 범용적인 프로토콜이 되었습니다. 프로토콜과 사회 기반으로 만들어져온 거대한 투자들은 프로토콜과 사회 기반 시설을 통해 만들어져 왔습니다. 그 연장선으로 생각 해볼 때 오늘날에는 아예 새로운 것을 만들어 내는 것보다, HTTP위에서 만들어내는 것이 더 쉽다고 볼 수 있습니다.
HTTP가 처음 탄생되어 세상에 알려졌을 때 많은 사람들은 그저 단순하고 직선적인 프로토콜로 인식되었습니다. 하지만 시간이 지나면서 그것이 틀렸다는 것이 증명되었습니다. RFC 1945에서의 HTTP는 1996년에 기술된 60페이지 분량의 문서입니다. HTTP1.1이 기술된 RFC 2616은 1999년에서 불과 3년이후 176페이지로 상당한 분량으로 확대되어 발표 되었습니다. 아직 IETF에 맞춰 업데이트를 할 때, 6개 문서로 분할 변환 되었고, 훨씬 많은 분량이 되었습니다.(결과적으로 RFC 7230과 가족이 되었습니다.) 어떤 통계에 의하면 HTTP 1.1은 크고 수많은 상세 설명을 포함하고 있고,수많은 파트가 존재합니다.
HTTP 1.1 si è trasformato in un protocollo utilizzato (virtualmente) per qualsiasi scopo su Internet. Grandi investimenti sono stati fatti su questo protocollo e su infrastrutture che possano trarre beneficio da quest'ultimo, al punto che ad oggi è più semplice appoggiarsi ad HTTP piuttosto che creare da zero qualcosa di nuovo.
Al tempo in cui HTTP fu concepito e messo a disposizione dell'umanità, fu più probabilmente percepito come un protocollo semplice e diretto; tale teoria è stata poi negata nel corso del tempo. La RFC 1945 del 1996 su HTTP 1.0, consta di 60 pagine. La RFC 2616 che descrive HTTP 1.1 -rilasciata solo tre anni dopo, nel 1999- conta ben 176 pagine. Ebbene, quando la IETF ha approciato il lavoro sull'aggiornamento delle specifiche ha sentito il bisogno di suddividere il documento in sei parti, risultando così in un conteggio di pagine ancora più elevato (vedi RFC 7230 e correlate). In parole povere, HTTP 1.1 è IMMENSO ed include una miriade di dettagli, sottigliezze e -non meno importante- un elevato numero di parti opzionali.
HTTP 1.1はインターネット上で広く何にでも使われるプロトコルになりました。このような世界で優位に立つためプロトコルやインフラストラクチャーに多大な投資がなされてきました。それにより、今日では自ら全く新しいものを作り上げるよりはHTTPの上で行うほうが簡単なのです。
HTTPが生まれた時、それはどちらかというと簡素で直截なプロトコルであると受け取られていました。しかし歴史はそれを否定しています。1996年発行のRFC 1945ではHTTP 1.0は60ページの仕様書で定義されていました。HTTP 1.1を定義するRFC 2616は3年後の1999年に発行されましたが、176ページにまで膨れ上がりました。さらに我々がIETFにおいてRFC 2616を更新した際、6冊の文書に分割され(RFC 7230からRFC7235)、合計ではページ数は増加しています。どれをとってもHTTP 1.1は巨大であり、必須ではないたくさんのオプショナルな箇所は言うに及ばず、詳細で細かすぎてわからない規定がてんこ盛りなのです。
http2로 무엇을 이룰 수 있을까요? HTTPbis 그룹이 시작한 일이 무엇인지에 대한 경계는 어디일까요?
경계는 사실상 상당히 엄격했으며, 팀 능력 향상, 동기부여의 가능성을 방해하는 구속의 역할을 했습니다.:
http2 패러다임을 유지한다. 이것은 아직 client가 TCP server에 requests를 보내는 프로토콜의 형태를 띄고있습니다.
http:// and https:// URLs 은 변할 수 없다. 그것을 위한 새로운 scheme 같은 것은 없다. URLs같은 것들을 이용하는 모든 콘텐츠는 바꾸기엔 너무나도 많은 예외처리를 해주어야하기 때문입니다.
Quando si trovano faccia a faccia con questo tipo di problema, le persone si ritrovano e cercano una scappatoia. Alcune di queste soluzioni saranno intuitive ed intelligenti, altre orrendi accrocchi.
"Spriting" è il termine usato per descrivere la tecnica che combina immagini multiple in un'unica immagine piu ampia. Attraverso JavaScript o CSS si può in seguito provare a decomporre l'immagine riassemblata nei singoli componenti.
Un sito utilizzerà spesso questa astuzia per migliorare la percezione di velocità. Acquisire una singola grande immagine in HTTP 1.1 è molto più veloce che richiedere 100 minuscole immagini separate.
Dunque, che innovazione porta http2? Fino a che punto si spingono i limiti imposti dal gruppo HTTbis ?
I confini sono abbastanza limitati e pongono al team molte restrizioni sull'abilità di innovare.
http2 deve mantenere i paradigmi HTTP. Rimane un protocollo in cui un client manda una richiesta ad un server via TCP.
gli URL http:// e https:// non possono essere modificati. Non può esistere un nuovo schema. La quantità di contenuti che utilizzano tali URL è troppo grande per pensare ad un cambiamento.
Firefoxはとても緊密にドラフトに追随していて、何ヶ月もの間http2テスト実装を提供してきました。 http2プロトコルの開発中、クライアントとサーバーはどのドラフトバージョンを実装しているかについて合意する必要があり、テストを行うときに若干厄介でした。クライアントとサーバーがそれらの実装するプロトコルドラフトが何なのか合意しているか気を付けてください。
2015年1月13日にリリースされたFirefox 35から、http2サポートがデフォルトで有効になっています。
アドレスバーに'about:config'と入力し、”network.http.spdy.enabled.http2draft”という名前のオプションを探してください。それがtrueになっているか確認してください。Firefox 36は”network.http.spdy.enabled.http2”という名前の別のオプションを導入し、デフォルトでtrueに設定されています。後者はhttp2”標準”バージョンを制御するのに対し、前者はドラフト時代のhttp2バージョンのネゴシエーションを有効/無効化します。両方ともFirefox 36からデフォルトでtrueになっています。
.icon1 {
background: url(data:image/png;base64,<data>) no-repeat;
}
.icon2 {
background: url(data:image/png;base64,<data>) no-repeat;
}그 후, proxy들은 http2 features 와 HTTP 1.1 clients간의 1 대 1 관계를 만들 수 있어야 합니다.
프로토콜에서 오는 선택 사항들을 없애거나 줄여야 합니다. 이것들은 요구사항이 아니지만 SPDY와 Google팀 으로부터 나온 mantra 입니다. 모든 것을 마킹하는 것은 필수적이며 당신이 구현하지 못할 상황에 빠지거나 나중에 함정에 빠지는 상황이일어나지 않게 해줄것입니다.
더 이상 이전버전은 없다. 이것은 clients와 server가 http2에 호환되거나 그러지 그렇지 않거나를 결정 짓는데에서 도출된 결과입니다. 만약 프로토콜의 확장이나 수정에 대한 필요성이 대두된다면, http3가 탄생하게 될 것입니다. 적어도 http2에서 이전 버전은 존재하지 않습니다.
앞서 언급했지만, 현존하는 URI schemes 는 수정될 수 없습니다, 그래서 http2를 사용해야합니다. HTTP 1.x 버전을 사용하게 된 이후로 오늘날 까지, 우리는 확실히 http2 에서 프로토콜에 대한 업그레이드가 있어야 한다고 생각습니다. 아니면 낡아빠진 프로토콜 대신 서버가 http2를 사용하도록 해야했습니다.
HTTP 1.1 은 이 작업을 수행하기 위해서 정의된 방법이 있는데, 업그레이드: 헤더라고불리는 낡은 프로토콜로 보내진 리퀘스트를 받으면 자동으로 새로운 프로토콜 응답으로 반환하는 방법입니다.
왕복 패널티는 SPDY팀이 받아들일 만한 문제가 아니었으며, 그들은 SPDY를 TLS에서만 구현하고 있었기 때문에, 그들은 협상을 단순화 하는 TLS의 확장판을 개발해내었습니다. 이 NPN(Next Protocol Negotiation이라고 부른다.) 확장판을 이용하면, server는 자신이 알고있는 프로토콜을 이용해서 client를 호출하며 client는 이 프로토콜을 받을 수 있습니다.
수많은 http2의 초점은 TLS에서 적절하게 동작하는 것이었습니다. SPDY는 TLS가 필요하며, http2에서 사용하도록 TLS 를 크게 밀어주는 경우도 있었습니다, 하지만 이는 합의점을 찾지 못했고 결국 TLS는 http2에서 필요없게 되었습니다. 그러나 현대의 흐름을 주도하는 두 웹브라우저인 Google Chrome 과 Mozilla Firefox 개발진들은 TLS에서 http2를 구현했다고 말했습니다.
TLS-only 방식을 선택하게 된 이유로는 사용자들의 프라이버시와 새로운 프로토콜이 TLS와 함께 이용될 때 더 높은 성공률을 보인다는 것이 일찍이 수치상으로 증명이 되었다는 두 가지 이유를 높이 샀기 때문입니다. 80번 포트를 지나가는 모든 HTTP 통신은 몇몇 중간 장치 통신을 방해하거나 해당 포트를 이용하여 다른 프로토콜을 보낼때 트레픽을 파괴하는 경우가 생깁니다.
TLS를 필수적으로 쓸 것인가에 대한 주제는 메일링과 미팅 자리에서 너무 많은 수필과 격양된 목소리(이게 좋은 것인가 나쁜것인가에 대한)가 오고 갔기 때문에 대두되었습니다. 혹시라도 이 주제에 대한 질문을 HTTPbis 참가자 앞에서 던질때는 조심해야할 필요가 있습니다.
비슷한 예로, http2 는 TLS 를 사용하는 경우 의무적으로 해야 암호 목록 을 지시해야 하는가에 대한 열띈 토론이 진행된 적이있습니다. 결국에 TLS는 1.2 버전 이후로 암호화 suite에 제한을 의무화 하기로 했습니다.
Next Protocol Negotiation (NPN)은 SPDY와 TLS서버의 협상에 이용되는 프로토콜입니다. 이것은 표준화되지 않았기 때문에, IETF에서 논의한 결과, ALPN: Application Layer Protocol Negotiation이 탄생하였습니다. SPDY client와 server가 NPN을 사용하는 동안 ALPN은 http2에서 사용하기 위해 지속적으로 추진되어왔습니다.
NPN가 먼저 존재하고 ALPN이 표준화를 통해서 이용된 사실은, http2 협상 때 수많은 http2의 server와 client의 구현과 두가지의 확장성을 이끌었습니다. 또한 NPN 는 SPDY 로 사용 되어 많은 서버 가 SPDY 와 http2 을 모두 지원 하기 때문에 NPN 과 ALPN 을 이 서버 에서 지원 하는 것은 의미가 있습니다.
ALPN과 NPN간의 차이는 어떤 프로토콜을 이용할 것인지 결정하는 것에 있습니다. ALPN은 client가 server에게 우선순위로 나뉘어 정렬된 프로토콜 리스트를 보내고 서버는 그중에서 원하는 것을 선택합니다, 반면 NPN은 client가 최종 결정을 합니다.
앞서 언급한 바와 같이, 일반 텍스트 HTTP 1.1 은 http2를 협상하기 위해서 Upgrade된 header를 보냅니다. 만약 server가 http2를 말한다면, "101 Switching" status 코드를 반환하고 http2로 스위칭시켜 연결할 것입니다. 물론 이 업그레이드 절차는 풀 네트워크 라운드트립을 필요합니다, 하지만 http2의 장점은 훨씬 더 오랫동안 연결을 유지할 수 있다는 것이며, HTTP1 여결보다 재사용성에 있어서 더 뛰어난 성능을 보여줍니다.
몇몇 브라우저들은 이런식으로 http2를 구현하지 않는다고들 하지만, 인터넷 익스플로러 팀은 그 반대의 의견을 갖고있으며 curl은 이미 그것들을 지원하고 있습니다.
servers e clients HTTP1 esistono da decadi, dobbiamo essere in grado di "proxyficare" (traghettare, incapsulare) tutto verso servers http2.
di conseguenza un proxy deve essere capace di mappare le features di http2 uno-a-uno su un client HTTP 1.1.
Rimuovere o ridurre parti opzionali del protocollo. Non esattamente un requisito ma piuttosto un mantra proveniente dalla filosofia SPDY e dal team Google. Se si fa in modo che tutto sia obbligatorio fin da subito non si arriverà mai ad "implementare oggi" senza cadere in un possibile bug domani.
Basta con le versioni minori. È stato deciso che i client ed i server o sono compatibili con http2 oppure no, in maniera assoluta. Se ci sarà bisogno di estendere il protocollo o modificare le cose, http3 prenderà forma. Non ci sono più versioni intermedie in http2.
Come gia detto, gli schemi URI esistenti non possono essere modificati, dunque http2 deve utilizzare gli esistenti. Visto che sono utilizzati per HTTP 1.x ad oggi, abbiamo necessariamente bisogno di una maniera per upgradare il protocollo ad http2, o altrimenti domandare al server di utilizzare http2 piuttosto che protocolli precedenti.
HTTP 1.1 possiede gia un modo di procedere a tale upgrade; l'omonimo header "Upgrade:" permette al server di inviare una risposta utilizzando il nuovo protocollo ogni volta che ricevesse una richiesta sul vecchio, al costo di un solo round-trip aggiuntivo.
La penalità imposta da tale round-trip non era una condizione che il team SPDY avrebbe potuto accettare, e visto che hanno implementato SPDY solo su TLS, hanno sviluppato una nuova estensione TLS che raccorcia la nettamente la negoziazione. Utilizzando questa estensione detta NPN (Next Protocol Negotiation) il server istruisce il client a proposito di quali protocolli siano di sua conoscenza e lascia al client la libera scelta fra quelli supportati.
Molta attenzione è stata messa per far si che http2 si comporti degnamente su TLS. SPDY necessita di TLS, di conseguenza si è attuata una discreta pressione per rendere TLS obbligatorio per http2, ma infine tale mozione non ha ricevuto il consenso dunque per http2, TLS rimane opzionale. Ciononostante, due dei partecipanti hanno chiaramente espresso la volontà di implementare http2 esclusivamente su TLS: i capi di Mozilla Firefox e Google Chrome, due dei principali browser esistenti.
Le ragioni per propendere per il TLS-esclusivo includono sicuramente il rispetto della privacy dell'utente e le misurazioni iniziali, che hanno mostrato come http2 abbia un tasso di successo superiore quando in presenza di TLS. Ciò a causa del fatto che molte box intermedie (router, firewall etc) sono convinte che tutto ciò che passa per la porta 80 sia sempre e solo traffico HTTP 1.1, il che crea interferenze e drop in caso si cerchi di utilizzare un altro protocollo.
Tale argomento (TLS obbligatorio) ha causato svariati disaccordi sulle mailing lists e durante gli incontri - è buono o cattivo ? Rimane un giudizio controverso - attenzione a non tirare fuori questo argomento davanti ad un membro della HTTPbis !
Un altro estenuante dibattito ha avuto luogo, riguardo alla decisione se http2 debba o meno fornire una lista dei cifrari che dovrebbero obbligatoriamente essere impiegati durante un dialogo TLS, o se almeno dovesse fornire una blacklist, o se invece non dovesse richiede assolutamente nulla a livello di TLS, lasciando tale decisione al gruppo di lavoro TLS. Risultato del dibattito, la specifica detta una versione minima di TLS 1.2 e menziona restrizioni rispetto agli algoritmi di cifratura.
NPN (Next Protocol Negotiation) è il protocollo impiegato per negoziare SPDY quando si ha a che fare con server TLS. Visto che non era un vero e proprio standard, è stato incorporato per mano della IETF fino ad arrivare a diventare ALPN: Application Layer Protocol Negotiation. L'uso di ALPN è incoraggiato (richiesto) da http2, mentre SPDY rimane basato su NPN.
Il fatto che NPN esistesse gia da prima e che poi ALPN abbia preso forma tramite standardizzazione, ha fatto sì che diversi clients e servers abbiano implementato (e pretendano di utilizzare) entrambe le estensioni in presenza di http2. Inoltre come se non bastasse, NPN è utilizzato da SPDY, molti server supportano sia http2 sia SPDY: è dunque logico che tali server supportino entrambi, NPN e ALPN.
ALPN è diverso da NPN principalmente rispetto a chi prenda la decisione sul protocollo da adottare durante un dialogo. Con ALPN, il client fornisce al server una lista di protocolli che è in grado di supportare, in ordine di preferenza; il server si occupa poi di scegliere quelle che preferisce, mentre in NPN è il client che prende tale decisione finale.
Come detto prima, per negoziare http2 sul vecchio HTTP/1.1, dobbiamo inviare il famoso header "Upgrade:". Se il server parla http2, risponderà con un messaggio di stato "101 Switching" e da quel momento in poi tenterà di parlare solo http2 nel contesto di quella connessione. Di certo, questa procedura di upgrade ci costa un intero round-trip ma il vantaggio è che poi è possibile mantenere e riutilizzare una connessione http2 per molto più tempo rispetto ad una tipica HTTP/1.1 vecchio stile.
Mentre un portavoce di una casa produttrice di browser ha annunciato di non voler implementare questa maniera di parlare http2, il team di Internet Explorer ha affermato di volerlo fare, benchè poi non abbiano mai mantenuto la promessa. Solo curl e pochi altri non-browsers supportano http2 in clear-text.
Ad oggi, nessuno dei maggiori browser supporta http2 al di fuori di TLS.
そして、プロキシーはhttp2の機能をHTTP 1.1クライアントへ1:1で対応させなければなりません。
プロトコルからオプショナルな部分を削除するか削減する。これは要求ではありませんが、SPDYやGoogleチームからやってきた信条のようなものです。すべてを必須にしてしまえば、今実装できないなため後で罠にはまる、といったようなことが起こりえないのです。
マイナーバージョンを廃止します。クライアントとサーバーはhttp2に対応するか、対応していないかのどちらかです。プロトコルを拡張あるいは変更したいという要求が出た場合は、それはHTTP 3の出番です。http2にはマイナーバージョンはありません。
以前に述べた通り、既存のURIスキームは変更することができないので、http2は既存のものを使わなければなりません。これらはHTTP 1.xで今日使われているため、プロトコルをhttp2へアップグレードする、あるいはサーバーに古いプロトコルではなくてhttp2を使ってくださいとお願いする必要があります。
HTTP 1.1はこのためのUpgradeヘッダーという機構を備えています。古いプロトコルでこのようなリクエストを受けた場合、サーバーが新しプロトコルで応答を返すというものです。しかしラウンドトリップのペナルティを受けます。
SPDYチームはラウンドトリップのペナルティを受け入れることができませんでした。彼らはSPDYをTLS上でのみ実装していたので、ネゴシエーションを大幅に簡略化するTLS拡張を開発しました。この拡張、Next Protocol Negotiation(NPN)を使うと、サーバーは、それがサポートするプロトコルをクライアントへ通知し、クライアントがプロトコルを選択することができます。
http2ではTLS上で適切に振る舞うように随所で配慮がなされました。SPDYはTLSが必須でしたし、http2ではTLSを必須にしようという大きな後押しがありました。しかしコンセンサスが得られず、http2ではTLSは必須ではなくなりました。しかしながら今をリードする2つのwebブラウザー、Mozilla FirefoxとGoogle Chromeの開発者はhttp2をTLS上でのみ実装すると明言しました。
TLSを選択する理由には、ユーザーのプライバシーを尊重するということと、新しいプロトコルを導入する際はTLSを使うほうが高い成功率があったという実測結果の存在がありました。80番ポートを通過するものはすべてHTTP 1.1であるという広く信じられている前提があり、中間装置によっては通信を妨害したり遮断したりして、他のプロトコルが機能することを妨げるのです。
TLSを必須にするかどうかは、メーリングリストやミーティングで根強い反対意見が寄せられました。これは善なのか悪なのか、ということです。これは呪われた議題です。HTTPbis参加者に向かってこの質問をするときは注意してください。
同様にhttp2はTLSを使用する場合の必須暗号化スイートのリストを宣言すべきかどうか、あるいは、使用できないものをブラックリストにすべきか、いやいや、TLS"層"に要求することはせず、すべてTLS WGに任せようではないか、といった白熱した議論がかわされました。最終的にはTLS 1.2以上を必須とし、暗号化スイートに制限を付ける、ということになりました。
Next Protocol Negotiation(NPN)はTLSサーバーとSPDYをネゴシエートするプロトコルです。それは標準化されていなかったので、IETFで議論した結果、Application Layer Protocol Negotiation(ALPN)が生まれました。ALPNはhttp2で使われることになり、SPDYクライアントとサーバーはNPNを使い続けています。
NPNのほうが最初に登場したこと、またALPNが標準化に時間を取られたこともあって、初期のhttp2クライアントとサーバー実装はhttp2をネゴシエートする時に両方の拡張を使うようになりました。またNPNはSPDYで使用されていて多くのサーバーがSPDYとhttp2を両方サポートすることから、NPNとALPNをこれらのサーバーでサポートすることは理にかなっています。
ALPNとNPNの主たる差異はどちらがプロトコルを選択するかということです。ALPNではクライアントがサーバーに優先度の高い順にソートしたプロトコルのリストを渡し、サーバーがその中から選択しますが、NPNではクライアントが最終的な決定をします。
先に述べたとおり、平文HTTP 1.1においてhttp2をネゴシエートするにはサーバーにUpgradeヘッダーを送信します。サーバーがhttp2をサポートするなら、”101 Switching”ステータスを返し、その接続においては以後http2を使用します。もちろんこのアップグレード手順はネットワークの完全な1ラウンドトリップを必要とします。しかし利点としてはhttp2は永続的接続であり一般的にHTTP 1接続よりも多くの部分を再利用可能です。
いくつかのブラウザーベンダーはこの方法でのhttp2の使用を実装しないと言っていますが、Internet Explorerチームは実装する意思を示していて、またcurlはすでにサポートしています。
Entonces, ¿qué consigue http2? ¿Donde está el límite para lo que el grupo HTTPbis tiene encargado hacer?
Eran en realidad bastante estrictos y dejaban muy poca oportunidad para la capacidad de innovación dentro del equipo.
Tiene que mantener los paradigmas HTTP. Se mantiene como un protocolo que envía peticiones al servidor a través de TCP.
Las URLs http:// y https:// no pueden ser cambiadas. No puede existir un nuevo esquema para esto. La cantidad de contenido usando estas URLs es demasiado grande para pretender que cambie.
Servidores y Clientes HTTP1 se mantendrán durante décadas, deberemos ser capaces de hacer un proxy hacia servidores http2.
Así pues, los proxies deberán ser capaces de mapear funcionalidades http2 a clientes HTTP 1.1 una a una.
Eliminar o reducir partes opcionales del protocolo. Esto no era tanto un requisito, como un mantra que llegaba desde SPDY y el equipo de Google. Asegurándote de que todo es obligatorio, no hay manera de que no implementes algo ahora que se convierta en una trampa más adelante.
No más versiones menores. Se decidió que tanto clientes como servidores serían o no compatibles con http2. Si aparece una necesidad de extender el protocolo o modificar las cosas, entonces habrá nacido http3. No hay más versiones menores en http2.
Como se mencionado con anterioridad, los esxquemas de URI existentes, no podrán ser modificados, así que http2 deberá construirse usando los esquemas existentes. Como actualmente se están utilizando en HTTP 1.x, obviamente necesitamos una manera de actualizar el protocolo a http2 o solicitar al servidor de otra manera la utilización de http2 en lugar de protocolos más obsoletos.
HTTP 1.1 tenía una manera definida para hacer esto denominada la cabecera “Upgrade:”, que permitía al servidor enviar una respuesta usando el nuevo protocolo al recibir ¡la a través del protocolo viejo. Todo con el coste de una petición (“round-trip”).
Esa penalización de un round-trip, no era algo aceptable por el equipo de SPDY, y ya que su implementación de SPDY únicamente funcionaba sobre TLS, desarrollaron una nueva extensión TLS utilizada para atajar la negociación de manera significativa. Utilizando esta extensión, denominada NPM (Next Protocol Negotiation), el servidor comunica al cliente que protocolo conoce, así el cliente puede proceder y utilizar su protocolo preferido.
Se ha prestado mucha atención para conseguir un correcto comportamiento de http2 sobre TLS. SPDY funciona únicamente sobre TLS y se ha intentado con mucha fuerza que TLS sea igualmente obligatorio para http2, pero no se ha conseguido un consenso así que http2 se ha publicado con TLS opcional. Aún así, dos de los fabricantes más destacados han dicho que únicamente implementarán http2 sobre TLS: la iniciativa Mozilla Firefox y Google Chome. Hoy por hoy, dos de los navegadores principales.
Las razones para escoger solo-con-TLS incluyen el respeto por la privacidad del usuarios y medidas precoces que mostraban un mayor índice de éxito en nuevos protocolos sobre TLS. Esto se debe a la suposición de cualquier tráfico por el puerto 80 es HTTP 1.1, de manera que cualquier dispositivo que intercepte el tráfico puede interferir y destruirlo cuando se trata de otro protocolo distinto a HTTP 1.1.
La obligatoriedad de TLS ha sido causa de mucho movimiento y voces agitadas en las listas de correo y las reuniones – ¿es bueno o es malo? Es un tema infectado – ¡ten esto en cuenta cuando se lo preguntes cara a cara a un miembro de HTTPbis!
De manera similar, ha habido un fiero y largo debate sobre si http2 debe imponer la lista de cifrados que deben ser obligatorios al usar TLS, o sobre si crear una lista negra de unos cuantos o si por el contrario no se debiera obligar nada a la capa TLS, y dejar la decisión al grupo de trabajo TLS. La especificación ha determinado que TLS debe ser al menos la versión 1.2, y ha impuesto algunas restricciones en el cifrado.
Next Protocol Negotiation (NPN), es el protocolo utilizado para negociar SPDY con servidores TLS. Como no se trataba de un estándar adecuado, fue llevado a la IETF y de aquello surgió ALPN: Application Layer Protocol Negotiation. ALPN es lo que se está promoviendo para ser usado con http2, mientras que los clientes y servidor SPDY seguirán utilizando NPN.
El hecho de que NPN estuviera primero y que ALPN haya tardado un poco en el proceso de estandarización, ha llevado a que muchos clientes y servidores http2 hayan implementado de forma prematura soporte para ambas extensiones para la negociación de http2. Igualmente como NPN se utiliza para SPDY y muchos servidores ofrecen tanto SPDY como http2, dar soporte tanto para NPN como ALPN tiene perfecto sentido.
La principal diferencia de ALPN respecto a NPN está en quién decide que protocolo hablar. Con ALPN el cliente le indica al servidor el listado de protocolos en el orden de preferencia, y el servidor escoge el que él quiere, mientras que con NPN es el cliente quien toma esa última decisión.
Como se ha mencionado brevemente con anterioridad, para HTTP 1.1 en texto plano, la manera de negociar http2 es solicitar al servidor mediante una cabecera Upgrade:. Si el servidor habla http2, responderá con un estado “101 Switching” y a partir de entonces hablar http2 en esa conexión. Por supuesto que te das cuenta que este procedimiento de actualización está costando un viaje de red “round-trip”, pero por otra parte la conexión http2 debería ser mantenida y reutilizada de manera más generalizada que las conexiones HTTP1.
Aunque algunos representantes de navegadores han declarado que no implementarán este modo de hablar http2, el equipo de Internet Explorer ha comunicado que ellos lo harán, así como curl, que ya soporta actualmente esta modo.
Que réalise http2 ? Quelles sont les limites imposées par le groupe HTTPbis ?
Elles sont plutôt strictes avec des contraintes.
il faut maintenir le principe de HTTP. C'est toujours un protocole où le client envoie une requête vers un serveur en TCP.
les URLs http:// et https:// ne doivent pas changer. Il ne faut pas de nouvelle méthode. Le contenu utilisant ces URLs est trop important pour s'attendre à ce que tout le contenu change de méthode.
clients et serveurs HTTP1 seront encore là pour des décennies, on doit pouvoir les faire basculer (“proxifier”) vers des serveurs http2.
en conséquence, les proxys doivent mapper les fonctionnalités http2 à 1:1 vis-à-vis des clients HTTP 1.1.
retirer ou réduire les composants optionnels du protocole. Ce n'est pas vraiment un pré-requis mais un principe venant de SPDY et des équipes Google. En s'assurant que tout est obligatoire, il n'y a pas de risques d'omettre d'implémenter quelque chose, puis de se retrouver piégé plus tard.
pas de versions mineures. Il est décidé que clients et serveurs sont compatibles http2 ou pas du tout. S'il faut modifier ou étendre le protocole, alors http3 sera défini. Il n'y aura pas de versions mineures en http2.
Comme mentionné, les formats d'URL existants ne peuvent pas être modifiées, http2 doit donc gérer les URI actuelles. Comme elles sont déjà utilisées en HTTP 1.x, on doit pouvoir mettre à niveau (“upgrader”) le protocole vers http2 ou demander au serveur d'utiliser http2 plutôt que les anciens protocoles.
HTTP 1.1 a défini un moyen de le faire, l'en-tête Upgrade:, qui permet au serveur de renvoyer une réponse avec le nouveau protocole quand la requête était envoyée avec un protocole plus ancien. Au prix d'un aller-retour (round-trip).
Le coût de cet aller-retour n'est pas quelque chose que l'équipe SPDY allait tolérer. Comme ils n'implémentaient SPDY qu'au dessus de TLS, ils ont développé une extension TLS permettant de raccourcir la négociation de façon drastique. Cette extension, appelée NPN pour Next Protocol Negotiation, permet au serveur d'indiquer au client quels protocoles il connaît, celui-ci choisissant alors d'utiliser celui qu'il préfère.
Une attention particulière a été portée au bon fonctionnement du protocole http2 en conjonction avec TLS. SPDY lui-même ne fonctionnait qu'au dessus de TLS, et nombreux sont ceux qui souhaitaient que http2 ne soit utilisé qu'avec TLS. Ces derniers n'ont pas réussi à obtenir un consensus, et l'utilisation de TLS n'est qu'optionnelle. Néanmoins, les équipes de deux des plus importants navigateurs actuels, Mozilla Firefox et Google Chrome, ont clairement fait savoir qu'ils n'avaient pas l'intention d'implémenter http2 sans TLS.
Les motivations pour imposer TLS impliquent le respect de la vie privée et les mesures montrant que le nouveau protocole avait plus de chances de succès avec TLS. En effet, il est couramment répandu que tout ce qui passe sur le port TCP 80 est du HTTP 1.1 et pas mal d'intermédiaires réseau interfèrent ou cassent le trafic quand d'autres protocoles sont utilisés.
Le sujet TLS obligatoire a causé pas mal d'agitation dans les meetings et mailing-list, est-ce bien ou mal ? C'est une question typiquement empoisonnée, attention quand vous abordez ce sujet avec un membre du groupe!
De même, il y eut un long débat pour savoir si http2 devrait forcer une liste obligatoire d'algorithmes de chiffrement (ciphers en anglais) avec TLS, ou en bloquer certains ou encore laisser cette tâche au groupe de travail TLS. La spécification indique finalement la version minimale TLS à utiliser, 1.2, et une restriction sur les algorithmes à utiliser.
Next Protocol Negotiation (NPN) est le protocole utilisé pour négocier l'usage de SPDY avec les serveurs TLS. Ce n'était pas un protocole standardisé, après passage à l'IETF, il devint ALPN: Application Layer Protocol Negotiation. ALPN est promu pour son utilisation en http2, tandis que les clients et serveurs SPDY continuent d'utiliser NPN.
Le fait que NPN arriva en premier et que la standardisation d'ALPN prit du temps, eut la conséquence d'avoir des clients et serveurs http2 implémentant les deux extensions pour négocier http2. Puisque NPN est utilisé dans SPDY et que de nombreux serveurs offrant SPDY et http2, supporter à la fois NPN et ALPN fait sens.
ALPN diffère de NPN sur qui décide du protocole à utiliser. Avec ALPN, le client indique au serveur la liste des protocoles et ses préférences, le serveur obtient le dernier mot. Au contraire avec NPN, c'est le client qui impose son choix.
Comme indiqué précédemment, en HTTP 1.1 et en clair, la façon de négocier du http2 est de le demander au serveur avec l'en-tête Upgrade:. Si le serveur parle http2, il répond avec le code "101 Switching" et passe en http2 pour cette connexion. Bien que cette procédure d'upgrade coûte un aller-retour réseau, elle peut être conservée et réutilisée de manière bien plus efficace qu'une connexion HTTP1, amortissant ainsi le coût initial.
Même si certains porte-paroles de navigateurs ont indiqué qu'ils n'implémenteraient pas cette méthode, l'équipe d'Internet Explorer le fera, et curl la supporte déjà.
De par sa nature, HTTP 1.1 possède plusieurs options et petits détails permettant l'ajout d'extensions ultérieures. Ce qui a mené à un écosystème logiciel où aucune implémentation n'a tout couvert (encore faut-il définir ce que "tout" représente). Cela a mené à un cercle vicieux où les fonctionnalités peu utilisées ont été peu implémentées ce qui en limitait l'utilité pour ceux qui en faisaient usage.
Plus tard, cela a causé des problèmes d'interopérabilité entre clients et serveurs qui utilisaient certaines de ces fonctionnalités. Le pipelining HTTP en est un exemple parlant.
HTTP 1.1 a du mal à vraiment tirer parti de la puissance et des performances offertes par TCP. Les clients et navigateurs HTTP doivent être très créatifs pour trouver des solutions qui abaissent les temps de chargement de pages web.
D'autres expérimentations menées en parallèle à travers les années ont confirmé qu'il est difficile de remplacer TCP et qu'il fallait donc améliorer à la fois TCP et les protocoles au-dessus.
En clair, TCP peut être utilisé à meilleur escient en évitant les pauses ou en utilisant certains moments pour envoyer et recevoir des données. Les chapitres suivants développeront ces points.
En regardant la tendance parmi les sites les plus importants sur le web aujourd'hui et ce que cela implique pour télécharger leurs pages d'accueil, une tendance se dégage. Au fil des années, le nombre de données à transférer a augmenté régulièrement pour atteindre et même surpasser 1.9Mo. Plus important encore, le nombre moyen de ressources distinctes (ou objets) va au-delà de la centaine pour afficher chaque page.
Le graphique ci-dessous montre que cette tendance date déjà et rien n'indique qu'elle s'inversera. On y constate l'évolution, sur les quatre dernières années, du volume de données (en vert) et du nombre moyen de requêtes (en rouge) pour le chargement des pages web les plus populaires au monde.
HTTP 1.1 est très sensible à la latence, en partie à cause du pipelining HTTP qui demeure problématique à un tel point qu'il est désactivé pour la plupart des utilisateurs.
Bien qu'on ait observé une augmentation de la bande passante depuis plusieurs années, la réduction de la latence n'a pas suivi la même évolution. Les liens à forte latence, comme les technologies mobiles, rendent l'expérience Web difficile même avec une connexion haut débit.
D'autres usages qui nécessitent une latence faible sont certains types de vidéos comme : la vidéo-conférence, le jeu en ligne ainsi que les flux vidéos générés en direct.
Le pipelining HTTP est une manière d'envoyer une requête additionnelle sans attendre la réponse de la requête précédente. C'est semblable à la file d'attente d'une caisse à la banque ou au supermarché. Vous ne savez pas si le client vous précédant est rapide ou s'il s'agit d'une personne qui prendra son temps. Ce phénomène décrit parfaitement le : “head-of-line blocking”.
Bien sûr, vous pouvez faire attention et choisir la file que vous croyez être la meilleure, et parfois vous pouvez en commencer une nouvelle, mais vous devez prendre une décision que vous ne pourrez plus changer par la suite.
Créer une nouvelle file joue sur les performances et les ressources disponibles, ce qui ne permet pas de créer de nouvelles files à l'infini. Il n'y a pas de solution parfaite.
Même aujourd'hui, en 2015, le pipelining HTTP est désactivé par défaut sur la plupart des navigateurs destinés aux ordinateurs personnels.
Plus de détails sur ce sujet peuvent être consultés dans l'entrée 264354 de la base de données Bugzilla de Firefox.
수많은 세부사항들과 차후에 확장 가능한 유효한 옵션들을 갖고 있는 HTTP 1.1의 본질은 이제껏 구현하지 못했던 거의 모든 것을 구현할 수 있는 에코시스템 소프트웨어로 성장했습니다- 그리고 사실상 "모든"이라는 것을 정의하는 것이 거의 불가능합니다. 따라서 초기에 사용되지 않았던 기능들은 거의 구현되지 않고 그들을 구현하였다고 해도 대부분 사용할 수 없는 상황이 된 것입니다.
이후, 이러한 특징을 사용하는 클라이언트와 서버가 늘어나기 시작하면서 호환성의 문제가 발생했습니다. HTTP 파이프라이닝이 대표적인 예입니다.
HTTP 1.1 TCP의 모든 장점과 능력, 그리고 퍼포먼스 등을 다루는 것이 어려웠습니다. HTTP 클라이언트와 브라우져들은 페이지 로딩시간을 줄이기 위해서 창의적인 해결책을 찾아야할 필요가 있었습니다.
수많은 시도들이 병행되었지만 TCP를 대체하는 일이 결코 쉽지 않다는 것을 알게되었고 결국 우리는 TCP와 프로토콜의 기능을 향상시키는 작업을 계속 했습니다.
간단히 말해서 TCP는 더 많은 데이터를 송수신 할 수 있었음에도 공간낭비 등을 막는데에 이용될 수 있었습니다. 다음장에서는 이러한 단점들에 대해 다룹니다.
오늘날 가장 인기있는 웹 사이트들 중 몇몇의 트랜드들을 보고 그들의 프론트 페이지를 다운받아 보면 분명한 패턴이 나타난다. 수년에 걸쳐 검색해야할 데이터의 양이 점차적으로 증가하여 1.9MB를 초과하게 되었다. 더 중요한 건 한 페이지를 표시하기 위해 평균적으로 100에 육박하는 개별 리소스가 요구되는 것입니다.
아래의 그래프를 보면, 트랜드는 계속되고 있어 당분간은 변화의 조짐이 보이지 않습니다. 아래 그래프는 세계에서 가장 인기있는 웹 사이트의 전송 크기의 성장률과 서버에서 이용되는 총 리퀘스트 수의 평균치의 변화를 최근 4년을 기준으로 나타내었습니다.
HTTP 1.1 은 대기시간에 굉장히 민감한데, 이는 HTTP 파이프라이닝이 아직도 수많은 사용자들이 스위치를 꺼놓은 상태로 놔둘만큼 많은 문제를 내포하고 있기 때문입니다.
우리는 몇 년에 걸처 사람들에게서 유용한 대역폭의 커다란 증가를 보았지만, 동일한 수준의 대기시간 감소율을 보지는 못했습니다. 최근 대부분의 모바일 기술들 처럼 대기시간이 오래걸리는 링크들은 훌륭한 대역폭 연결을 활용하더라도 빠른 속도를 체험하는 것을 매우 어렵게 합니다.
대기시간을 최소화 하여야하는 비디오나 화상회의, 게임 그리고 그와 비슷한 것들이 문제가 되고 있습니다.
HTTP 파이프라이닝은 이전에 보냈던 리퀘스트에 대한 리스폰스를 기다리는 동안 다른 리퀘스트를 보내는 방법 중 하나다. 이것은 은행이나 슈퍼마켓 카운터에서 계산을 기다리는 것과 비슷합니다. 당신은 그저 앞에 있는 사람이 계산이 빨리 끝날 손님인 것인지, 아니면 오래걸리는 성가신 사람인지 모를 뿐입니다: 이것이 헤드 오브 라인 블로킹입니다.
물론 당신은 라인피킹에 대해서 주의할 수 있고 당신이 정말 정확하다고 생각하는 것을 고를 수 있으며 심지어는 스스로 새로운 라인을 시작할 수 있습니다 하지만 끝내 당신은 결정하는 것과 그것이 당신이 라인을 스위칭하지 못하게 하는 것을 피할 수 없습니다.
새로운 라인을 만드는 것은 퍼포먼스와 리소스 패널티와 관련이 있습니다. 그래서 더 작은 라인의 숫자를 뛰어넘는 확장성을 갖지는 못 합니다. 이 문제에 대해 완벽한 해결책은 없습니다.
2015년 오늘날 대부분의 데스크탑 웹 브라우져들은 '파이프라이닝 사용안함'이 기본값으로 설정되어있습니다.
이 주제에 대한 부가적인 읽을 거리는 파이어폭스에서 그 예를 찾으실 수 있습니다. bugzilla entry 264354.
Alla luce della vastità di dettagli ed opzioni disponibili per estensioni future e dunque in perfetta relazione con la natura di HTTP 1.1, un vasto ecosistema software si è sviluppato; possiamo tuttavia notare come quasi nessuna implementazione implementi davvero tutto - ed è infatti quasi impossibile definire cosa questo "tutto" in effetti rappresenti. Questo ha fatto sì che certune caratteristiche (non utilizzate fin dall'inizio) non abbiano mai suscitato l'interesse di alcuni sviluppatori, e che di converso altri gruppi abbiano implementato esattamente tutte le funzioni, riscontrando però un basso utilizzo delle stesse.
Tutto ciò ha causato problemi di inter-operabilità, al momento in cui clients e servers hanno cominciato ad utilizzare sempre più estensivamente tali suddette caratteristiche ed estensioni. Il pipelining HTTP è un esempio principe di tale feature (e del suo stato di implementazione).
Per HTTP 1.1 non è stato facile arrivare a trarre pieno beneficio dalla potenza e dalle performances che TCP mette teoricamente a disposizione. Client e server HTTP devono essere creativi per riuscire a diminuire il tempo di caricamento delle pagine.
Altri tentativi perpetrati in parallelo nel corso degli anni hanno confermato quanto il TCP non sia facilmente rimpiazzabile; si continua perciò a lavorare sul miglioramento del TCP e dei protocolli su di esso costruiti.
Mettiamola in termini semplici, il TCP può essere impiegato per evitare pause, intervalli o tempi morti in genere, frazioni di tempo che potrebbero altrimenti essere utilizzate per spedire e ricevere quantità di dati. Le sezioni seguenti evidenzieranno alcuni di questi prevedibili effetti.
Se osserviamo i trend per alcuni dei più popolari siti web odierni e quanto tempo prenda il download iniziale di tali "welcome pages" emerge chiaramente un pattern. Nel corso degli anni la quantità di dati di cui necessitiamo non ha fatto che aumentare verso e oltre gli 1.9MB. Cosa ancora più importante emerge da questo contesto: in media, più di 100 risorse individuali sono necessarie per visualizzare una determinata pagina.
Come mostra il grafico sotto, il trend è in corso da un pò di tempo e non mostra alcun segno di arresto o inversione sul breve periodo. Il grafico mostra la crescita della dimensione del trasferimento (in verde), il numero totale di richieste/risposte (in rosso) necessarie per servire il contenuto web dei siti più popolari al mondo, e come tali cifre si siano evolute nel corso degli ultimi quattro anni.
HTTP 1.1 è molto sensibile alla latenza, in parte perchè il pipelining HTTP non ha mai sufficientemente risolto i propri problemi, tanto da -infine- meritare la disattivazione presso la maggior parte dell'utenza.
Mentre abbiamo potuto osservare un enorme incremento di larghezza di banda disponibile "per utente" durante il corso degli ultimi anni, non abbiamo potuto osservare lo stesso incremento di prestazione volto a ridurre la latenza. Su link ad elevata latenza come ad esempio la maggior parte delle tecnologie mobili, è perciò difficile godere di buone prestazioni web pur disponendo di una connessione a banda larga.
Un altro use-case che richiede bassa latenza è il video, video conferencing, gaming e simili, là dove non vi è la necessità di inviare uno stream "prestabilito o ordinato".
Il cosiddetto "pipelining HTTP" è un metodo che permette di inviare una ulteriore richiesta mentre stiamo ancora aspettando la risposta alla domanda precendente. In un certo senso è come fare la coda alla banca o al supermarket: non sai in anticipo se la persona davanti si rivelerà essere un cliente veloce o uno di quei/quelle fastidiosi/e che impiegheranno un'eternità. Questo problema è noto come "head-of-line", inizio della coda (o della fila).
Certo, puoi provare a scegliere la fila che pensi essere la più rapida o potresti addirittura iniziarne una nuova tu. Alla fine, non possiamo evitare di prendere decisioni. Una volta compiuta la scelta non si puè più cambiare.
Creare una nuova coda è allo stesso tempo associato ad una penalità in termini di risorse e performance; non consiste dunque in una soluzione scalabile oltre ad un piccolo numero di code. Non esiste soluzione ideale a questo problema.
Ancora oggi, la maggior parte dei browser "desktop" ha scelto di mantenere il pipelining disattivato.
Ulteriori risorse sull'argomento disponibili ad esempio sul bugzilla bugzilla entry 264354 di Firefox.
HTTP 1.1の微に入り細に入る規定や後の拡張のためのオプションのお陰で、一つの実装で全てを実装する(「全て」が何を指しているかを定義することすら不可能なのですが)ことがほとんど不可能に近い状況でソフトウエアエコシステムを構築してきたのです。このため、初期にほとんど使われていない機能はほとんど実装されず、それらを実装したとしてもほとんど使われることがなかった、という状況に陥ったのです。
後になってクライアントとサーバーがそういう機能を使おうとすると相互接続性において問題が生じました。HTTPパイプライニングはそのような機能の代表例です。
HTTP 1.1でTCPのすべての能力を使いこなすのは困難でした。HTTPクライアントとサーバーはページロード時間を削減するための解決策を見出すためとても創造的になる必要がありました。
並行して行われてきた他の試みの結果、TCPを置き換えるのは容易ではないと分かったため、我々はTCPとその上のプロトコル両方を向上させることを続けたのです。
単刀直入にいって、TCPは何もしない時間を減らしてデータを送信、受信している時間を増やすほど効率よく使うことができます。続く節ではTCPの不適切な使い方の例をいくつか見ていきます。
今日で最も人気のあるいくつかのサイトの傾向とそれらのフロントページをダウンロードするために必要なことを注意深く見た時、明らかなパターンが浮上してきます。年を追うにつれてダウンロードしなければならないデータ量が徐々に増えていて、今日では1.9MBを超えました。この考察においてより重要なことは、平均で100個以上のリソースが1ページを表示するために必要だということなのです。
下の図が示す通り、この傾向はしばらく続いていて、近々変化するという兆しは見受けられません。下の図は世界において最も人気のあるWEBサイトをサーブするときの全体の転送サイズ(緑)、全リクエスト数の平均(赤)の増加、およびそれらが過去4年間でどのように変化したのかを示しています。
HTTP 1.1はレイテンシーにとても敏感です。HTTPパイプライニングが諸々の問題により大多数のユーザーにおいて無効化されていることもその理由の一つです。
我々は過去数年間において人々が帯域の大幅な増加を享受していることを見てきましたが、レイテンシーの削減においては同程度の向上が見られていません。レイテンシーが大きなリンク、例えば現在のモバイル技術の多くがそうです、においてはすばらしい高帯域の接続が利用できたとしても素早いwebの体験をすることはとても困難なのです。
低レイテンシーが切実に求められている他のユースケースは、映像配信、例えばビデオ会議、ゲームの類、であり、それらは単純に事前に用意したストリームを送信するだけではないのです。
HTTPパイプライニングは前のリクエストの応答を待っている間に次のリクエストを送信するというものです。これは銀行やスーパーマーケットのカウンターで列に並ぶことに似ています。あなたのひとり前の人が素早くすましてくれる人なのか、とても際限なく時間のかかる面倒な人なのかは知るよしもありません。これがヘッドオブライン・ブロッキングです。
確かに注意深く列を選ぶことで回避できるかもしれません。また時には自分で新しい列を作ることもできるでしょう。しかしこのような決断をするということ自体を避けることは不可能であり、一旦決断した後は列を変えることはできないのです。
新しい列を作ることは性能やリソース面において不利であり、比較的少ない数の列数を超えるとスケールしません。完璧な解決策は存在しないのです。
2015年の今日においてもほとんどのデスクトップwebブラウザーはHTTPパイプライニングを既定値で無効にしています。
これに関するさらなる情報については、例えばFirefoxのbugzilla entry 264354で得ることができます。
Lo "inlining" è un'altra tecnica utilizzata per evitare di spedire immagini individuali (tramite connessioni separate); tale tecnica consiste nell'utilizzare URL di tipo "data" incorporati nel CSS, con benefici e svantaggi simili al caso di "spriting" precedente.
Un sito abbastanza vasto può contenere numerosi file JavaScript differenti. Gli sviluppatori possono utilizzare dei cosiddetti "frontend" per concatenare -o combinare- molteplici scipts e far sì che il browser possa richiedere tutto iu un singolo grande file piuttosto che segmentando la richiesta su dozzine di file minuscoli. Molti dati sono inviati benchè ne possano servire meno, di conseguenza una quantita sempre maggiore di oggetti deve essere invalidata e "rinfrescata" al modificarsi di ogni singola risorsa inclusa (effetto negativo sulla cache).
Questa prassi è -ovviamente- un inconveniente per gli sviluppatori.
L'ultimo trick per incrementare le performance che citerò è spesso chiamato "sharding". In breve consiste nell'utilizzare il maggior numero di hosts per fornire un determinato servizio. Anche se a prima vista può sembrare strano vi è una ragione ben precisa dietro l'utilizzo di questa tecnica.
All'inizio le specifiche HTTP 1.1 dichiaravano che un client fosse autorizzato ad utilizzare un massimo di due [2] connessioni TCP per server/host; dunque per non violare le specifiche, gli sviluppatori hanno iniziato ad utilizzare alias e nuovi nomi alternativi -et voilà- molte più connessioni disponibili verso il proprio sito e maggior velocità di caricamento (page load, page speed).
Nel tempo la restrizione è stata rimossa; ad oggi un client utilizza facilmente dalle sei alle otto connessioni per nome-host. Sono tuttavia ancora limitate, perciò i siti continuano ad utilizzare questa vecchia tecnica per incrementare il numero di connessioni disponibili per ogni singolo client. Visto che il numero di oggetti richiesti via HTTP continua a crescere -come mostrato sopra- l'ampio ammontare di connessioni è utilizzato per garantire che HTTP continui a rispondere con prestazioni decorose, permettendo al sito di caricare velocemente. Non è infrequente per un sito utilizzare 50, 100 o più connessioni. Statistiche del httparchive.org mostrano come i top 300mila URL al mondo in media necessitino almeno di 40 (!) connessioni TCP ciascuno; tale trend sembra aumentare lentamente nel tempo.
Un altro scenario nel quale si può utilizzare lo sharding è l'hosting di immagini, appunto su macchine (hosts) separate, in modo da non dover utilizzare o memorizzare alcun cookie, tenendo ben presente che il volume dei cookie è anch'esso in aumento. Utilizzando hosts senza cookie associati permette di aumentare le performances semplicemente riducendo il volume della richiesta HTTP !
L'immagine qui sotto mostra una trace (packe capture) acquisita durante la navigazione su uno dei piu famosi siti Svedesi, e dimostra come le richieste siano distribuite su svariati hostnames.
Firefoxはhttp2をTLS上でのみ実装することを忘れないでください。Firefoxではhttps://のhttp2をサポートするサイトでのみhttp2は動作します。
http2が使われているかどうかを示すUIはありません。簡単にはわからないようになっています。確かめる一つの方法は、”Web developer->Network”を開いてレスポンスヘッダーを見て、サーバーが何を返しているかを見ることです。上のスクリーンショットに見るとおり、レスポンスは”HTTP/2.0”であり、Firefoxが”X-Firefox-Spdy:”という独自ヘッダーを挿入します。
ネットワークツールで見ることができるヘッダーはhttp2のバイナリーフォーマットから古いHTTP 1.xスタイルのヘッダーに変換されています。
サイトがhttp2を使用しているかどうかの可視化を手伝いするFirefoxプラグインがあります。それらの一つは”HTTP/2 and SPDY Indicator”です。
Questo documento descrive http2 ad un livello di tecnicismo e protocollo. Tale documento è nato a partire da una presentazione di Daniel a Stoccolma in Aprile 2014, presentazione che è stata successivamente convertita ed estesa fino a diventare un vero e proprio documento, ben più dettagliato e contentente esplicazioni piu proprie.
RFC 7540 è il nome ufficiale della specifica finale http2, pubblicata il 15 Maggio 2015: https://www.rfc-editor.org/rfc/rfc7540.txt
Ogni eventuale errore in questo documento è il risutato della mia pigrizia e stoltezza, pregasi segnalarne eventuale presenza; tali errori saranno corretti in versioni successive.
In questo documento ho provato ad usare in maniera estensiva il termine "http2" per desrcivere il nuovo protocollo, mentre in pura termininologia tecnica il vero nome sarebbe (è) HTTP/2. Ho fatto questa scelta per migliorare la leggibilità e per favorive una migliore scorrevolezza del linguaggio.
Il mio nome è Daniel Stenberg e lavoro per Mozilla. Ho lavorato in ambito open source e networking per più di vent'anni all'interno di svariati progetti. Molto probabilmente sono meglio conosciuto per essere il principale sviluppatore di curl e libcurl. Sono stato coinvolto nel gruppo di lavoro IETF HTTPbis per svariati anni ed assieme al gruppo ho avuto la possibilità di rimanere sempre aggiornato a proposito del progetto HTTP 1.1 per poi in seguito partecipare alla standardizzazione di http2.
Email: [email protected]
Twitter:
Web:
Blog:
Se dovessi trovare errori, omissioni, sbagli o falsità in questo documento, ti pregherei di mandarmi una versione corretta del paragrafo in questione; mi occuperò di redigerne una versione corretta. Darò tutto il credito a chiunque aiuti concretamente! Spero di rendere questo documento sempre più completo col passare del tempo.
Questo documento è disponibile su
Questo documento è rilasciato sotto licenza Creative Commons Attribution 4.0:
La prima versione del presente documento fu pubblicata il 25 Aprile 2014. Di seguito le migliorie e bugfix delle più recenti versioni.
Convertita la sezione principale del documento a sintassi Markdown
13: Citare più risorse, link e descrizioni aggiornate
12: Aggiornata la descrizione di QUIC con riferimento alla draft "ufficiale"
8.5: Aggiornata alla numerazione attuale
1.1: HTTP/2 è oramai una RFC ufficiale
6.5.1: Collegamento alla RFC su HPACK
9.1: Menzionare come Firefox 36+ configuri http2 "on by default"
12.1: Aggiunta sezione a proposito di QUIC
Molti miglioramenti dal punto di vista del linguaggio, grazie a molti contributi amichevoli
8.3.1: Citare le attività specifiche di nginx e Apache httpd
1: Il protocollo ha ricevuto l'OK
4.1: Accordare i tempi passati rispetto al fatto che 2014 è oramai tempo passato
Front: Aggiunta immagine con nome “http2 explained”, link corretto
1.4: Aggiunta sezione "Storia del documento"
Aggiornato alla draft-17 HTTP/2 e draft-11 HPACK
Aggiunta sezione "10. http2 in Chromium" (== più lungo di una pagina)
Un sacco di fix spelling
A quota 30 implementazioni ad oggi
この文書はhttp2を技術的にプロトコルレベルで記述したものです。始まりはDanielが2014年4月にストックホルムで行ったプレゼンテーションでした。後に拡張され、全ての詳細や丁寧な説明を含む立派な文書になりました。
RFC 7540は公式なhttp2仕様書で、2015年5月15日に発行されました: https://www.rfc-editor.org/rfc/rfc7540.txt
この文書におけるすべての誤りは私自身のものであり、私の至らなさの致すところです。指摘していただければ次のバージョンで修正します。
この文書では統一的に”http2”という単語でこの新しいプロトコルを呼称していますが、正式な名称はHTTP/2です。読みやすさと言語における収まりの良さのためにこの選択をしました。
私の名前はDaniel Stenbergです。Mozillaで働いています。私はオープンソースとネットワークの分野で20年以上も様々なプロジェクトで働いています。おそらく私はcurlとlibcurlの開発リーダーとしてよく知られているかもしれません。私はIETF HTTPbisワーキンググループに数年間参加していて、最新のHTTP 1.1に追随するとともに、http2の標準化にも参加しました。
Email: [email protected]
Twitter:
Web:
Blog:
間違いや脱字、エラー、明らかな嘘をこの文書に見つけた場合、修正した段落を私に送ってください。修正を取り込みます。私はもちろん助けてくれた人全てに適切な名誉を与えるつもりです。私はこの文書が時とともに改善されていくことを望んでいます。
この文書はで利用可能です。
この文書はCreative Commons Attribution 4.0 license: でライセンスされています。
この文書の最初のバージョンは2014年4月25日に発行されました。最近の文書における主たる変更点を以下に示します。
Converted the master version of this document to Markdown syntax
13: mention more resources, updated links and descriptions
12: Updated the QUIC description with reference to draft
8.5: refreshed with current numbers
1.1: HTTP/2 is now in an official RFC
6.5.1: link to the HPACK RFC
9.1: mention the Firefox 36+ config switch for http2
12.1: Added section about QUIC
Lots of language improvements mostly pointed out by friendly contributors
8.3.1: mention nginx and Apache httpd specific acitivities
1: the protocol has been “okayed”
4.1: refreshed the wording since 2014 is last year
front: added image and call it “http2 explained” there, fixed link
1.4: added document history section
Updated to HTTP/2 draft-17 and HPACK draft-11
Added section "10. http2 in Chromium" (== one page longer now)
Lots of spell fixes
At 30 implementations now
Suficiente sobre antecedentes, historia y asuntos políticos que nos han traído hasta aquí. A continuación vamos a bucear en asuntos específicos del protocolo. Los bits y los conceptos que crean http2.
http2 es un protocolo binario.
Déjame asentar esto un minuto. Si eres una persona que ha estado involucrada en protocolos de Internet, las posibilidades de que reacciones instintivamente contra esta opción y de que calcules argumentos que expliquen como los protocolos de texto/ascii son superiores por permitir a los humanos hacer consultas a mano con telnet. http2 es en binario para conseguir hacer el entramado (framing) mucho más sencillo. Determinar el comienzo y el final de cada trama es una de las cosas realmente complicadas en HTTP 1.1 así como en todos los protocoles en texto en general. Eliminando espacios en blanco opcionales y distintas formas de escribir la misma cosa, las implementaciones serán mucho más simples.
Este es un documento que describe http2 desde un nivel técnico y de protocolo. Comenzó como una presentación, que hice en Estocolmo en abril de 2014, para más tarde extender y convertirse en un documento completo con todo detalle y explicaciones concisas.
RFC 7540 es el nombre oficial de la especificación final de http2 que ha sido publicada el 15 de Mayo de 2015:
Todos los errores encontrados en este documento son míos propios (y del traducción), resultado de mis propios defectos. Por favor, reportarlos y haré las actualizaciones con sus correcciones.
He intentado utilizar consecuentemente la palabra “http2” para describir el nuevo protocolo, aunque en términos puramente técnicos, el nombre correcto es HTTP/2. He escogido esta opción para favorecer la legibilidad y conseguir un lenguaje más fluido.
Esta es la traducción al español de la versión 1.13 del documento publicada el 12 de septiembre de 2015.
فکر میکنم بحث درمورد پیشزمینه و اتفاقات گذشته بس باشد. برویم به سراغ استانداردهای پرتکل: چیزهایی که http2 را ساختند.
http2 یک پرتکل باینری است.
اگر شما با پرتکلهای اینترنتی قبلا کار کرده باشید، احتمالا نسبت به این مورد واکنش نشان میدهید و شروع به ارائهی دلایل مبنی بر این که چرا پرتکلهای متنی (text/ascii) بهترند چون انسانها میتوانند آنها را بخوانند، در telnet از آنها استفاده کنند و ...
http2 باینری است تا فریمبندی را راحتتر کند. تشخیص اول و آخر یک فریم در HTTP 1.1 و بقیهی پرتکلهای متنی، کار پیچیدهای بود. با دورشدن از فضاهای خالی اختیاری و راههای متفاوت برای پیادهسازی یک چیز، پیادهسازی حالا راحتتر خواهد شد.
我々がここに至った背景や歴史、政治的な事柄はもう十分でしょう。プロコトルの詳しい仕様について話しましょう。
http2はバイナリープロトコルです。
この事実を受け入れるまで少し時間を取りましょう。インターネットのプロトコルに関与してきた人なら、衝動的にこの選択について反対し、telnetなどで人間がリクエストを入力できるテキスト/アスキーベースのプロトコルがいかに優れているかを説明しだすことでしょう。
http2はフレーミングを遥かに簡単にするためにバイナリーになりました。フレームの始まりと終わりを判断することは、HTTP 1.1だけでなくテキストベースのプロトコル全般において大変複雑なのです。オプショナルな空白や、同じことを違う方法で書けるという仕様をなくすことで、実装がより簡単になるのです。
また実際のプロトコル部分とフレーミングを分離することも簡単にします。HTTP 1.1ではこれらは一体となっていたのでした。
Ce document décrit http2 d'un point de vue technique et protocolaire. Il a commencé par une présentation à Stockholm réalisée par Daniel en avril 2014, présentation qui a été par la suite convertie et étoffée dans un document complet avec des explications détaillées.
La RFC 7540 est le nom officiel de la spécification http2 finale, elle a été publiée le 15 mai 2015 :
Toute erreur dans ce document est mienne et le résultat de mes approximations. Merci de me les indiquer afin que je les corrige pour les prochaines versions.
Dans ce document, j'ai essayé d'utiliser le terme "http2" pour décrire le nouveau protocole en termes purement techniques, le nom officiel est HTTP/2. J'ai fait ce choix pour améliorer la fluidité de lecture et obtenir une meilleure lisibilité.
.icon1 {
background: url(data:image/png;base64,<data>) no-repeat;
}
.icon2 {
background: url(data:image/png;base64,<data>) no-repeat;
}.icon1 {
background: url(data:image/png;base64,<data>) no-repeat;
}
.icon2 {
background: url(data:image/png;base64,<data>) no-repeat;
}.icon1 {
background: url(data:image/png;base64,<data>) no-repeat;
}
.icon2 {
background: url(data:image/png;base64,<data>) no-repeat;
}.icon1 {
background: url(data:image/png;base64,<data>) no-repeat;
}
.icon2 {
background: url(data:image/png;base64,<data>) no-repeat;
}.icon1 {
background: url(data:image/png;base64,<data>) no-repeat;
}
.icon2 {
background: url(data:image/png;base64,<data>) no-repeat;
}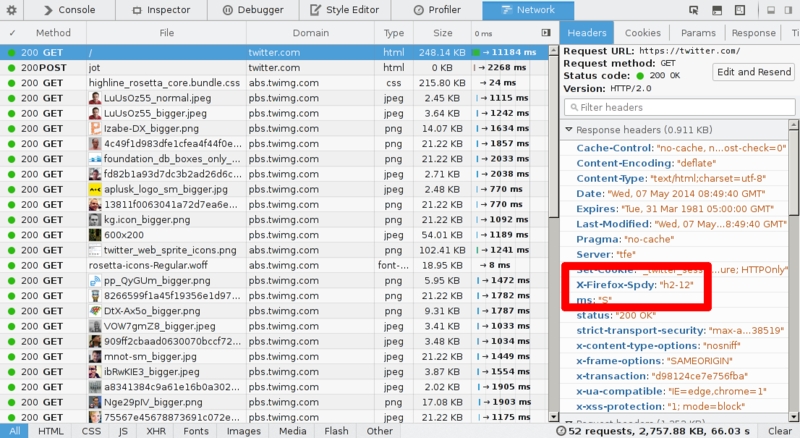
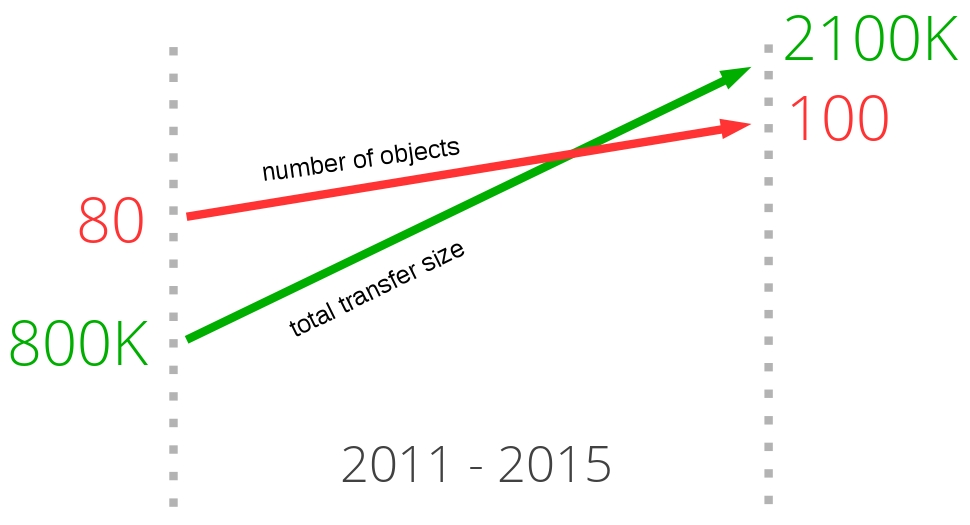

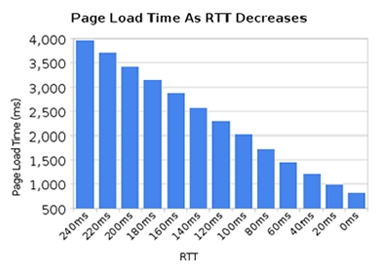

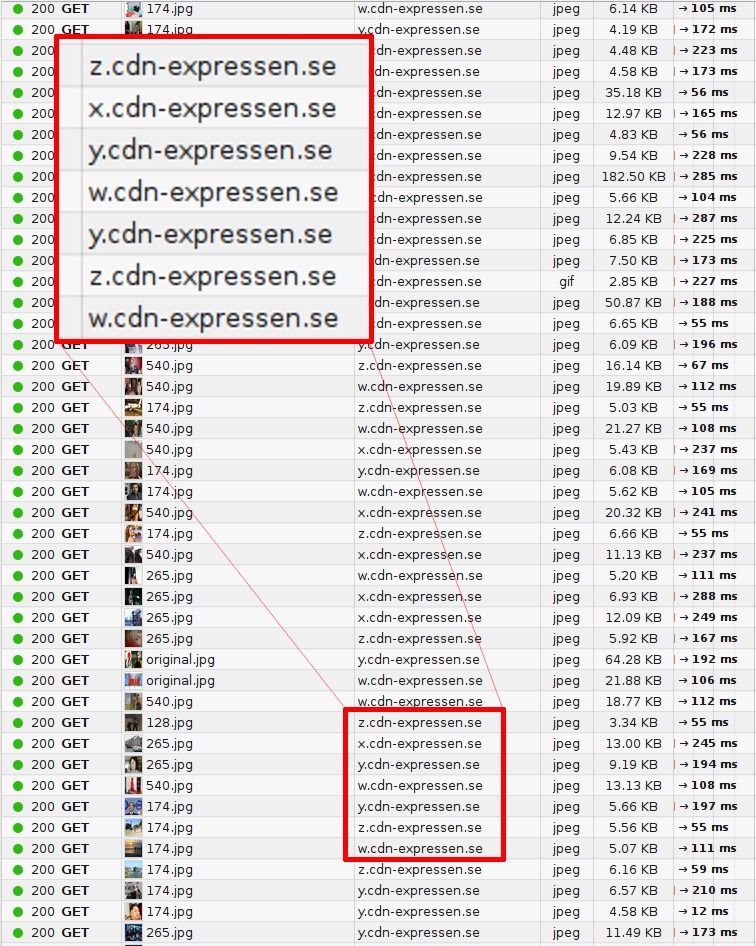
3.4: La media è al momento 40 connessioni TCP
6.4: Aggiornato per aderire a quanto affermato nella specifica
Molti errori grammaticali e di spelling corretti
14: Aggiunto ringraziamento ai bug reporters
2.4: Migliori etichette per il grafico sulla evoluzione di HTTP
6.3: Corretto l'ordine dei vagoni nel "treno multiplexato"
6.5.1: draft-12 HPACK
8.5: Aggiunti alcune cifre relative all'utilizzo
8.3: Citare anche internet explorer
8.3.1 Aggiunto "implementazioni mancanti"
8.4.3: Menzionare come TLS incrementi anche il tasso di successo
3.4: the average is now 40 TCP connections
6.4: Updated to reflect what the spec says
many spelling and grammar mistakes corrected
14: added thanks to bug reporters
2.4: (better) labels for the HTTP growth graph
6.3: corrected the wagon order in the multiplexed train
6.5.1: HPACK draft-12
8.5: added some current usage numbers
8.3: mention internet explorer too
8.3.1 "missing implementations" added
8.4.3: mention that TLS also increases success rate
El hecho de las funcionalidades de compresión del protocolo y de que casi siempre correrá sobre TLS, restan importancia a que el protocolo no sea en texto plano, ya que la información tampoco viajaría en texto de cualquier manera. Simplemente tendremos que acostumbrarnos a utilizar el inspector de Wireshark o algo similar para determinar que está pasando a nivel de protocolo con http2.
El Debugging en este protocolo deberá hacerse utilizando herramientas como curl o analizando el tráfico de red con el disector de tráfico http2 de Wireshark u otra herramienta similar.
http2 envía tramas en binario. Pueden enviarse distintos tipos de trama, y todos ellos comienzan de la misma manera:
Tipo, Tamaño, Flags, Identificador de Flujo y la carga útil de la trama.
Existen 10 tipos de tramas definidos en la especificación http2 y los dos tipos fundamentales que se mapean con las funcionalidades de HTTP 1.1 son DATA y HEADERS. Más adelante en el documento, voy a describir algunas de las tramas en algo más de detalle.
El identificador de flujo mencionado en la sección anterior en la descripción de la trama binaria, asocia cada trama enviada a través de http2 con un “flujo”. Un flujo es una asociación lógica. Una secuencia de tramas independiente bidireccional intercambiados entre el cliente y el servidor dentro de una conexión http2.
Una conexión http2 puede contener múltiples flujos abiertos concurrentes, ya sea con tramas de finalización de distintos flujos. Los flujos pueden ser establecidos y usados unilateralmente por el cliente o el servidor, y pueden ser cerrados por cualquiera de los dos puntos. El orden en el que se envía cada flujo es significativo. Los receptores procesan las tramas en el orden en el que son recibidos.
La multiplexación de los flujos significa que paquetes de distintos flujos se mezclan en la misma conexión. Dos (o más) trenes independientes se convierten en uno único y luego son separados en el otro punto. Aquí están los dos trenes:
Los dos trenes multiplexados sobre la misma conexión:
Cada flujo tiene una prioridad (denominada también "peso"), que se usa para indicar al peer que flujos deben ser considerados más importantes en caso de contar con restricciones de recursos que obliguen al servidor a seleccionar que flujo enviar primero.
Utilizando la trama PRIORITY, un cliente puede indicar al servidor que otro flujo, es dependiente un flujo. Esto permite al cliente construir un "árbol" de prioridades, en el que varios “flujos hijos”, pueden depender de que vaios "flujos padre" sean completados.
Los pesos de prioridad y las dependencias pueden ser cambiados dinámicamente en tiempo real, lo que permitirá en una página con muchas imágenes por ejemplo, que el navegador cambie la prioridad en las solicitudes a medida que el usuario hace scroll; o al cambiar entre tabs, puede priorizar el conjunto de flujos que acaba de coger el foco del usuario.
HTTP es un protocolo sin estado. De manera resumida significa que cada petición debe indicar al servidor los detalles necesarios para que la petición sea atendida, sin que el servidor tenga que almacenar gran cantidad de información y meta-información de peticiones anteriores. Ya que http2 no cambia para nada este paradigma, debe cumplirlo igualmente.
Esto convierte el HTTP en repetitivo. Cuando un cliente solicita muchos recursos de un mismo servidor, como imágenes para una página web, habrán una gran serie de solicitudes que parecerán prácticamente idénticas. Una serie de algo casi idéntico, está pidiendo compresión a gritos.
Mientras el número de objetos sigue en aumento, como ya se ha comentado con anterioridad, el uso y el tamaño de las cookies ha seguido creciendo igualmente durante este tiempo. Esta cookies deben ser incluidas en todas las peticiones. Mayormente las misma cookies en cada petición.
El tamaño en la peticiones HTTP 1.1 ha ido haciéndose tan grande en los últimos tiempos que han terminado siendo más grandes que la ventana TCP inicial, lo que hace que el envío de la petición sea muy lento al necesitar recibir un ACK de vuelta del servidor antes de completar la petición por completo. Este sería otro argumento más para la compresión.
Las compresiones HTTPS y SPDY han resultado ser vulnerables a ataques BREACH y CRIME. Insertando texto conocido en el flujo, y averiguando que es lo que cambio en el resultado comprimido, un atacante puede averiguar que se está enviando.
Hacer compresión en contenido dinámico para un protocolo evitando las vulnerabilidades de estos dos ataques, requiere reflexiones y consideraciones cuidadosas. Esto es lo que el grupo HTTPbis intenta hacer.
Se introduce HPACK, Header Compression for HTTP/2, que – como sugiere adecuadamente su nombre – es un formato de compresión especialmente diseñado para cabeceras http2 y estrictamente hablando, está siendo especificado en otro borrador separado de Internet. El nuevo formato, junto con otras contra-medidas como un bit que solicita a los intermediarios no comprimir una cabecera específica o el desplazamiento opcional de tramas deberían hacer mucho más difícil llegar a romper esta compresión.
En palabras de Roberto Peon (uno de los creadores de HPACK):
“HPACK ha sido diseñado para dificultar que una implementación conforme filtre información, para hacer que la codificación y decodificación muy rápida y barata, para proporcionar al receptor control del tamaño del contexto de la compresión, para permitir que un proxy reindice (por ejemplo, estados compartidos entre un frontal y una trasera a través de un proxy), y para una comparación rápida de cadenas codificadas mediante huffman”.
Uno de los inconveniente con HTTP es que cuando un mensaje HTTP ha sido enviado con cierto tamaño especificado en la cabecera Content-Length, no puedes ser parado fácilmente. A menudo (aunque no siempre), se puede cerrar la conexión TCP, pero pagando el precio de tener que negociar un handshake TCP de nuevo.
Una solución mejor para esto es simplemente parar el mensaje, y comenzar uno nuevo. En http2, esto puede hacerse con la trama RST_STREAM, que previene derrochar el ancho de banda y permite mantener la conexión.
Esta funcionalidad también se conoce como “cache push”. La idea aquí es que si el cliente solicita un recurso X determinado, el servidor determina que es altamente probable que el cliente solicite también el recurso Z, de manera que es enviado sin que el cliente lo solicite. Esto ayudará al cliente a tenerlo en su cache, de manera que ya estará allí cuando sea necesario.
El envío desde el servidor (Server push) es algo que un cliente debe permitir explícitamente, e incluso si está permitido, podrá a su propia elección rápidamente terminar el flujo con un RST_STREAM no permitiendo así ningún Server Push en particular.
Cada flujo individual sobre http2 tiene su propia ventana de flujo anunciada, sobre la que el otro extremo puede enviar información. Si conoces como funciona SSH, es muy similar en estilo y espíritu.
Para cada flujo, cada uno de los extremos tiene que indicar a su peer que tiene más espacio para la información entrante, de manera que el otro extremo únicamente puede enviar tanta información como espacio se dispnga, hasta que la ventana sea hecha más grande. Únicamente existe control de flujo para las tramas DATA.
Mi nombre es Daniel Stenberg y trabajo en Mozilla. Llevo trabajando con open source y networking durante más de veinte años en numerosos proyectos. Posiblemente se me conozca por ser el desarrollador principal de curl y libcurl. He formado parte del grupo de trabajo HTTPbis durante mucho años, y allí he estado al tanto de las actualizaciones de HTTP 1.1 y me he involucrado en el trabajo de estandarización de http2.
Email: [email protected]
Twitter: @bagder
Web: daniel.haxx.se
Blog: daniel.haxx.se/blog
Si encuentras errores, omisiones o mentiras descaradas en este documento, por favor envíame un versión actualizada del párrafo afectado y haré versiones modificadas. ¡Se mencionará en los créditos a todo aquel que eche una mano!. Espero ir mejorando este documento a lo largo del tiempo.
El documento está disponible en https://daniel.haxx.se/http2
Este documento está licenciado bajo Creative Commons Attribution 4.0 license: https://creativecommons.org/licenses/by/4.0/
La primera versión de este documento fue publicada el 25 de abril de 2014. A continuación se muestran las versiones más recientes de este documento:
Convertida la versión maestra a sintaxis Markdown
13: Mención a más recursos. Actualización de links y descripciones
12: Actualización de la descripción de QUIC y referencia a su draft
8.5: Actualizado con números actuales
3.4: La media es ahora de 40 conexiones TCP
6.4: Actualizada para reflejar lo que dice la especificación
1.1: HTTP/2 es ahora un RFC oficial
6.5.1: enlace al RFC de HPACK
9.1: Mención al parámetro de configuración de Firefox 36+ para http2
12.1: Añadida sección sobre QUIC
Montón de mejoras en el lenguaje, apuntadas mayormente por contribuciones amigas.
8.3.1: mención a actividades específicas de nginx y Apache httpd
1: El protocolo ha sido “okayed”
4.1: Actualizada la palabra, ya que 2014 es el año pasado.
portada: añadida imagen y nombrado “http2 explicado”, enlace arreglado
1.4: añadido el historial del documento
Corregidos muchos errores de deletreo y gramática
14: añadido agradecimiento a reportes de bugs
2.4: (mejora) etiquetas para el gráfico de crecimiento HTTP
6.3: corregido el orden de los vagones en el tren multiplexado
6.5.1: HPACK draft-12
Actualización a HTTP/2 draft-17 y HPACK draft-11
Añadida la sección "10. http2 en Chromium" (== ahora, una página más larga)
Montón de correcciones de deletreo
Ahora en 30 implementaciones
8.5: añadidos algunos números de uso actuales
8.3: mención también a internet explorer
8.3.1 añadido "implementaciones pendientes"
8.4.3: mencionar que TLS también eleva el índice de éxito
در حقیقت، پرتکل قابلیت فشردهسازی را دارد و اجرا شدنش روی TLS، متن را مخفی میکند، بنابراین شخص ثالثی نمیتواند متن را از روی ترافیک جابجاشده بخواند. در واقع، باید عادت کنیم که از برنامههایی مثل Wireshark برای خواندن دادههای مبادلهشده در سطح پرتکل http2 استفاده کنیم.
دیباگکردن این پرتکل به ابزارهایی مثل curl یا برای آنالیز به Wireshark و مشابههای آن نیاز دارد.
http2 فریمها را به صورت باینری میفرستد. نوع فریمها ممکن است مختلف باشد، ولی همهی آنها یکنوع مشخصات دارند: اندازه (Length)، نوع (Type)، نشانها (Flags)، شناسهی استریم (Stream Identifier) و دادههای فریم.
در قرارداد http2، ده نوع فریم مختلف تعریف شده و اساسیترین آنها که به قابلیتهای HTTP 1.1 نیز مربوط هستند، DATA و HEADERS است. بعضی از این نوعها را در ادامه بررسی میکنیم.
شناسهی استریم که در فریم قبلی به آن اشاره شد، با یک «استریم» در هر فریم همراه است. یک استریم، مجموعهای از فریمهای داده به طور مستقل و دوطرفه است که کلاینت و سرور میتوانند در یک کانکشن http2 آنها را مبادله کنند.
یک کانکشن مستقل http2 میتواند دارای چندین استریمهای باز به طور همزمان باشد، و یا یکی از طرفین، استریمهای مختلف را با هم ترکیب کند تا چندین فریم را بسازد.
تسهیمسازی استریم به این معنی است که بستههای چندین استریم با هم ترکیب شده و در قالب یک کانکشن مبادله میشودن. دو (یا بیشتر) قطار از دادهها، تبدیل به یک قطار میشوند و در طرف دیگر، دوباره جدا میشوند. مثلا:
حالا اگر این دو قطار با هم ترکیب شوند یا اصطلاحا تسهیمسازی (Multiplex) شوند:
هر استریم دارای اولویت است (همچنین آن را به عنوان weight هم میشناسند)، که به طرف مقابل اطلاع میدهد که کدام استریم مهمتر است تا با توجه به محدودیت منابع، کدام را زودتر دریافت کند یا کدام را زودتر درخواست کند.
با استفاده از فریم PRIORITY، کلاینت میتواند به سرور اطلاع دهد که یک استریم، به چه استریمهای دیگری وابسته است. این قابلیت به کلاینت اجازه میدهد که یک درخت از وابستگیها ایجاد کند که هر «استریم فرزند» به «استریمهای پدر» وابسته است.
اولویتها و وابستگیها میتوانند در زمان اجرا به صورت پویا عوض شوند، که باعث میشود مرورگرها این توانایی را داشته باشند که هنگامی که کاربر در یک صفحهی پر از عکس، پیمایش (Scroll) میکند، مرورگر به سرور اطلاع دهد که کدام عکسها مهمتر هستند، یا اگر به یک Tab دیگر بروید، مرورگر به استریمهای دیگری اولویت بالاتر میدهد که مربوط به صفحهی جدید هستند.
HTTP یک پرتکل Stateless است، یعنی هر درخواست باید هدرهایی را همراه داشته باشد تا سرور بتواند به آن پاسخ دهد، بدون اینکه نیاز باشد سرور اطلاعات بسیاری را از درخواستهای قبلی ذخیره کند. از آنجایی که http2 این پارادایم را تغییر نمیدهد، همچنان به همین صورت کار میکند.
این روش باعث تکراریشدن درخواستهای HTTP میشود. وقتی یک کلاینت از همان سرور، چندین بار درخواست عکس برای یک صفحه میکند، چندین درخواست تقریبا یکسان را میفرستند. این نوع دادههایی که تقریبا یکسان هستند، مناسب فشردهسازی هستند.
همانطور که قبلا هم اشاره کردیم، تعداد فایلهای موردنیاز هر صفحه بالاتر رفته، همچنین اندازهی Cookies و درخواستها هم به مرور زمان در حال افزایش هستند. Cookies باید در هر درخواست فرستاده شوند، معمولا در چندین درخواست یکی هستند.
اندازهی درخواستهای HTTP 1.1 در واقع اینقدر بزرگ شدهاند که گاهی وقتها بیش از حجم مقبول TCP میشوند که باعث میشود ارسالشان بسیار کندتر شود، چون یکبار ناقص فرستاده میشوند تا از سرور ACK بگیرند و بعد از آن، به طور کامل ارسال میشود. این دلیل دیگری برای نیازداشتن به فشردهسازی است.
فشردهسازیهای HTTPS و SPDY دربرابر حملات BREACH و CRIME آسیبپذیر بودند. با قراردادن یک متن شناخته در استریم و یافتن اینکه چگونه تغییر میکند، حملهکننده میتوانست بفهمد که چیزی به صورت Encrypt شده ارسال میشده است.
فشردهسازی محتوای پویا در یک پرتکل - بدون اینکه به یکی از این حملات آسیبپذیر باشد - به فکر و تصمیمهای محتاطانه نیاز دارد. این همان چیزی است که کارگروه HTTPbis سعی کردند انجام دهند.
[HPACK] وارد میشود!(https://www.rfc-editor.org/rfc/rfc7541.txt). Header Compression for HTTP/2 یا فشردهسازی هدرها برای HTTP/2، یک فرمت فشردهسازی است که مخصوصا برای هدرهای http2 طراحی شده است و در یک پیشنویس اینترنتی جداگانه تبیین شده.
به گفتهی Roberto Peon (یکی از سازندگان HPACK): (مترجم: این نقلقول به طور تحتاللفظی ترجمه نشده).
HPACK احتمال ناامنبودن پیادهسازی و در نتیجه نشت اطلاعات را کاهش میدهد روند رمزنگاری/رمزگشایی را آسانتر و بهصرفهتر میکند، و به دریافتکننده این امکان را میدهد که بر Context Size فشردهسازی کنترل داشته باشد یا اجازهی ایجاد پراکسی برای Re-Indexing (مثل وضعیت مشترک بین فرانتاند و بکاند در یک پراکسی) را بدهد و همچنین امکان مقایسهی سریع رشتههایی که به روش هافمن رمزنگاری شدهاند را میدهد.
یکی دیگر از معایب HTTP 1.1، عدم وجود پشیمانی است! یعنی وقتی یک درخواست با Content-Length مشخص فرستاده شد، نمیتوانید به این راحتی متوقفش کنید. البته، شما میتوانید کانکشن TCP را قطع کنید، ولی باید دوباره یک ارتباط TCP جدید ایجاد کنید.
راهحل بهتر این است که درخواست قبلی را متوقف کنید و یک درخواست جدید بفرستید. این کار در http2 با ارسال فریم RST_STREAM ممکن است که از هدررفت پهنای باند و همچنین از بین رفتن کانکشنها جلوگیری میکند.
این ویژگی را با نام «cache push» نیز یاد میکنند. ایدهی اصلی این است که هنگامی که کلاینت درخواست فایل X را میکند، سرور میداند که احتمالا فایل Z را هم میخواهد و آن را به کلاینت، بدون اینکه درخواست کرده باشد، میفرستد. این ویژگی باعث میشود که کلاینت ، فایل Z را هم در Cache قرار دهد و هنگامی که نیاز است از آن استفاده کند.
Server push ویژگیای است که کلاینت باید به سرور اجازهی انجام آن را بدهد. در آن صورت، کلاینت میتواند یک استریم پوششده را در هر زمانی با RST_STREAM کنسل کند.
هر استریم http2، ظرفیت جریان را تعیین میکند تا سمت دیگر مطلع باشد که چه مقدار میتواند داده بفرستید. اگر با پرتکل SSH و چگونگی کار آن آشنا باشید، میدانید که این ویژگی بسیار شبیه به SSH است.
در هر استریم، هر دو طرف باید به طرف دیگر اطلاع دهند که فضای کافی برای دریافت دادهها را دارند و طرف دیگر تنها در صورتی اجازهی ارسال دارد که ظرفیت اجازه میدهد. تنها فریمهای DATA کنترل میشوند.
このプロトコルをデバッグには、おそらくcurlのようなツールを使うか、Wiresharkのhttp2ディセクターでネットワークを解析することになるでしょう。
http2はバイナリーフレームを送信します。数種類のフレームタイプがありますがそれらは共通して以下を含んでいます:
長さ、タイプ、フラグ、ストリーム識別子(ID)、フレームペイロード
10個のフレームがhttp2仕様書に定義されていて、その中でもHTTP 1.1の機能に対応づけるための基本的なフレームはDATAとHEADERSです。いくつかのフレームについては後で詳しく述べます。
先のバイナリーフレームフォーマットのセクションで述べたストリームIDはhttp2で送受信されるフレームを”ストリーム”に関連付けます。ストリームは論理的な関連付けです。http2接続では、クライアントとサーバー間で独立した、双方向のフレームの列が送受信されます。
一つのhttp2接続は複数の並行して開かれた状態のストリームを含むことができ、両エンドポイントは複数のストリームからのフレームを、フレーム単位で互い違いに送信することができます。ストリームは一方的に使うこともできるし、クライアントかサーバーで共有され、どちらかによって閉じることができます。ストリーム内でのフレームの順番は意味をもっています。受信者はフレームを受信した順に処理します。
ストリームの多重化は多くのストリームのフレームが同一接続上でフレーム単位で混合されるということを意味します。2つあるいはそれ以上の独立したデータの列車が、一つの列車に結合され、受信側でまた分離されます。ここに2編成の列車があります:
2編成の列車が同じ接続上で多重化されました:
各ストリームには優先度(”重み”としても知られています)があり、リソースの制約でサーバーがどのストリームを先に送るか決める時に、どのストリームが重要かをサーバーに知らせます。
クライアントはPRIORITYフレームを使ってサーバーにこのストリームが他のどのストリームに依存するのか指定することができます。これにより、クライアントは”子ストリーム”が”親ストリーム”の完了に依存するような優先度”木”を作ることができます。
優先度や依存関係は動的に変更することができるので、画像がたくさんあるページをユーザーがスクロールしたときにどの画像が最も重要であるかを伝えることや、タブを切り替えたときにフォーカスされる新しいストリームの集合の優先度を上げる、ということができます。
HTTPはステートレスなプロトコルです。つまりサーバーが、以前のリクエストに含まれる情報やメタデータを保存することなく、次のリクエストを処理するためには、必要な情報を毎回送信する必要があります。 http2はこのパラダイムを変えてはいないので、同じことをする必要があります。
これによりHTTPは冗長になります。クライアントが同じサーバーに多くのリソース(webページの画像など)を要求した場合、ほとんど同じようなリクエストが大量に送信されることになります。ほとんど同じものが連続するような時は、圧縮の出番です。
私が先に言及したようにwebページ毎のオブジェクトの数が増加していますが、cookieやリクエストのサイズも同様に年々増加を続けています。Cookieは全てのリクエストに含める必要があり、リクエスト毎にほとんど違いはありません。
HTTP 1.1のリクエストのサイズはとても大きくなってきていて、初期TCPウインドウよりも大きくなる場合があり、サーバーからACKを受信するため完全なラウンドトリップを必要とすることから、リクエスト送信完了までの時間がとても長くなります。これは圧縮の必要性を示唆する理由の一つです。
プロトコルの動的なコンテンツに対する圧縮を、これらの攻撃に対して脆弱ではない方法で行うには、注意深く考える必要があります。これこそHTTPbisチームが行おうとするところのものです。
そこでHPACK、HTTP/2のためのヘッダー圧縮、が誕生しました。名前が示す通り、http2ヘッダーのために生み出されたヘッダー圧縮フォーマットであり、独立したインターネットドラフトで定義されています。この新しいフォーマットは、中間装置に対しヘッダーフィールド単位に圧縮しないように指定するビットや、フレームにパッディングを付け加えるオプションもあいまって、悪用しにくくなっているはずです。
Roberto Peon(HPACKを生み出した人々の中の一人)の言葉です:
”HPACKは、仕様に沿う実装が情報を漏洩するのが困難であり、エンコードとデコードが高速で必要なリソースも少なく、 受信側が圧縮コンテキストのサイズを制御でき、プロキシーが再インデックス(プロキシー内部のフロントエンドとバックエンド間の共有状態)でき、ハフマンエンコードされた文字列の比較が高速である、ように設計されています。”
HTTP 1.1の一つの欠点は、HTTPメッセージがContent-Length付きで送信された場合、簡単に停止させることができないということです。殆どの場合(常にではありません)TCP接続を切断して実現しますが、新しいTCP接続を再度確立するという代償を払う必要があります。
よりよい解決方法はメッセージを停止させ、新しいメッセージを開始することです。http2のRST_STREAMフレームを使うとこれが実現できます。これは帯域が無駄に使われてしまうことを防ぎ、接続が切断されてしまうことを回避することに役立ちます。
これは”キャッシュプッシュ”とも呼ばれている機能です。背後にあるアイデアはこうです。クライアントがリソースXを要求したとき、サーバーはクライアントはほとんどの場合リソースZも必要であると知っている可能性があるから、それをクライアントが要求する前に送信してしまおう。こうすることでクライアントはZをキャッシュに入れておくことができ、必要なときに使うことができます。
サーバープッシュはクライアントが明示的にサーバーに許可を与える必要がある代物であり、許可した場合でも、プッシュされたストリームが必要ないと判断した場合RST_STREAMで即座に閉じることができます。
http2上のストリームはそれぞれ独立にフローウインドウを持っていて、それはピアがストリームへ送信できるデータ量を制限します。SSHがどのように動いているかご存知なら、それとよく似た様式や背景を持っています。
各ストリームにおいて両エンドポイントはピアに対してどれくらいデータを受信できるか伝えなければなりません。ピアはウインドウが拡張されるまで伝えられたデータ量までしか送信することができません。DATAフレームのみがフロー制御されています。
Mon nom est Daniel Stenberg et je travaille chez Mozilla. J'ai travaillé dans l'open source et la réseautique, depuis plus de 20 ans, sur de nombreux projets. Je suis plus connu peut-être en tant que développeur principal de curl et libcurl. J'ai été impliqué dans le groupe de travail de l'IETF HTTPbis pendant plusieurs années où j'ai maintenu à jour les spécifications HTTP 1.1 et participé à la standardisation de http2.
Email: [email protected]
Twitter: @bagder
Web: daniel.haxx.se
Blog: daniel.haxx.se/blog
Si vous trouvez des erreurs, oublis, fautes ou mensonges éhontés dans ce document, je vous prierais de bien vouloir m'envoyer une version corrigée que je publierai dans une édition révisée. Je mentionnerai clairement les noms des contributeurs! J'espère améliorer ce document avec le temps.
Ce document est disponible ici: https://daniel.haxx.se/http2
Ce document est couvert par la licence Creative Commons Attribution 4.0 : https://creativecommons.org/licenses/by/4.0/
La première édition de ce document fut publiée le 25 avril 2014. Voici les changements majeurs des dernières éditions.
Conversion de la version principale de ce document au format Markdown
13: Mention de plus de ressources, mise à jour des liens et descriptions
12: Mise à jour de la description de QUIC en mentionnant le draft
8.5: Mise à jour des chiffres
3.4: La moyenne est maintenant de 40 connexions TCP
6.4: Mise à jour en s'alignant sur la spécification
1.1: HTTP/2 est maintenant une RFC officielle
6.5.1: Lien vers la RFC HPACK
9.2: Mention du changement de config pour http2 dans Firefox 36 et +
12.1: Nouvelle section sur QUIC
Nombreuses améliorations de style linguistique (Note du traducteur: en anglais)
8.3.1: Mention des développements spécifiques nginx et Apache httpd
1: Le protocole est "presque approuvé"
4.1: Rafraîchissement du style linguistique (Note traducteur: en anglais)
Converture: ajout de l'image et légende "http2 explained", lien corrigé
1.4: Ajout de la section "Historique"
Diverses corrections orthographiques
14: Ajout de remerciements pour les contributeurs
2.3: Meilleurs libellés pour le graphique de croissance HTTP
6.3: Correction de l'ordre des wagons dans le train multiplexé
6.5.1: HPACK draft-12
Mise à jour HTTP/2 draft-17 et HPACK draft-11
Ajout de la section "10. http2 et Chromium"
Diverses corrections orthographiques
Désormais 30 implémentations
8.5: Ajout des chiffres d'utilisation
8.3: Mention d'Internet Explorer
8.3.1: Ajout des "implémentations manquantes"
8.4.3: Mention que TLS améliore le taux de réussite
이 문서는 기술과 프로토콜 측면서에서 http2를 서술하였습니다. 2014년 4월 스톡홀롬에서 Daniel이 제출하며 시작되고 이후 세밀하고 정확한 설명으로 가득찬 문서로 전환되고 확장되었습니다.
2015년 5월 발행된 http2의 최종명세의 정식 명칭은 RFC 7540 입니다. https://www.rfc-editor.org/rfc/rfc7540.txt
이 문서에 있는 잘못된 내용들은 모두 나의 결점에서 나온것입니다. 따라서 잘못된 부분은 언제든지 지적해주시기 바라며, 지속적으로 갱신되고 수정될 것입니다.
이 문서에서 저는 HTTP/2.1 라는 새로운 프로토콜의 기술적인 용어를 지속적으로 http2 라는 단어를 사용해 서술할 것입니다. 그 이유는 생소한 단어를 재미있게 읽고 더 나은 흐름의 언어로 설명하기 위함입니다.
저의 이름은 Daniel Stenberg 이고 저는 Mozilla에서 일하고 있습니다. 저는 근 20년간 수 많은 오픈소스 프로젝트에 기여하고, 소통하고 있습니다. 아마도 저는 curl과 libcurl를 이끄는 개발자로 알려져 있을겁니다. 저는 IETF HTTPbis 라는 그룹에서 수 년간 HTTP 1.1이 잘 구동되고 표준을 최신화 하는 일을 했습니다
Email: [email protected]
Twitter:
Web:
Blog:
만약 이 문서를 보고 있는 당신이 잘못 된 정보나 누락, 주제넘은 내용을 찾는다면 저에게 해당 문맥을 수정, 최신화 하여 보내주신다면 저는 해당 버젼으로 반영하겠습니다. 저는 이 프로젝트를 돕는 모두에게 적당한 명예적인 보상을 드리겠습니다. 저는 오랜 시간동안 이 문서가 더 나아지길 바랍니다.
이 문서는 이 사이트에서 보실 수 있습니다.
이 문서는 Creative commons Attribution 4.0에 해당하고 해당 라이센스는 여기서 확인하실 수 있습니다.
이 문서의 첫 번째 버젼은 2014년 4월 25일에 발행되습니다. 아래에 최신의 큰 변화를 기재해두었습니다
이 문서를 Markdown 버젼으로 변환하였습니다
13: 리소스에 대한 더 많은 언급, 링크와 서술 갱신
12: QUIC의 reference 초안 최신화
8.5: 현재 번호 새로 고침
1.1 HTTP/2 은 RFC 표준
6.5.1: HPACK RFC 와 연결
9.1: Firefox 36이후 버젼을 http2로 바꾸기위한 설정 언급
12.1: QUIC 섹션 추가
신뢰할만한 contributor 의 지적사항으로 많은 문맥 개선
8.3.1: nginx와 Apache httpd 구체적인 활동에 대한 언급
1: 승인 된 프로토콜
4.1: 2014년 이후 표현을 새롭게 수정
Front: 이미지를 추가하고 그곳에 "http2 설명"을 불러오도록 링크 수정
1.4: 문서의 역사 항목 추가
HTTP/2 초안 17과 HPACK의 초안11로 최신화
"10. http2 크롬" 항목 추가 (== 현재 한 페이지 이상)
많은 철자 수정
At 30 implementations now
Assez sur la gestation et la politique qui nous ont mené ici. Plongeons dans les spécificités du protocole: les détails et concepts qui font http2.
http2 est un protocole binaire.
Posons-nous un moment. Si vous avez déjà travaillé sur des choix de protocoles IP par le passé, il est probable que votre première réaction soit négative, et que vous argumentiez que les protocoles textuels sont bien supérieurs car les êtres humains peuvent forger des requêtes à la main via telnet, etc.
http2 est binaire pour rendre le découpage (framing en anglais) plus simple. Trouver le début et la fin d'une trame en HTTP 1.1 et dans les protocoles textuels en général est toujours très compliqué. En évitant les blancs optionnels et les diverses façons d'écrire la même chose, les implémentations sont plus simples.
Si è detto abbastanza della storia e delle ragioni politiche che ci hanno accompagnati fin qui. Passiamo all'analisi delle specifiche del protocollo: i fondamenti e i concetti di cui http2 si nutre.
http2 è un protocollo binario.
Lasciamo questo concetto da parte per qualche minuto. Se sei stato coinvolto in protocolli internet prima d'ora, ci sono probabilità che reagirai istintivamente a questa scelta argomentando con fervore quanto un protocollo text/ascii sia più adatto e più versatile, visto che ci permette di instaurare richieste e sessioni via telnet e strumenti simili...
http2 è binario per permettere un incapsulamento più dinamico. Trovare inizio e fine di un frame è uno dei compiti più complessi in HTTP 1.1 e per tutti i protocolli text-based in generale. L'implementazione si rende più semplice allontanandosi da "spazi opzionali" e modi diversi di scrivere la stessa cosa.
3.4: 평균 40 TCP 커넥션
6.4: 스펙을 최신으로 반영
많은 스펠링과 문법의 오류를 수정함
14: 버그를 보고한 사람들에 대한 감사함 표시
2.4: 더 나은 HTTP 성장 그래프 라벨링
6.3: 다중화 스트림의 순서 수정
6.5.1: HPACK 초안-12
8.5: 통계치 추가
8.3: 인터넷 익스플로러
8.3.1 구현이 누락된 부분 추가
8.4.3: TLS의 성공률 향상
De plus, cela permet de séparer plus nettement les parties du protocole et le découpage. Ce manque de séparation nette a toujours été perturbant avec HTTP1.
Le fait que le protocole utilise la compression et TLS diminue la valeur ajoutée de garder du texte pur puisqu'on ne verra pas de texte en clair passer de tout façon. Nous devons simplement nous habituer à utiliser un analyseur de trafic type Wireshark pour comprendre exactement ce qu'il passe au niveau protocolaire http2.
Débugger ce protocole se fera du coup probablement via des outils type curl ou le dissecteur http2 de Wireshark.
http2 envoit des trames binaires. Il y a différentes types de trames envoyées et elles ont toutes le même format:
Longueur, Type, Flags, Identifiant de Flux (Stream ID) et contenu (payload).
Il y a dix trames différentes définies dans la spec http2 et deux sont fondamentales car répliquent le fonctionnement HTTP 1.1 avec DATA (données ou contenu) et HEADERS (en-tête). Je décris ces trames plus en détail par la suite.
L'identifiant de flux (Stream Identifier) mentionné dans le chapitre précédent permet d'associer à chaque trame http2 un "flux" (stream). Un flux est une association logique: une séquence indépendante et bidirectionnelle de trames échangées entre un client et un serveur via une connexion http2.
Une seule connexion http2 peut contenir plusieurs flux simultanés, avec chaque extrémité de la connexion pouvant entrelacer les flux. Les flux sont établis et utilisés unilatéralement ou de concert par le client ou le serveur. Ils peuvent être terminés par l'un ou l'autre côté de la connexion. L'ordre d'envoi des trames dans un flux est important. Le traitement des trames reçues se fait dans l'ordre de réception.
Multiplexer des flux implique que des groupes de trames sont mélangés (ou “mixés”) sur une même connexion. Deux (ou plusieurs) trains de données sont fusionnés en un seul puis scindés à nouveau à la réception. Voici deux trains:
Ils sont mélangés l'un dans l'autre sur la même connexion via multiplexage:
En http2 nous allons voir des dizaines voire des centaines de flux simultanés. Le coût de création d'un nouveau flux est très faible.
Chaque flux a une priorité (ou “poids”), utilisée pour dire à l'autre extrémité de connexion quels flux sont importants, en cas de congestion (manque de ressources) forçant le serveur à faire un choix sur les trames à envoyer en premier.
En utilisant la trame PRIORITY, un client peut indiquer au serveur quel autre flux dépend du flux actuel. Cela permet au client de construire un “arbre” de priorités dans lequel des “flux enfants” dépendront de la réussite des “flux parents”.
Les priorités peuvent changer dynamiquement, ce qui permettra aux navigateurs d'indiquer quelles images sont importantes quand on fait défiler une page remplie d'images, ou encore de prioriser les flux affichés à l'écran quand on passe d'un onglet à un autre.
HTTP est un protocole sans état (state-less). Cela veut dire que chaque requête doit apporter tous les détails requis au serveur pour traiter la requête, sans que le serveur ait besoin de conserver les informations ou meta-données des requêtes précédentes. Comme http2 ne change pas ce principe, il doit en faire de même.
Cela rend HTTP répétitif. Quand un client demande plusieurs ressources d'un même site, comme les images d'un site web, il y a aura une série de requêtes quasi identiques. Une série de points identiques appelle un besoin de compression.
Le nombre d'objets par page web croît comme vu précédemment, l'utilisation de cookies et la taille des requêtes croît également. Les cookies sont inclus dans toutes les requêtes, souvent identiques sur plusieurs requêtes.
Les tailles de requêtes HTTP 1.1 sont devenues tellement importantes qu'elles dépassent parfois la taille de la fenêtre TCP initiale, ce qui rend le tout très lent puisqu'un aller-retour est nécessaire pour qu'un ACK soit envoyé par le serveur. Encore une bonne raison de compresser.
Les compressions HTTPS et SPDY ont été vulnérables aux attaques BREACH et CRIME. En insérant un texte connu dans le flux et en analysant les changements résultant, l'attaquant peut déduire ce qui a été envoyé.
Compresser du contenu dynamique sans devenir vulnérable à une de ces attaques requiert de la réflexion. L'équipe HTTPbis s'y attelle.
Voici HPACK, Header Compression for HTTP/2 (compression d'en-tête pour HTTP/2), qui, comme son nom l'indique, est un format de compression spécialement créé pour les entêtes http2 et spécifié dans un draft IETF distinct. Le nouveau format, avec d'autres contre-mesures comme un bit qui interdit aux intermédiaires de compresser un en-tête spécifique ou du remplissage de trames (padding), devrait rendre plus compliqué l'exploitation de cette compression.
Voici les les mots de Roberto Peon (l'un des créateurs de HPACK):
“HPACK a été conçu pour rendre difficile la fuite d'information avec une implémentation s'y conformant, rendre le codage et décodage très rapide et peu coûteux, fournir au destinataire un contrôle sur la taille du contexte de compression, permettre une réindexation par un proxy, et permettre une comparaison rapide avec des chaînes codées avec un algorithme Huffman.”.
Un des inconvénients de HTTP 1.1: quand le message HTTP est envoyé avec un en-tête Content-Length d'une taille particulière, on ne peut pas l'interrompre facilement. Bien sûr vous pouvez toujours terminer la session TCP mais cela a un coût: renégocier le handshake TCP.
Une meilleure solution serait simplement d'interrompre le message et en démarrer un nouveau. Cela peut se faire en http2 avec la trame RST_STREAM qui permet d'éviter de gâcher de la bande passante et de terminer des connexion TCP.
Cette fonctionnalité est aussi connue comme "cache push". Cas typique: un client demande une ressource X au serveur, le serveur sait qu'en général ce client aura besoin de la ressource Z par la suite et la lui envoie sans que le client l'ait demandée. Cela aide le client à mettre Z dans son cache pour qu'elle soit disponible quand il en aura besoin.
Le Push Serveur (Server Push) doit être explicitement autorisée par le client et, quand bien même le client l'autorise, ce dernier se réserve le droit de terminer un flux "poussé" avec un RST_STREAM.
Chaque flux individuel en http2 a sa propre fenêtre de flux annoncée que l'autre extrémité du flux peut utiliser pour envoyer des données. Si vous savez comment SSH fonctionne, le principe est très similaire.
Pour chaque flux, les deux extrémités doivent indiquer qu'ils ont davantage de place pour accepter des données supplémentaires, l'autre extrémité est autorisée à envoyer ce volume de données uniquement jusqu'à l'extension de la fenêtre. Seules les trames DATA (données) bénéficient du contrôle de flux.
Allo stesso tempo rende più semplice separare protocollo da incapsulamento - cosa che in HTTP 1.1 presenta interdipendenza.
Il supporto nativo per compressione assieme all'onnipresente TLS, diminuisciono il valore di un protocollo puramente testuale, dato che non si vedrebbe alcun testo in una capture on-the-wire. Dobbiamo semplicemente abituarci all'idea di usare uno strumento di cattura/analisi tipo Wireshark al fine di comprendere cosa succeda a livello di http2.
Per operare un buon debug su questo protocollo si avrà probabilmente bisogno di strumenti quali curl, analisi di traffico IP con dissector http2 tipo Wireshark e simili.
https spedisce frame binari. Diversi tipi di frame possono essere inviati, pur condividendo la stessa fase di inizializzazione: Length, Type, Flags, Stream Identifier, e payload del frame.
Esistono dieci tipi diversi di frame definiti nella specifica http2. Probabilmente due dei più fondamentali e che più intuitivamente possono essere ricondotti ad HTTP 1.1 sono DATA e HEADERS. Li descriverò in dettaglio successivamente.
L'ID dello Stream menzionato nella sezione precedente associa ogni frame inviato via http2 ad un preciso "stream". Durante una connessione http2 ogni stream è indipendente, una sequenza bidirezionale di frame viene scambiata fra client e server.
Una sola connessione http2 può contenere molteplici stream -aperti allo stesso tempo- all'interno dei quali ogni endpoint accavalla frame provenienti da streams differenti. Gli streams possono essere aperti ed utilizzati unilateralmente oppure essere condivisi sia dal client sia dal server e possono essere chiusi da entrambi gli endpoint. L'ordine in cui tali frames sono inviati nel contesto dello stream è importante, caratteristico. I destinatari elaborano i frame nell'ordine in cui essi sono ricevuti.
"Multiplexare" gli streams significa che i contenuti di diversi streams sono mescolati nella stessa connessione. Due (o più) flussi di dati sono riuniti in uno singolo, per poi essere nuovamente divisi e riassemblati (individualmente) all'altro capo della connessione. Ecco due flussi (treni di dati, NdR):
Ecco due "treni" multiplexati all'interno di una sola connessione:
Ogni stream è anche dotato di priorità, o "peso", priorità che viene impiegata per rendere noto all'altro estremo quale sia lo stream da considerare di maggior importanza, ad esempio in caso la penuria di risorse dovesse imporre al server di scegliere quale flusso inviare per primo.
Utilizzando il frame PRIORITY, un client può anche istruire il server su quali altri stream dipendano dallo stesso. Permette al client di definire un sistema di priorità (albero) ove diversi rami figlio possano dipendere dal completamento di altri rami padre (parent streams).
Le priorità e le dipendenze possono essere modificate dinamicamente a runtime, cosa che dovrebbe permettere ai browsers di poter decidere -quando un utente stesse scrollando una pagina piena di immagini- quali di queste immagini siano prioritarie, più importanti, o abbiano lo scopo di accelerare lo scorrimento fra diversi tab (con conseguente miglioramente a livello di reattività del focus).
HTTP è un protocollo senza memoria di stato. In brebe, ogni singola richiesta deve portarsi con sè più dettagli possibili, liberando così il server dall'incombenza del dover memorizzare molte informazioni e metadati relativi a richieste precedenti. Dato che http2 non modifica questo paradigma, deve poter continuare a lavorare nello stesso modo.
Ciò fa si che HTTP sembri (e sia) ripetitivo. Quando un client richiede una risorsa dallo stesso server, come i.e. le immagini di una pagina web, un alto numero di richieste verrò generato, e tali richieste sembreranno tutte molto simili fra di loro. Per tale serie sempre ripetitiva, la compressione sarebbe una benedizione.
Come il numero di oggetti per pagina è aumentato, così l'utilizzo dei cookies e la dimensione delle richieste non sono da meno, continuando ad aumentare nel tempo. I cookies devono essere inclusi in ogni richiesta, decine e decine di volte gli stessi elementi sono ritrasmessi.
Le richeste HTTP 1.1 sono al momento diventate così voluminose da eccedere la dimensione della finestra TCP iniziale, cosa che a suo turno rende abbastanza lenta l'operazione, vista la necessita di interi round-trip prima di ricevere ACK, e dunque ben prima che l'intera richiesta sia inviata (e di conseguenza processata). Questo è un altro punto a favore della compressione.
HTTPS e SPDY hanno sofferto a causa di vulnerabilità BREACH e attacchi CRIME. Inserendo un testo noto nello stream ed osservandone i mutamenti in funzione dell'operazione richiesta, un attaccante può scoprire il contenuto del payload.
Creare un meccanismo di compressione dinamica per un protocollo - senza renderlo vulnerabile ad uno di questi attachi- richiede molta cura e considerazione. Proprio quello che HTTPbis ha cercato di fare.
Parliamo quindi di HPACK, Header Compression for HTTP/2, che – come il nome suggerisce - è un formato di compressione creato su misura per gli headers http2, descritto e specificato in una internet draft separata. Il nuovo formato, cosi come le contromisure adottabili (quali un bit che richiede agli intermediari di non comprimere un header specifico ne padding opzionale), dovrebbe rendere più difficile lo sfruttamento della vulnerabilità nel contesto di un attacco.
Nelle parole di Roberto Peon (uno dei creatori di HPACK):
“HPACK è stato concepito per impedire ad una implementazione non-conforme di facilitare la fuga di informazioni, per rendere ecoding e decoding rapidi e semplici, per permettere al ricevente di controllare la compressione sulla base delle dimensioni del contesto, per permettere ad un proxy di poter re-indicizzare (i.e. condivisione dello stato della sessione fra backend e frontend proxies) e per facilitare la comparazione di stringhe Huffman-encoded.
Uno degli svantaggi di HTTP 1.1 è che, una volta che un messaggio HTTP è stato inviato con un determinato Content-Length associato, non è possibile fermarlo. Certo, puoi spesso disconnetter la sessione TCP (non sempre), ma tale pratica implica il costo di una nuova negoziazione TCP (handshake).
Una soluzione più intelligente consisterebbe nel poter fermare il messaggio ed inviarne uno nuovo, correto. Ciò potrà essere realizzato con il nuovo frame http2 RST_STREAM che aiuterà a risparmiare banda ed evitare di interrompere la connessione a livello TCP.
Questa funzione è nota come “cache push”. In pratica, quando un client richiedesse una risorsa X, il server potrebbe voler proporre anche una risorsa Z e mandarla al client senza avenre ricevuto domanda. Ciò aiuta il client ad inserire la risorsa Z in cache, così da averla a disposizione in caso di bisogno.
Il server push deve essere cocesso esplicitamente per volontà del client. Anche a quel punto, il client può terminare istantaneamente la ricezione di uno stream in ogni momento, tramite il messaggio RST_STREAM in caso non dovesse desiderare una determinata risorza Z.
Ogni singolo stream http2 possiede e pubblicizza la propria "finestra di flusso" verso la quale l'altro estremo è autorizzato ad inviare dati. Se conoscete il funzionamento di SSH, questo modo di fare è in linea con lo stesso spirito e principio.
Per ogni singolo stream i due estremi devono potersi avvertire l'un l'altro quando ci dovesse essere abbastanza spazio per accogliere dati in entrata; allo stesso tempo un estremo è abilitato a spedire tanti dati quanti siano quelli ammessi dalla finestra di scambio. Solo i frame DATA sono sottoposti a flow-control (controllo di flusso).
خب، وقتی http2 تصویب شود، دنیا چگونه خواهد شد؟ اصلا تصویب خواهد شد؟
http2 هنوز بهطور گسترده نه پخش شده نه استفاده. ما نمیتوانیم دقیقا بگوییم که چیزها چگونه تغییر خواهند کرد. ما دیدیم که SPDY مورداستفاده قرار گرفت و میتوان با کمی محاسبات، حدسهای نسبتا دقیقی براساس آزمایشهای قبلی و کنونی زد.
http2 تعداد رفت و برگشتها در شبکه را کاهش میدهد، مشکل Head-of-line blocking را با طور کامل با Multiplexing و پسزدن سریع استریمهای ناخواسته، حل میکند.
این پرتکل اجازه میدهد که تعداد زیادی از استریمهای موازی استفاده شود، حتی بیشتر از آنچه که سایتهای توزیعشده (Sharded) ارائه میدهند.
با اختصاص اولویتهای صحیح به استریمها، احتمال این که کلاینتها، اول دادههای مهمتر را دریافت میکنند بیشتر میشود. با همهی اینها، میتوانم بگویم که احتمال این که این پرتکل به سریعترشدن بارگذاری صفحات و پاسخگویی آنها منجر میشود، بسیار بالاست. خلاصه اینکه: یک تجربهی بهتر از وب.
اینکه چقدر سریعتر و بهتر، خواهیم دید، ولی فکر نمیکنم الان بتوانیم چیزی بگوییم. اول اینکه این تکنولوژی هنوز بسیار جوان است و ما هنوز حتی شروع نکردهایم که ببینم آیا کلاینتها و سرورها و به طور کلی «پیادهسازیها» از همهی قدرت این پرتکل جدید استفاده خواهند کرد یا نه.
در طول این سالها، توسعهدهندگان وب، جعبه ابزاری از ترفندها و ابزارها برای حل مشکلات HTTP 1.1 فراهم کردهاند، در اول این کتاب به بعضی از این مشکلات و راهحلها اشاره کردهام.
بسیاری از این راهحلهایی که ابزارها و توسعهدهندگان، این روزها به طور پیشفرض و بدون فکر استفاده میکنند، احتمالا به کارایی http2 آسیب خواهند زد یا حداقل از ابرقدرتهای جدید http2 بهره نخواهند برد. Spriting و Inlining نباید در http2 انجام شوند. Sharding یا توزیعکردن هم به کارایی http2 آسیب میزند و احتمالا تنها از تعداد کانکشنهای کمتر سود خواهد برد.
مشکلی که اینجاست، این است که وبسایتها و توسعهدهندگان آنها باید در مدت کوتاهی، محصولات خود را برای دنیایی ارائه دهند که در آن هم کاربران HTTP 1.1 وجود دارند هم http2 ارائه دهند. ارائهی حداکثر سرعت و کارایی برای همهی کاربران بدون ارائهی دو نوع فرانتاند، چالشبرانگیز خواهد بود.
به همین دلیلها، احتمالا مدتی طول خواهد کشید که ببینیم از همهی ظرفیتهای http2 استفاده میشود.
تلاشکردن برای مستندکردن پیادهسازیهای خاص در چنین نوشتهای، کار بیهودهای است و تنها بعد از مدتی، قدیمی میشود. به جای این کار، شرایط به طور عمومیتری توضیح میدهم و خوانندگان را به در وبسایت http2 ارجاع میدهم.
در ابتدا، پیادهسازیهای بسیاری وجود داشتند و تعداد آنها به مرور زمان افزایش پیدا کرد. در هنگام نوشتن این کتاب، حدود ۴۰ پیادهسازی لیست شدهاند و بیشتر آنها ورژن نهایی را پیاده کردهاند.
فایرفاکس مرورگری بوده که همواره آخرین ویژگیها را پیادهسازی کرده، توییتر نیز سرویسهایش را بر پرتکل http2 ارائه میدهد. گوگل از آپریل ۲۰۱۴ شروع به پشتیبانی از http2 در چند سرور آزمایشی کرد و از می ۲۰۱۴، پشتیبانی از http2 را در ورژنهای توسعهدهندگان Chrome کردند. ماکروسافت نیز یک پیشنمایش از پشتیبانی از http2 در نسخهی بعدی Internet Explorer نشان دهند. سافاری (در iOS 9 و Mac OS X El Capitan) و اپرا نیز هر دو اعلام کردند که به زودی پشتیبانی خواهند کرد.
پیادهسازیهای زیادی از http2 در سمت سرور وجود دارد.
سرور nginx از http2 از نسخهی که در سپتامبر ۲۰۱۵ منتشر شد (این قابلیت، جایگزین ماجول SPDY شد تا نتوانند هر دو در یک سرور اجرا شوند.)
سرور httpd آپاچی نیز یک ماجول http2 به نام از نسخهی ۲.۴.۱۷ دارد که در نهم اکتبر ۲۰۱۵ منتشر شد.
, , , و نیز از http2 پشتیبانی میکنند.
curl و libcurl از http2 ناامن و همچنین امن بر مبنای TLS پشتیبانی میکنند.
Wireshark که بهترین ابزار برای آنالیز ترافیک http2 است نیز پشتیبانی میکند.
هنگام توسعهی این پرتکل، گاهی افراد شک میکردند که احتمالا نتیجه از سوی بعضی به عنوان یک پرتکل اشتباه خوانده خواهد شد. بعضی از انتقادات وارد به این پرتکل و توجیه درست یا غلطبودن آنها را در ادامه میآورم.
این دیدگاه، به روشهای دیگری هم بیان میشود که در آینده، دنیا به گوگل وابسته خواهد شد و یا کنترل میشود. این درست نیست. این پرتکل در IETF و به همان روشی که ۳۰ سال است پرتکلها طراحی میشوند، طراحی شد. اما، همهی ما کار تأثیرگذار گوگل با SPDY را دیدیم که ثابت کرد که نه تنها ممکن است که یک پرتکل جدید منتشر کنیم، بلکه آمارها نشان دادند که چه چیزهایی حاصل خواهد شد.
گوگل به طور عمومی که پشتیبانی از SPDY و NPN را از Chrome در ۲۰۱۶ حذف میکنند و سرورها را مجبور به مهاجرت به HTTP/2 میکنند. در فبریهی ۲۰۱۶ آنها که SPDY و NPN بالاخره در Chrome 51 حذف شدند.
این دیدگاه تا حدودی درست است. یکی از انگیزههای اصلی توسعهی http2، حلکردن مشکل HTTP Pipelining است. اگر برنامهی شما نیازی به این تکنولوژی ندارد، پس احتمالا http2 تأثیر مثبت چندانی بر برنامهی شما نخواهد گذاشت. البته، HTTP Pipelining تنها قابلیت اضافهشده در این پرتکل نیست.
وقتی سرویسها متوجه شوند که قدرت و تواناییهای استریمهای Multiplexed در یک کانکشن چقدر است، احتمال میدهم که اپلیکیشنهای بیشتری از http2 استفاده کنند.
REST APIهای کوچک و برنامههای کوچک مبتنی بر HTTP 1.x احتمالا دلیلی برای مهاجرت به http2 نخواهند یافت. ولی همچنین، معایبهای خیلی کمی برای کاربران این سرویسها بر بستر http2 به چشم میآید.
نه اصلا! قابلیتهای Multiplexing به بهبود تجربهی وبگردی در کانکشنهایی با تأخیر زیاد حتی در سایتهای کوچکی که توزیع جغرافیایی (CDN) ندارند نیز کمک میکند. سایتهای بزرگ معمولا بسیار سریعترند و از سرورهای بیشتری برای کاهش زمان دریافت دادهها استفاده میکنند.
از جهاتی این مورد میتواند صحیح باشد. ارتباط اولیه (Handshake) در TLS میتواند سرعت را تا حدی کاهش دهد، ولی کارهایی در حال انجامشدن است تا این فرآیند سریعتر شود. ولی سربار حاصل از جایگزینی متن ساده با TLS خصوصا در CPU و انرژی، قابلچشمپوشی نیست، در حالی که اگر همان ترافیک و دادهها با متن ساده رد و بدل شوند، انرژی کمتری میبرد. این که میزان تأثیر چهقدر است، مورد بحث بوده و اندازهگیریهایی نیز در این رابطه انجام شده است. برای مثال سایت از نمونهی یکی از این منابع برای آزمایشهای انجامشده است.
برای مثال Telecom و دیگر اپراتورهای شبکه، در اتحاد وب باز ATIS، اعلام کردهاند که به نیاز دارند تا بتوانند Caching، فشردهسازی و تکنیکهای دیگر برای ارائهی تجربهی وب سریعتر را در اختیار کاربران از طریق ماهوارهها قرار دهند. http2 استفاده از TLS را اجبار نمیداند، بنابراین نباید با این بندها تداخلی داشته باشد.
بسیاری از کاربران اینترنت اعلام کردهاند که استفاده از TLS را بهطور گستردهتر ترجیح میدهند، چرا که باعث میشود حریم خصوصی کاربران محافظت شود.
آزمایشها همچنین نشان دادهاند که با استفاده از TLS، شانس بیشتری نسبت به پیادهسازی پرتکلهای متن ساده برای موفقیت وجود دارد، چرا که پرتکلهای متنسادهای که بر پورت ۸۰ پیادهسازی میشوند، موانع زیادی در سرراه خود دارند که ممکن است اختلال ایجاد کنند، چرا که فکر میکنند HTTP 1.1 است که در پورت ۸۰ رد و بدل میشود.
در آخر، به لطف استریمهای Multiplexشدهی http2 بر روی یک کانکشن، مرورگرهای معمولی میتوانند ارتباطهای اولیهی خیلی کمتری بر بستر TLS انجام دهند و در نتیجه سریعتر از HTTPS در HTTP 1.1 عمل کنند.
بله، ما دوست داریم که اطلاعاتی که پرتکلها مبادله میکنند را به طور واضح ببینیم، چرا که ردگیری و دیباگکردن آنها را آسان میکند. ولی پرتکلهای برمبنایمتن به خطا حساس هستند و مشکلات زیادی را برای پردازش متنهای گرفتهشده دارند.
اگر شما نمیتوانید یک پرتکل باینری را تحمل کنید، بنابراین نباید اصلا از TLS و فشردهسازی در HTTP 1.x استفاده کنید، با این که هر دو مدت زیادی است که وجود دارند.
این موضوعی شکبرانگیز و بحثبرانگیز است که دقیقا سریعتر چه معنایی دارد، ولی در SPDY، قبلا آزمایشهای زیادی انجام شده که ثابت میکند سرعت بارگذاری صفحات در مرورگرها بیشتر میشود (مثل که توسط افرادی در دانشگاه واشنگتن تهیهشده یا که توسط Hervé Servy نوشته شده) و چنین آزمایشهایی با http2 هم تکرارشدهاند. من منتظر دیدن آزمایشهای بیشتری هستم. یک ساختهشده که نشان میدهد HTTP/2 به قولهای خود وفا میکند.
جدا این نقد شماست؟ لایهها جزئی از یک دین مقدس جهانی نیستند که نتوان به آنها دست زد. ما به منطقههای خاکستری (نسبتا خطرناک) وارد شدیم تا http2 را یک پرتکل خوب و مؤثر در چارچوب مرزها کنیم.
این درست است. چون هدف ما، حفظ پاراداریمهای HTTP/1.1 بود، بعضی از قابلیتهای قدیمی HTTP باید میماندند، مثل هدرهای مرسوم که معمولا شامل Cookies هم میشدند، هدرهای احراز هویت و غیره. ولی مزیت نگهداشتن این پارادایمها این است که ما پرتکلی داریم که انتشار آن، بدون حجم زیادی از کار برای بهروزرسانی آن و جایگرینی زیرساختهای قبلی، ممکن است. http2 اساسا فقط یک لایهی جدید برای Framing است.
هنوز بسیار زود است که بتوانیم با یقین حرف بزنیم، ولی میتوانیم حدسهایی بزنیم که آن را در ادامه میآورم.
مخالفان خواهند گفت که «ببینید که IPv6 چقدر خوب عمل کرده!» تا مثالی برای پرتکل جدیدی بیاورند که دههها طول کشید تا به طور جهانی گسترش یابد. البته، پرتکل http2 اصلا شبیه IPv6 نیست. این پرتکلی بر مبنای TCP است و از همان مکانیزمهای آپگرید HTTP، همان شمارهی پورتها و همان TLS استفاده میکند و نیازی به تغییر روترها و فایروالها ندارد.
گوگل با SPDY به دنیا ثابت کرد که یک پرتکل مانند این میتواند به طور جهانی گسترش یابد و در مرورگرها و سرویسها با پیادهسازیهای مختلف در مدت زمان نسبتا کوتاهی استفاده شود. در حالی که تعداد سرویسهایی که SPDY را ارائه میدهند، در حدود ۱٪ است، ولی مقدار دادههایی که این سرویسها مبادله میکنند بسیار بزرگ است. بعضی از پرطرفدارترین وبسایتهای امروزی، SPDY ارائه میدهند.
http2 بر مبنای همان پارادایمهای SPDY است، میتوانم بگویم که احتمال گسترش آن نسبت به SPDY بسیار بیشتر است، چرا که استانداردی است که از سوی IETF ارائه میشود. توسعهی SPDY همیشه با توجیه اینکه «پرتکل ساختهی گوگل است» پس زده شده.
مرورگرهای بسیاری از این بهروزرسانی حمایت کردند. نمایندگانی از Firefox, Chrome, Safari, Internet Explorer و Opera اعلام کردهاند که مرورگرهای http2 خود را ارائه کردهاند یا خواهند کرد.
اپراتورهای سرویسهای بزرگ به زودی http2 را ارائه خواهند داد، مانند گوگل، توئیتر و فیسبوک. امیدواریم که به زودی پشتیبانی از http2 را در پیادهسازیهای سمتسرور مانند Apache httpd و nginx ببینیم. H2O نیز یک سرور HTTP سریع است که از http2 نیز پشتیبانی میکند.
بعضی از بزرگترین فروشندگان پراکسی، مثل HAProxy, Squid و Varnish نیز تمایل خود را برای پشتیبانی از http2 اعلام کردهاند.
در سراسر سال ۲۰۱۵، ترافیک http2 در حال افزایش بوده است. در اوایل سپتامبر، سهم فایرفاکس ۴۰ از ترافیک HTTP حدود ۱۳٪ و از HTTPS حدود ۲۷٪ بوده، در حالی که گوگل حدود ۱۸٪ از درخواستهای ارسالی را HTTP/2 میدانسته. باید به این نکته توجه داشت که گوگل در حال آزمایش پرتکلهای جدیدتری است (QUIC را در قسمت ۱۲.۱ ببینید) که میزان استفادهی http2 را از آنچه که میتوانست باشد، کمتر میکند.
Entonces, ¿Cómo serán las cosas cuando http2 sea adoptado? ¿Será adoptado?
http2 aún no está ampliamente ni desplegado ni usado. No podemos decir como serán las cosas. Hemos observado como se ha usado SPDY y se pueden hacer suposiciones y cálculos basados en éste y otros experimentos pasados y presentes.
http2 reduce el número de “round-trips” de red necesarios y con la multiplexación y el descarte rápido de flujos no deseados, evita el dilema del bloqueo del primero de la fila.
El protocolo permite un alto número de flujos paralelos más allá de cualquier sitio que actualmente utilice la técnica de dominios fragmentados (sharding).
Utilizando la funcionalidad de prioridades correctamente en los flujos, hay altas probabilidades de que el cliente realmente reciban la información importante antes de la información menos priorizada. Juntando todo esto, diría que existe una muy buena oportunidad de que se esté apuntando a tiempos de carga mucho más rápidos así como hacia sitios web más reactivos. En pocas palabras: un mejor experiencia web.
No creo que se pueda decir todavía cuánto más rápido o cuantas mejoras vamos a llegar a ver. Para empezar la tecnología está todavía en un fase muy temprana y aún no se ha comenzado a ver clientes y servidores ajustando implementaciones para aprovechar todo el poder que nos está ofreciendo el nuevo protocolo.
Durante los años los desarrolladores web así como sus entornos de desarrollo, han ido recopilando una gran colección de trucos y herramientas para solventar los problemas con HTTP 1.1, de los que he hablado al comienzo del este documento como justificación principal para http2.
Muchos de estos atajos que tanto herramientas como desarrolladores utilizan por defecto sin pensar, probablemente afectarán negativamente el rendimiento de http2, o al menos hará que no se aprovechen los nuevos súper poderes de http2. Tanto “spriting” como “inlining”, probablemente no deban utilizarse con http2. La fragmentación en varios dominios (“sharding”), será perjudicial en http2, ya que probablemente haya más beneficio utilizando menos conexiones..
El principal problema es por supuesto que tanto los sitios web como los desarrolladores web, necesitarán desarrollar y desplegarse en un mundo en el que a corto plazo al menos, existan clientes tanto HTTP1.1 como http2, de manera que el reto será conseguir el máximo rendimiento sin tener que ofrecer dos frontales diferentes.
Únicamente por estas razones, sospecho que pasará algo de tiempo antes de que veamos alcanzado el máximo potencial de http2.
Intentar documentar las implementaciones especificas en un documento como este, es por supuesto hacerlo en vano y está condenado al fracaso porque estará desfasado en un periodo muy corto de tiempo. En lugar de esto, explicaré la situación en un término más amplio y simplemente haré una referencia para los lectores hacia a la en el sitio web de http2.
Han existido una gran cantidad de implementaciones desde un primer momento, y este número ha ido incrementándose durante el trabajo con http2. Mientras se escribe esto, existen más de 30 implementaciones listadas, la mayoría implementando la versión final.
Firefox ha sido el navegador que ha estado encabezando los borradores más nuevos. Twitter ha estado a la altura ofreciendo sus servicios sobre http2. Google ha comenzado a ofrecer soporte http2 en algunos servidores de pruebas desde abril de 2014 y desde mayo de 2014, han ofrecido soporte http2 en las versiones de desarrollo de Chrome. Microsoft ha presentado que soporta http2 desde una “tech preview” de su próxima versión de Internet Explorer.
Tanto curl como libcurl soportan http2 inseguro así como basado en TLS utilizando una de las distintas bibliotecas TLS.
, y han publicado todos ellos servidores con soporte para http2.
Las dos opciones más populares en servidores web, Apache HTTPD y Nginx ofrecer soporte para SPDY, pero todavía no han publicado soporte oficial para http2 en ningún release. Ngnix ha publicado un así como el módulo de Apache parar HTTP/2 denominado parece que está encaminado a ser incluído en una release pública muy pronto.
Durante el desarrollo de este protocolo ha existido cierto debate en determinados aspectos, y algunas personas creen que el protocolo se ha diseñado completamente mal. Me gustaría mencionar algunas de las quejas más comunes, así como los argumentos en su contra:
Existen variaciones que implican un mundo todavía más dependiente o controlado por Google. No es cierto. El protocolo ha sido desarrollado desde el IETF de la misma manera en la que se han venido desarrollando protocolos en los últimos 30 años. De cualquier manera, todo reconocemos el impresionante trabajo hecho por Google con SDPY que no solo demostró que era posible desplegar un nuevo protocolo sino que también aportó los números que indicaban que se podrían conseguir mejoras.
Google ha públicamente1 que van a retirar el soporte para SPDY y NPN en Chrome a partir de 2016, y que aconsejan a los servidores utilizar HTTP/2 en su lugar.
Esto es medio verdad. Una de las principales razones para el desarrollo de http2, es arreglar HTTP pipelining. Si tu caso de uso no tiene problema, entonces es probable que http2 no te suponga demasiada mejora. Aunque ésta no sea la mejora principal en el protocolo, es bastante significativa.
Según distintos servicios se vayan dando cuenta del gran poder y posibilidades que tienen los flujos multiplexados a través de una única conexión, sospecho que veremos más aplicaciones utilizando http2.
Pequeñas APIs REST o uso más simples de programación con HTTP 1.x puede que no encuentren que el salto a http2 ofrezca demasiadas ventajas. Aunque igualmente, tampoco deberían existir demasiados inconvenientes con http2 en la mayoría de los casos.
Para nada. La capacidad de multiplexar mejorará notablemente la experiencia de usuario para sitios pequeños con conexiones de altas latencias sin distribuciones geográficas. Los sitios más grandes suelen ser más rápidos, ofreciendo conexiones distribuidas, con tiempos “round-trip” más cortos para los usuarios.
Esto puede ser cierto hasta cierto punto. El “handshake” TLS añade un poco de tiempo extra, pero actualmente se está trabajando en reducir el número de viajes “round-trips” necesarios para TLS. El trabajo extra para hacer TLS a través de la conexión comparado con texto plano no es insignificante y es claramente notable al usar más CPU y energía para un mismo patrón de tráfico sobre protocolo no seguro. Cuantificar cuanto y su impacto está sujeto a opiniones y medidas. El sitio istlsfastyet.com ofrece por ejemplo una fuente de información.
Telecom y otros operadores de red, por ejemplo la ATIS Open Web Alliance, han dicho que necesitan tráfico no cifrado1 para ofertar cacheo, compresión u otras técnicas necesarias para ofertar una experiencia de usuario rápida a través de satélites, en aviones por ejemplo.
http2 no establece el uso de TLS como obligatorio, así que no se deberían combinar los términos. Muchos usuarios de Internet han expresado preferencia en un uso más extenso de TLS para que podamos ayudar a proteger la privacidad de los usuarios.
Ciertos experimentos han demostrado que usar TLS aporta un mayor índice de éxito que implementar nuevos protocolos en texto plano a través del puerto 80 ya que existen demasiados dispositivos desplegados en el mundo que pueden interferir con aquello que crean que es HTTP1.1 si es que va por el puerto 80 y puede parecer HTTP a veces.
Por último, gracias a la multiplexación de flujos de http2 en una única conexión, en el caso de uso de navegadores normales, se realizarán muchos menos “handshakes” TLS, así que se conseguirá un rendimiento más raṕido qe utilizando HTTPS sobre HTTP 1.1.
Si, nos gusta ser capaces de ver los protocolos claramente, ya que lo hace mucho más fácil para debuggear y tracear. Pero los protocolos basados en texto son más susceptibles a error, y provocan muchísimos errores en su interpretación.
Si no soportas un protocolo binario, entonces estas descartando TLS o la compresión en HTTP 1.x, que han estado utilizando muchísimo tiempo.
Por supuesto que es algo sujeto a debate y a discusión en cómo se mide que significa más rápido, pero ya en los días de SPDY, se realizaron multitud de pruebas que demostraban que la página cargaba más rápido (por ejemplo de la gente de la Univesidad de Washington y por Hervé Servy) y dichos experimentos se han repetido también con http2. Tengo ganas de ver publicados los resultados de esas pruebas y experimentos.
Una primera prueba básica realizada por podría implicar que HTTP/2 cumple sus promesas.
En serio, ¿es eso tu argumento? Las capas no son pilares intocables de una religión global y si hemos pasado algunas zonas grises al hacer http2, ha sido en interés de hacer un protocolo bueno y efectivo a partir de las premisas iniciales.
Eso es cierto. Con el objetivo específico de mantener los paradigmas HTTP/1.1, hemos tenido que mantener ciertas funcionalidades anticuadas. Por ejemplo ciertas cabeceras comunes como las temidas cookies, cabeceras de autenticación y más. Como contrapunto al mantenimiento de estos paradigmas, se ha conseguido un protocolo que puede desplegarse sin la obligación de sustituir o reescribir una inconcebible cantidad de trabajo en dicha actualización. http2 es básicamente una nueva capa de “framming”.
Es demasiado pronto para afirmarlo con seguridad, pero puedo suponer y hacer una estimación, y eso es lo que haré aquí.
Los “no-nos” dirán “mira que bien hecho está IPv6” como ejemplo de un nuevo protocolo que ha necesitado décadas para empezar a estar ampliamente desplegado. Aunque http2 no es IPv6. Es un protocolo por encima de TCP que usa los mecanismos de actualización normales de HTTP, sus números de puerto, TLS, etc. No va a necesitar que cambien para nada la mayoría de routers o firewalls.
Google demostró al mundo con su trabajo con SPDY que un nuevo protocolo como este puede ser desplegado y utilizado por navegadores y servicios desde distintas implementaciones en un periodo de tiempo razonablemente corto. Aunque la cantidad de servidores en Internet ofreciendo SPDY está en ñle rango del 1%, la cantidad de información que manejan esos servidores es mucho más grande. Algunos de los sitios web más populares actualmente en el mundo, ofrecen SPDY.
http2, basado en los mismos paradigmas básicos que SPDY, diría que tiene más probabilidades de ser desplegado desde que es un protocolo del IETF. El despliegue de SPDY siempre fue algo retenido por el estigma de “ser un protocolo de Google”.
Hay varios grandes navegadores detrás del despliegue. Representantes de Firefox, Chrome e Internet Explorer han expresado que ofrecerán navegadores con soporte http2 y ya han mostrado implementaciones funcionando.
Existen grandes operadores de servidor que van a ofrecer http2 pronto, entre los que se incluye Google, Twitter y Facebook así como esperamos ver soporte http2 pronto en servidores web populares como Apache HTTP Server y nginx. H2o es un nuevo increíblemente rápido servidor HTTP con soporte http2que tiene potencial.
Algunos de los fabricantes de proxy más grandes, incluyendo HAProxy, Squid and Varnish han manifestado intenciones de añadir soporte http2.
Casi a finales de 2015, la cantidad de tráfico en http2 ha continuado incrementándose. A comienzos de septiembre, el uso en Firefox 40 era del 13% del total del tráfico HTTP y el 27% del tráfico HTTPS, mientras que Google está recibiendo aproximadamente un 18% de trafico HTTP/2. Hay que tener en cuenta que Google está experimentando con nuevos protocolos (ver QUIC en la sección 12.1), lo que hace bajar las medidas de uso para http2.
Que donnera le monde une fois http2 adopté ? http2 sera-t-il adopté ?
http2 n'est pas encore largement déployé ou utilisé. Nous ne pouvons savoir ce qu'il adviendra. Nous avons vu comment SPDY a été utilisé et pouvons estimer et calculer l'adoption de http2 à partir de ces expérimentations passées et actuelles.
http2 réduit le nombre d'aller-retours nécessaires et évite le head of line blocking en multiplexant et en se débarrassant des flux non voulus.
Il permet un nombre important de flux parallèles, plus important que ce qui est requis par les sites utilisant massivement le sharding aujourd'hui.
Si les priorités de flux sont utilisées correctement, on a une chance que les clients obtiennent les données les plus importantes avant les moins importantes. Tout compris, je dirais qu'il y de très bonnes chances pour que cela mène à un meilleur temps de chargement des pages et à des sites web plus réactifs. En résumé: une meilleure expérience web.
Dans quelle mesure cela sera plus rapide, je ne pense pas qu'on puisse y répondre pour l'instant. La technologie est encore très jeune et nous n'avons pas encore vu d'implémentations client et serveur tirer parti de toutes les possibilités que le protocole offre.
Avec le temps, les développeurs Web et les environnement de développement ont accumulé plein d'astuces et outils pour contourner les limitations de HTTP 1.1, souvenez-vous de tout ce qui a été indiqué en début de document pour justifier http2.
Beaucoup de contournements utilisés par défaut sans y penser, pénaliseront probablement les performances de http2 ou ne permettront pas l'utilisation des super pouvoirs de http2. Spriting et inlining ne devraient probablement pas être utilisés avec http2. Le sharding pénalisera http2 car il bénéficiera de moins de connexions.
Un problème ici est bien sûr que les sites et développeurs web devront avoir, au moins dans un premier temps, des versions s'accommodant de clients HTTP1.1 et http2. Et avoir les meilleures performances pour tous ces utilisateurs sera compliqué sans devoir afficher deux front-ends différents.
Pour ces seules raisons, je pense qu'il faudra du temps avant de tirer le plus grand bénéfice de http2.
Essayer de documenter des implémentations particulières dans un document comme celui-ci est futile et voué à l'échec car il sera obsolète en peu de temps. À la place, je vous explique la situation en termes plus généraux et vous renvoie à la http2 sur le site web.
Il y avait déjà un certain nombre d'implémentations très tôt, et ce nombre a augmenté pendant le travail sur http2. À ce jour, il existe 30 implémentations connues, et la plupart se basent sur la version finale de http2.
Firefox a été le navigateur le plus en avance, Twitter a suivi et propose ses services en http2. Google commença en avril 2014 à offrir ses services en http2 sur quelques serveurs et depuis mai 2014 via les versions de développement de Chrome. Microsoft a montré une préversion d'Internet Explorer supportant http2.
curl et libcurl supportent http2 non-TLS et TLS à partir d'une des librairies TLS disponibles.
Les deux serveurs les plus populaires, Apache HTTPD et Nginx, supportent tous deux SPDY mais à la date du 22 Septembre 2015, seul Nginx a publié une version supportant officiellement http2. Nginx a publié et le module HTTP/2 pour Apache, nommé , est en bonne voie pour être embarqué "bientôt" dans une nouvelle version.
Pendant le développement de ce protocole, les débats n'ont jamais cessé et plusieurs personnes pensent que ce protocole a mal fini. Je voudrais ici lister quelques problèmes et les discuter :
Cela implique aussi que le monde devient davantage dépendant de Google. Ce n'est pas vrai. Le protocole a été développé à l'IETF de la même manière que tous les autres protocoles depuis 30 ans. Cela dit, nous reconnaissons tous le travail impressionnant réalisé par Google sur SPDY qui a permis de montrer qu'on pouvait déployer un nouveau protocole avec, de plus, des données chiffrées sur les gains obtenus.
Google a publiquement qu'ils retireraient le support de SPDY et NPN de Chrome en 2016 et qu'ils poussaient les serveurs à migrer vers HTTP/2 à la place.
C'est plutôt vrai. Une des principales raisons derrière le développement de http2 est de corriger le pipelining HTTP. Si votre cas d'usage n'avait pas besoin de pipelining alors il y a des chances que http2 n'améliore pas beaucoup votre situation. Ce n'est pas la seule amélioration du protocole mais une amélioration majeure.
Quand les différents services réaliseront la puissance des flux multiplexés sur une seule connexion, je pense que nous verrons davantage d'applications tirant parti de http2.
Les APIs REST simples utilisant HTTP 1.x ne verront pas d'avantages à passer à http2. Cela dit, il y aura peu d'inconvénients à passer à http2 pour la plupart des gens.
Pas du tout. Les capacités de multiplexage vont énormément améliorer l'expérience des connexions à latence importante pour les petits sites n'ayant pas de présence mondiale.
Les gros sites ont déjà une présence mondiale et du coup des aller-retours moins longs vers la plupart des utilisateurs.
Cela peut se révéler vrai. La négociation TLS ajoute un peu de latence, mais il existe des projets pour réduire encore les aller-retours en TLS. La surcharge du TLS par rapport à du texte en clair n'est pas neutre et a un impact CPU. L'impact en lui-même est sujet à discussions et mesures. Voir par exemple pour avoir une source d'information.
Les opérateurs télécom et réseaux, par exemple l'ATIS Open Web Alliance, indiquent qu'ils nécessitent du pour permettre au cache et à la compression de fonctionner, notamment pour une expérience web rapide par satellite. http2 n'oblige pas à utiliser TLS, on ne devrait donc pas mélanger les deux.
De nombreux utilisateurs ont indiqué leur préférence à utiliser TLS et nous devrions respecter ce droit à la vie privée.
Des expérimentations ont montré que l'utilisation de TLS a une meilleure probabilité de succès qu'avec un protocole en clair sur le port 80. Il y a trop de boîtes intermédiaires sur le réseau qui vont perturber le trafic sur le port 80 en imaginant qu'il n'y a que du trafic HTTP 1.1 sur ce port.
Enfin, grâce aux flux multiplexés que permet http2 sur une seule connexion, les navigateurs initieront moins de négociations TLS et iront finalement plus vite qu'avec HTTPS en HTTP 1.1.
Oui, nous préférons voir des protocoles en clair car le debugging en est facilité. Mais un protocole texte est aussi davantage sujet à des problèmes de parsing.
Si vous ne pouvez pas vous faire à un protocole binaire, alors vous ne pouviez pas vous faire non plus à TLS ni à la compression, utilisés depuis longtemps en HTTP 1.x.
Cela est bien sûr sujet à débat sur comment qualifier "plus rapide"; les tests menés lors des expérimentations SPDY montraient des temps de chargement de pages web plus rapides (voir par University of Washington et par Hervé Servy). Idem en http2 avec d'autres tests. Je souhaite voir davantage de tests publiés. Un a tendance à montrer que HTTP/2 répond aux promesses.
http2 est clairement plus rapide dans certains scénarios, en particulier avec les scénarios où une connexion à latence importante est utilisée avec un site comportant beaucoup de ressources à charger, ce nombre ayant tendance à augmenter.
Sérieusement ? Les couches OSI ne sont pas intouchables, nous avons franchi des zones grises avec http2 dans l'intérêt de le rendre efficace dans les limites imposées.
C'est vrai. L'objectif de conserver certains paradigmes HTTP/1.1 font que certaines vieilles fonctionnalités restent. Par exemple les en-têtes conservent les cookies, l'authentification et davantage. Mais en maintenant ces principes nous avons un protocole qu'il est possible de déployer sans réécrire ou remplacer des parties protocolaires considérables. http2 est juste une nouvelle couche de framing.
Il est encore trop tôt pour le dire, mais je peux le deviner et l'estimer, voici comment.
Les esprits négatifs montreront "regardez comme IPv6 a marché" comme un exemple qui a pris des décennies pour juste commencer à être largement déployé. http2 n'est pas IPv6. C'est un protocole au-dessus de TCP utilisant les mécanismes d'upgrade HTTP, un port standard, TLS, etc. Il ne requiert pas un changement de la plupart des routeurs et firewalls.
Avec SPDY, Google a prouvé au monde que l'on pouvait déployer et utiliser un nouveau protocole en peu de temps. Même si la somme des serveurs SPDY avoisine les 1% aujourd'hui, le volume de données est plus important. Certains des plus gros sites utilisent SPDY.
http2, basé sur les mêmes principes que SPDY et ratifié par l'IETF, devrait être encore plus largement déployé. Les déploiements SPDY ont toujours été limités par le syndrome "inventé par Google"
Il y a plusieurs navigateurs importants derrière http2. Des représentants de Firefox, Chrome, Safari, Internet Explorer et Opera ont tous indiqué leur intention de livrer des navigateurs avec http2 et ont montré des implémentations fonctionnelles.
Plusieurs gros sites proposent http2, avec Google, Twitter et Facebook et nous espérons que http2 sera ajouté aux serveurs Apache HTTP et nginx. H2o est un nouveau serveur très rapide supportant http2 avec beaucoup de potentiel.
Les plus gros proxy, HAProxy, Squid et Varnish ont mentionné leur intention de supporter http2.
Je pense qu'il y aura davantage d'implémentations quand la RFC sera ratifiée.
Durant tout 2015, la quantité de trafic en http2 n'a cessé d'augmenter. Au début Septembre, sur Firefox 40, il génère 13% de tout le trafic HTTP, et 27% du trafic HTTPS, tandis que Google voit 18% de HTTP/2. Il faut noter que Google déroule d'autres expérimentations en parallèle (voir QUIC en 12.1), ce qui rend la quantité de trafic http2 plus basse que ce qu'elle aurait pu être.
http2が普及すると世の中はどうなるのでしょう。そもそも普及するのでしょうか。
http2はまだ広くデプロイされておらず、また使われていません。我々は今後どうなっていくのか自信を持ってここで語ることはできません。我々はSPDYがどのように使われているか見てきました。その経験やその他の過去および現在の実験をもとに推測や計算をすることができます。
http2はネットワークラウンドトリップの回数を削減します。ヘッドオブライン・ブロッキングのジレンマを多重化と不必要なストリームをすぐに捨て去ることにより完全に回避します。
今日もっともシャーディングが多用されているサイトよりも多くの並行ストリームを使用することができます。
優先度をストリームに適切に適用することで、クライアントは重要なデータをあまり重要ではないデータの前に受信することができる可能性が高まります。これらを総合的にみると、高速なページロード、そしてよりレスポンシブなwebサイトを実現できる可能性が高いと言えます。単刀直入にいって、よりよいwebのエクスペリエンスにつながるのです。
Non sarebbe carino creare un protocollo più potente ? Si, si ..
Meno sensibile alla latenza
Con un miglior pipelining e fine dei bloccaggi "inizio della fila"
Che elimini il bisogno di incrementare il numero di connessioni per host
どの程度速くなるのか、またどの程度改善するのか、といったことはまだわかりません。まず第一に、この技術はまだ初期の段階であり、これらプロトコルが提供する能力を余すところなく使い切るクライアントとサーバー実装はまだありません。
この何年かでweb開発者とweb開発環境はトリックや道具をたくさんかき集めてきてHTTP 1.1の問題を回避してきました。私がこの文書の最初にhttp2の正当性の証としてそれらの中のいくつかを紹介したことを思い出してください。
ツールや開発者が今日何も考えないで使っているこれらの回避策の多くはおそらくhttp2の性能に悪影響を与える、または、少なくともhttp2のすばらしい能力を余すところなく使いこなすことができない、ということになるでしょう。スプライティングとインライニングは殆どの場合http2ではすべきではありません。シャーディングもhttp2にはおそらくよくない結果となるでしょう。というのはhttp2は少ない接続数から恩恵を得るからです。
ここでの問題はもちろんwebサイトとweb開発者は、少なくとも短期間はHTTP 1.1とhttp2のクライアント両方のために開発とデプロイをする必要があることです。全ユーザーに最高の性能を提供することは2つの異なるフロントエンドの提供なくしては容易ではありません。
この理由だけをとってみても、http2の潜在能力が完全に発揮されるまでは少し時間がかかると私は考えています。
特定の実装についてこの文書で触れることは、もちろん理にかなったことではありませんし、失敗することは目に見えています。ほんの少し時間が経てば古くなってしまいます。そういうことはせず、私は広い視点での状況を説明することにして、読者には実装のリストを参照していただくことにします。
早くから多くの実装が存在していて、http2の作業中にも増えてきました。この文書の執筆時において40を超える実装がリストに載っており、それらのほとんどは最終版を実装しています。
Firefoxは最新ドラフトにもっとも速く追随してきたブラウザです。Twitterは最新版に追随しサービスをhttp2で提供しています。Googleは2014年4月頃からGoogleのサービスを提供するテストサーバーでhttp2をサポートしていて、2014年5月から開発版のChromeでhttp2サポートを提供しています。マイクロソフトは次期Internet Explorerとしてhttp2をサポートしたプレビュー版を公開しました。SafariとOperaはhttp2に対応予定であると言っています。
既に多くのサーバがhttp2をサポートしています。
人気のあるNginxサーバは2015年9月22日の1.9.5からhttp2を提供しています。 (SPDYモジュールの置き換えが必要で、SPDYモジュールとhttp2の共存はできません。)
Apacheのhttpdサーバは2015年10月9日にリリースされた2.4.17からhttp2モジュール mod_http2 が提供されています。
H2O、Apache Traffic Server、nghttp2、Caddy、LiteSpeedは全てhttp2が使用できます。
curlとlibcurlは平文とTLS両方のhttp2をサポートしています。複数のTLSライブラリで対応を行っています。
Wiresharkはhttp2をサポートしています。http2のネットワークトラフィックを分析するための完璧なツールです。
このプロトコルの開発中、議論は前後しました。もちろんこのプロトコルは完全に間違いであると信じている人も確かにいました。私はよくある批判のいくつかに言及し、それに対する回答を述べたいと思います。
世界はさらにGoogleに依存または支配されていくことを示唆するような亜種の批判もあります。このプロトコルはここ30年間に開発されたプロトコルと同様の手法でIETFによって開発されました。しかしながら我々はSPDYにおけるGoogleのすばらしい仕事を認めています。それは新しいプロトコルがデプロイできるということを証明しただけでなく、それによりどのような効果が得られるのかを示す数値も提供しました。
Googleが公式に発表したところによると、SPDYとNPNをChromeから2016年に削除し、サーバーもHTTP/2に移行していくことを急ぐということです。
これはある意味本当です。http2の開発を裏で牽引した主要なものの一つはHTTPパイプライニングを修正することです。あなたのユースケースがパイプライニングを必要としないのなら、http2はあまり大きな効果をもたらさないかもしれません。これだけがプロトコルにおける改善点ではありませんが、しかし大きな改善点の一つです。
サービスが1接続上の多重化されたストリームがもたらす真の力と能力を理解し始めるとすぐに、我々はより多くのアプリケーションがhttp2を使うことを目にすることでしょう。
小さなREST APIや簡素なHTTP 1.xのプログラムにおけるユースケースはhttp2へ移行しても大きな利点を得られません。しかし、また、ほとんどのユーザーにとってhttp2がもたらす欠点はほとんどないはずです。
そんなことはありません。多重化の能力は、地理的に広範囲に分散していない小さなサイトでありがちな遅延の大きい接続におけるエクスペリエンスを大きく向上させることに寄与するでしょう。大規模サイトはほとんどの場合もうすでに速くてより分散していて短いラウンドトリップ時間をユーザーに提供しています。
これはある程度真実だといえます。TLSハンドシェイクは少し余計に時間がかかります。しかしTLSにおいて必要なラウンドトリップを削減する試みが今までもありましたし、現在も進行中です。通信路上で平文ではなくTLSを使うことによるオーバーヘッドは無視できないし、より多くのCPUと電力が同じトラッフィクパターンの平文に比較して使われることになります。それがどのくらいでどの程度の影響力を持つのかについては意見や測定結果次第です。有用な情報源の例としてistlsfastyet.comを参照してください。
電話会社や他のネットワーク事業者、例えばATISオープンWebアライアンス、は、サテライトや機内のようなところでの高速なwebエクスペリエンスを提供するためにキャッシング、圧縮、その他諸々の技術が必要であり、それには平文のトラッフィクが必要だと言っています。http2はTLSを必須としているわけではありませんのでこれ以上議論を複雑にすべきではありません。
多くのインターネットユーザーはTLSが広く使われることを望んでいますし、我々はユーザーのプライバシー保護を促進すべきです。
実験ではTLSを使うと新しいプロトコルを80番ポートで実装するよりも高い成功率があることを示しています。というのは数えきれない中継器が世界に存在していて、80番ポートを通るならHTTP 1.1だと思い込んで、ときどきHTTPにみえることもあるからですが、妨害するからです。
最後に、http2の1接続上に多重化されたストリームの恩恵により、通常のブラウザーのユースケースではTLSハンドシェークの回数が削減されることになりHTTP 1.1を使うHTTPSよりも速くなる可能性もあります。
はい、我々は平文でプロトコルを見ることができるということを好みます。なぜならデバッギングやトレースが容易になるからです。しかしテキストベースのプロトコルはエラーを誘発しやすく、より多くのパースにおける問題を引き起こします。
あなたが本当にバイナリプロトコルを使えないというのなら、HTTP 1.xのTLSや圧縮も扱えなかったはずですが、これらは長い間我々と共にあって使われてきたのです。
これについては、もちろん速いというのが何を意味してどうやって計測するのか議論しなければなりませんが、SPDYの頃から多くのテストが行われていて速いページロードを証明しています(例えば、ワシントン大学の人々による"How Speedy is SPDY?"、Hervé Servyによる"Evaluating the Performance of SPDY-enabled Web Servers")。このような実験はhttp2でも同様に繰り返されてきました。私はより多くのこのようなテストや実験が公開されることを楽しみにしています。httpwatch.comによる最初の基本的なテストはHTTP/2がその約束を果たしていることを示唆しています。
本気でそう思っていますか?層は世界的な宗教の触ることができない聖なる柱ではありません。我々がhttp2の開発に際し、グレーゾーンに足を踏み入れた時は、与えられた制約の中で効率のいいプロトコルを作るという意思をもってのことでした。
これは本当です。HTTP 1.1のパラダイムを維持するという目的に沿い、いくつかの古いHTTPの機能は残されました。よく使われる、もう見たくもないcookieやauthorizationヘッダーなどがそうです。しかしこれらのパラダイムを維持したお陰で、基本的な部分を完全に書き換えるというアップグレード時の頭のくらくらするような膨大な作業なしにデプロイできるプロトコルを得ました。http2は基本的に新しい層の一つです。
回答するには時期尚早ですが、私なりに推測と予測をしてみたいと思います。
反対論者は普及が開始するのに数十年もかかる新しいプロトコルの例としてこういうでしょう。”IPv6が何をなしてきたかみてみろ”と。しかしながらhttp2はIPv6ではありません。それはTCP上で動作し、普通のHTTPアップグレードメカニズムやポート番号そしてTLS等を使います。ほとんどのルーターやファイヤーウォールを変更する必要はありません。
GoogleはSPDYにより、短期間で新しいこのようなプロトコルがデプロイできて、ブラウザーやサーバーの複数の実装間で使うことができるということを証明しました。インターネットで今日SPDYをサポートするサーバーの数は1%の域ですが、これらサーバーが扱うデータの量ははるかに大きいのです。今日におけるいくつかの極めて人気のあるwebサイトはSPDYをサポートしています。
http2はSPDYと基本的に同じパラダイムを有しますが、IETFのプロトコルであることから、より広くデプロイされるだろうと私は考えています。SPDYのデプロメントは”Googleのプロトコル”という汚名により若干縮小気味です。
有名なブラウザーもリリースを控えています。Firefox、Chrome、Safari、Internet Explorer、Operaの代表者たちはhttp2をサポートするブラウザーを出荷すると表明していますし、実際に動く実装を世界に示しています。
Google、Twitter、Facebookといった巨大なサーバー事業者もhttp2を近々サポートする予定です。我々はApache HTTPサーバーやNginxといった人気のあるサーバー実装にhttp2が実装されることを望んでいます。H2Oはとてつもなく高速なHTTPサーバーでhttp2をサポートしていてその潜在能力を示しています。
HAProxy、Squid、Varnishといった巨大プロキシーベンダーはhttp2サポートの意思を示しています。
2015年全体を通して、HTTP/2のトラフィック量は増加しています。9月の初めにおいて、Firefox 40での使用率はHTTP全体の中の13%、HTTPSに限定すると27%でした。Googleは18%のトラフィックがhttp2だったと言っています。Googleは他の新しいプロトコルの実験も同時に行っている(12.1のQUICを参照してください)ので、http2の使用率は低く出てしまうことに注意してください。
Che mantenda tutte le interfacce esistenti, i contenuti, i formati URI e gli schemi
Che sia sviluppato a contatto con il gruppo di lavoro IETF HTTPbis
La Internet Engineering Task Force (IETF) è una organizzazione che sviluppa e promuove gli standard dell'internet, soprattutto a livello di definizione di protocolli. Sono da sempre consosciuti per le serie di memo RFC riguardanti argomenti quali TCP, DNS e FTP, best practices, HTTP e numerose varianti che non si sono mai trasformate in niente di più.
All'interno di IETF, gruppi di lavoro dedicati sono stati istituiti al fine di lavorare in direzione di un obiettivo comune, in un dominio limitato. Stabiliscono un "charter" ed alcune linee-guida (e limiti) rispetto alle aspettative. Chiunque è benvenuto ad aggiungersi, a partecipare alla discussione e allo sviluppo. Chiunque partecipi e dica qualcosa di concreto ha lo stesso peso nell'influenzare l'esito del lavoro finale ed intermedio. Tutti i membri sono considerati allo stesso livello, senza troppa importanza rispetto al datore di lavoro.
Il gruppo di lavoro HTTPbis (vedi più avanti per la spiegazione del nome) è stato formato durante l'estate 2007 ed incaricato di creare un aggiornamento delle specifiche HTTP 1.1. All'interno del gruppo la discusssione a proposito di una futura versione è iniziata in tardo 2012. Il lavoro di aggiornamento su HTTP 1.1 è stato completato nel 2014 ed ha prodotto come risultato la serie di RFC 7230
Il meeting finale per il GdL HTTPbis inter-op si è tenuto a New York City ad inizio Giugno 2014. Le restanti discussioni e le procedure IETF svolte per pubblicare definitivamente la RFC si sono svolte fino all'anno successivo.
Alcuni dei più grandi attori in campo di HTTP sono spariti dalle discussioni e dagli incontri del gruppo di lavoro. Non voglio citare nessuna compagnia in particolare o alcun nome di prodotto ma è chiaro come alcuni protagonisti dell'Internet di oggi sembrino essere convinti che la IETF se la caverà da sola, senza bisogno che tali grosse compagnie siano coinvolte...
Il gruppo si chiama HTTPbis dove "bis" deriva dall'avverbio latino significante "secondo" Latin adverb for two. Bis è comunemente usato in contesto IETF come suffisso o parte del nome per un aggiornamento o una review di una specifica; in tal caso si tratta dell'aggiornamento di HTTP 1.1.
SPDY è un protocollo sviluppato e diffuso da Google. Lo hanno sicuramente sviluppato in maniera aperta, invitando chiunque a partecipare; era ovvio sin dall'inizio che Google ne avrebbe tratto beneficio, mantenendo il controllo su una popolare implementazione di browser e su una significativa popolazione di server con servizi arcinoti.
SPDY aveva gia ampiamente provato la sua validità concettuale nel momento in cui HTTPbis decise che fosse tempo di iniziare a lavorare su http2. SPDY ha mostrato come fosse possibile innovare internet, c'erano statistiche e numeri a riprova delle sue ottime performances. Il lavoro su http2 è cominciato con la draft di SPDY/3 che di fatto è stata trasformata nella draft-00 di http2 con un colpo di sed/replace.


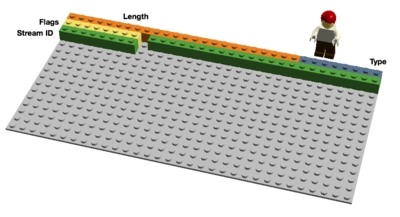
Quindi, come appariranno le cose quando http2 sarà adottato ? Sarà mai usato ?
http2 non è ancora ne distribuito ne adodatto. Non possiamo ancora dire come le cose evolveranno. Abbiamo visto come SPDY sia stato messo in campo; possiamo solo fare qualche ipotesi basata su quella ed altre esperienze passate, ed sugli esperimenti in corso.
http2 riduce il numero di round-trip ed evita definitivamente l'eterno dilemma del "head-of-line blocking" attraverso l'utilizzo di multiplexing e fast-discarding degli stream non necessari.
Permette un vasto ammontare di streams paralleli, numero ampiamente sufficiente anche per il sito più "sharded" (parallelizzato) del momento.
Utilizzando correttamente le priorità sugli streams il client sarà in grado di scaricare i dati importanti prima dei dati quelli meno utili. Visto tutto ciò, sono sicuro che beneficieremo di siti più reattivi, che si caricano in tempi più rapidi. Mettiamola così: una miglior esperienza del web.
Quanto celere sarà questo miglioramento, staremo a vedere, non penso si possa ancora dire. Per prima cosa, la tecnologia è ancora in fase di lancio e non si sono ancora visti client/server che implementino a dovere questa tecnologia per sfruttarne tutte le potenzialità.
Nel corso degli anni, gli sviluppatori e gli IDE si sono riuniti a formare una immensa cassetta degli attrezzi piena di utensili e trucchi per circuire HTTP 1.1; come ricorderete, ne ho menzionati alcuni all'inizio di questo documento come giustificazioni per passare a http2.
Molti workaround oggi utilizzati da tool e sviluppatori in maniera automagica, avranno probabilmente effetti negativi sulle performance di http2, o perlomeno non aiuteranno a sfuttare i superpoteri di http2. Spriting e inlining non dovrebbero più essere utilizzati in http2. Anche lo sharding a suo modo dovra essere abbandonato in favore di un minor numero di singole connessioni.
Il problema risiede nel fatto che i siti web devono essere mantenuti ed evoluti di continuo, a breve termine; garantire performance adeguate per entrambi gli utilizzatori di HTTP 1.1 e http2 sarà una grande sfida per gli sviluppatori che vorranno evitare di offrire due frontend separati.
Anche solo per questi motivi, sospetto che passerà un pò di tempo prima che tutti possiamo apprezzare il pieno potenziale di http2, dappertutto.
Provare a documentare le implementazioni specifiche in un documento come questo sarebbe un impresa futile e prona al fallimento, tale documento diventerebbe desueto in breve tempo. Cercherò piuttosto di spiegare la situazione in termini più ampii, oltre ad indirizzare i lettori verso il sito di http2, .
Un grande numero di implementazioni hanno preso vita fin dall'inizio ed altre si sono aggiunte durante il lavoro di definizione di http2. Al momento attuale, sono citate più di 40 implementazioni, la maggior parte delle quali rispetta la versione finale delle specifiche.
Firefox è il browser che più di altri ha seguito da vicino i rapidi sviluppi delle ultimissime drafts, Twitter è rimasta al passo offrendo i suoi servizi su http2. Google ha iniziato verso Aprile 2014 ad offrire supporto per http2 su un numero limitato di server di test e a partire da Maggio 2014 ha fornito supporto per http2 nelle versioni per sviluppatori Chrome. Microsoft da parte sua ha dato una dimostrazione del supporto http2 in Internet Explorer. Safari (su iOS 9 e Mac OS X El Capitan) e Opera hanno entrambi annunciato supporto per http2 in future versioni.
Esistono gia molte implementazioni di server http2.
Il popolare Nginx offre supporto per http2 gia dalla rilasciata il 22 Settembre 2015 (dove rimpiazza il modulo SPDY, impedendo l'utilizzo contemporaneo di entrambi all'interno della stessa istanza.
Apache's httpd server has a http2 module since 2.4.17 which was released on October 9, 2015.
, , , e hanno tutti dimostrato di essere capaci di gestire richieste http2.
curl e libcurl supportano http2 non-sicuro (testuale) e la versione TLS servendosi di una delle svrariate librerie TLS disponibili.
Anche Wireshark supporta http2; strumento professionale per l'analisi del traffico di rete http2.
Durante lo sviluppo di questo protocollo, il dibattito ha preso pieghe diverse, avanti e indietro rispetto a determinate posizioni intellettuali, è ovvio che a detta di alcune persone questo protocollo abbia fatto davvero una brutta fine. Vorrei citare alcune delle critiche più frequenti e rispondere tono su tono:
Vi sono anche varianti in cui si afferma che il mondo diventa sempre più incline al controllo globale di Google. Ciò non è assolutamente vero. Il protocollo è stato sviluppato in seno alla IETF nello stesso modo in cui altri protocolli hanno visto luce durante gli ultimi 30 anni. Ciononostante, riconosciamo e prendiamo atto che l'incredibile lavoro di Google su SPDY non solo ha dimostrato come sia possible diffondere un nuovo protocollo in maniera "non-standard" ma ha anche fornito i numeri per valutarne futuri guadagni in prestazioni.
Google ha pubblicamente che rimuoverà il supporto per SPDY e NPN su Chrome nel 2016, incoraggiando la migrazione a http2.
This is sort of true. One of the primary drivers behind the http2 development is the fixing of HTTP pipelining. If your use case originally didn't have any need for pipelining then chances are http2 won't do a lot of good for you. It certainly isn't the only improvement in the protocol but a big one.
As soon as services start realizing the full power and abilities the multiplexed streams over a single connection brings, I suspect we will see more application use of http2.
Small REST APIs and simpler programmatic uses of HTTP 1.x may not find the step to http2 to offer very big benefits. But also, there should be very few downsides with http2 for most users.
Not at all. The multiplexing capabilities will greatly help to improve the experience for high latency connections that smaller sites without wide geographical distributions often offer. Large sites are already very often faster and more distributed with shorter round-trip times to users.
This can be true to some extent. The TLS handshake does add a little extra, but there are existing and ongoing efforts on reducing the necessary round-trips even more for TLS. The overhead for doing TLS over the wire instead of plain-text is not insignificant and clearly notable so more CPU and power will be spent on the same traffic pattern as a non-secure protocol. How much and what impact it will have is a subject of opinions and measurements. See for example for one source of info.
Telecom and other network operators, for example in the ATIS Open Web Alliance, say that they to offer caching, compression and other techniques necessary to provide a fast web experience over satellite, in airplanes and similar. http2 does not make TLS use mandatory so we shouldn't conflate the terms.
Many Internet users have expressed a preference for TLS to be used more widely and we should help to protect users' privacy.
Experiments have also shown that by using TLS, there is a higher degree of success than when implementing new plain-text protocols over port 80 as there are just too many middle boxes out in the world that interfere with what they would think is HTTP 1.1 if it goes over port 80 and might look like HTTP at times.
Finally, thanks to http2's multiplexed streams over a single connection, normal browser use cases still could end up doing substantially fewer TLS handshakes and thus perform faster than HTTPS would when still using HTTP 1.1.
Si, amiamo poter vedere i protocolli cleartext in azione, rende più facile la diagnostica. Però tali protocolli sono più proni all'errore, oltre ad aprire le porte ad errori di parsing.
Se davvero non sopporti i protocolli binarii, allora non hai mai interagito con TLS e compressione in HTTP 1.x, pratica che peraltro è in atto da lunghissimo tempo.
Questo è ovviamente oggetto di dibattiti e discussioni animate riguardo la definizione di "velocità", benchè svariati test eseguiti al tempo di SPDY abbiano gia mostrato che il tempo di "page load" sia deavvero minore (per esempio dell'Università di Washington e di Hervé Servy) e chiaramente tali esperimenti sono stati ripetuti su http2.
Aspetto con ansia che altri risultati ed esperimenti simili vengano pubblicati. Un sembra indicare che HTTP/2 stia mantenendo le proprie promesse.
Davvero, questa la vostra critica ? Gli strati non sono sacri e intoccabili pilastri di una religione globale. Se ci siamo trovati a passare per zone d'ombra durante lo sviluppo di http2, è sempre stato nell'interesse e allo scopo di creare un protocollo efficace e stabile, a partire dai vinvoli iniziali.
Vero. Con l'obiettivo preciso di mantenere i paradigmi HTTP/1.1 molte delle antiche features dovevano rimanere incluse, tali quali gli header più comuni, che a loro volta spesso includono fantomatici cookies, autorizzazioni e tanto altro. Il vantaggio nel mantenere questi paradigmi è che ora abbiamo un protocollo che distribuibile e integrabile senza bisogno di un eccessivo ammontare di aggiornamenti, evitando di riscrivere le parti fondamentali o di rimpiazzarle ex-novo. http2 è di fatto solo un nuovo strato di incapsulazione, di framing.
È troppo presto per dirlo con certezza, ma posso indovinare e stimare che è quello che succederà.
I detrattori diranno “guarda quanto bene ha fatto IPv6” portandolo come esempio di un nuovo protocollo per il quale ci sono voluti decenni prima che si iniziasse a vederlo implementato massivamente. Ebbene, http2 non è un nuovo IPv6. È un protocollo basato su TCP che fa leva sullo straodinario meccanismo di Update HTTP, sui numeri di porta, su TLS, etc. Non necessiterà di alcuna modifica a router o firewall.
Con il suo SPDY, Google ha dimostrato al mondo come un nuovo protocollo possa essere sviluppato e distribuito a browser e webservices attraverso implementazioni multiple, in un tempo tutto sommato breve. Mentre l'ammontare di server che offrono SPDY su Internet è nel range dell'1%, l'ammontare di dati con i quali questi server hanno a che fare è ben maggiore. Alcuni dei più popolari e visitati siti propongono SPDY gia ad oggi.
Direi che http2, basato sullo stesso principio e paradigma di SPDY, si diffonderà ancora di più per via del fatto che tale protocollo proviene dalla IETF. Il deploy di SPDY ha sempre sofferto dello stigma, essendo esso “un protocollo di Google”.
Vi sono svariati "grandi browser" dietro la distribuzione di http2. Rappresentati di Firefox, Chrome, Safari, Internet Explorer e Opera hanno espresso la volontà di includere http2 nei proprii broswer; essi hanni dimostrato implementazioni funzionanti.
I più grandi portali e operatori del web -fra cui Google, Twitter e Facebook- sono interessati ad offrire http2 quanto prima. Speriamo di vedere questo supporto arrivare anche alle piattaforme server tipo Apache e nginx. Un nuovo velocissimo server HTTP con supporto http2 che mostra un enorme potenziale è H2o.
Molte delle più famose case produttrici di proxy hanno annunciato di voler supportare http2, fra cui HAProxy, Squid e Varnish.
Durante il corso del 2015, il traffico http2 è aumentato. A inizio Settembre il tasso di utilizzazione di Firefox 40 era al 13% su tutto il traffico HTTP e 27% su tutto il traffico HTTPS, mentre verso Google circa il 18% di richieste entranti sono in HTTP/2. Bisogna notare che allo stesso tempo Google è in procinto di sperimentare altri protocolli (vedi QUIC in 12.1) il che abbassa in qualche modo il tasso di connessioni http2 globali.
